R编程中的关联规则挖掘
R 语言中的关联规则挖掘是一种无监督非线性算法,用于揭示项目如何相互关联。在其中,频繁挖掘显示了哪些项目一起出现在事务或关系中。它主要用于零售商、杂货店和拥有大型交易数据库的在线市场。当任何在线社交媒体、市场和电子商务网站使用推荐引擎知道您接下来要购买什么时,同样的方式。您在查看订单时获得的关于项目或变量的建议是因为关联规则挖掘基于过去的客户数据。衡量关联的常用方法有以下三种:
- 支持
- 信心
- 电梯
理论
在关联规则挖掘中,Support、Confidence 和 Lift 度量关联。
支持表示项目的受欢迎程度,以出现项目集的交易比例来衡量。
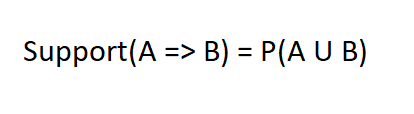
置信度表示购买商品 X 时购买商品 Y 的可能性有多大,表示为 {X -> Y}。
因此,它是通过与项目 X 的交易比例来衡量的,其中项目 Y 也出现。信心可能会歪曲联想的重要性。
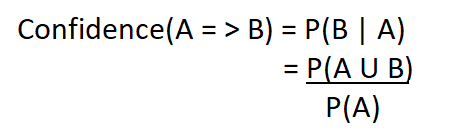
Lift表示当商品 X 被购买时,商品 Y 被购买的可能性有多大,同时控制了商品 Y 的受欢迎程度。
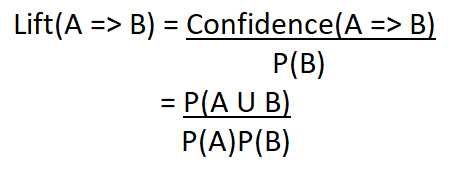
Apriori 算法也用于关联规则挖掘,用于发现事务数据库中的频繁项集。它由 Agrawal & Srikant 于 1993 年提出。
例子:
一位客户与您进行了 4 笔交易。在第一笔交易中,她买了 1 个苹果、1 杯啤酒、1 份米饭和 1 只鸡。在第二笔交易中,她买了 1 个苹果、1 杯啤酒、1 份大米。在第三次交易中,她只买了 1 个苹果,1 杯啤酒。在第四次交易中,她买了 1 个苹果和 1 个橙子。
Support(Apple) = 4/4
So, Support of {Apple} is 4 out of 4 or 100%
Confidence(Apple -> Beer) = Support(Apple, Beer)/Support(Apple)
= (3/4)/(4/4)
= 3/4
So, Confidence of {Apple -> Beer} is 3 out of 4 or 75%
Lift(Beer -> Rice) = Support(Beer, Rice)/(Support(Beer) * Support(Rice))
= (2/4)/(3/4) * (2/4)
= 1.33
So, Lift value is greater than 1 implies Rice is likely to be bought if Beer is bought.
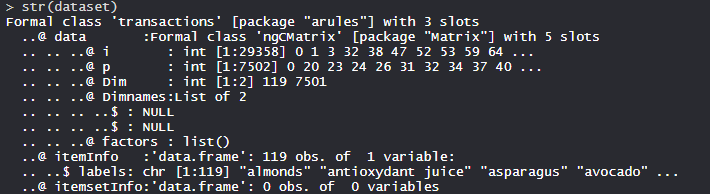
数据集
Market Basket数据集由 15010 个带有日期、时间、交易和项目特征或列的观察组成。日期变量或列的范围从 30/10/2016 到 09/04/2017。时间是表示时间的分类变量。交易是一个量化变量,有助于区分交易。项目是与产品链接的分类变量。
# Loading data
dataset = read.transactions('Market_Basket_Optimisation.csv',
sep = ', ', rm.duplicates = TRUE)
# Structure
str(dataset)
对数据集进行关联规则挖掘
在包含 15010 个观测值的数据集上使用关联规则挖掘算法。
# Installing Packages
install.packages("arules")
install.packages("arulesViz")
# Loading package
library(arules)
library(arulesViz)
# Fitting model
# Training Apriori on the dataset
set.seed = 220 # Setting seed
associa_rules = apriori(data = dataset,
parameter = list(support = 0.004,
confidence = 0.2))
# Plot
itemFrequencyPlot(dataset, topN = 10)
# Visualising the results
inspect(sort(associa_rules, by = 'lift')[1:10])
plot(associa_rules, method = "graph",
measure = "confidence", shading = "lift")
输出:
- 模型关联规则:
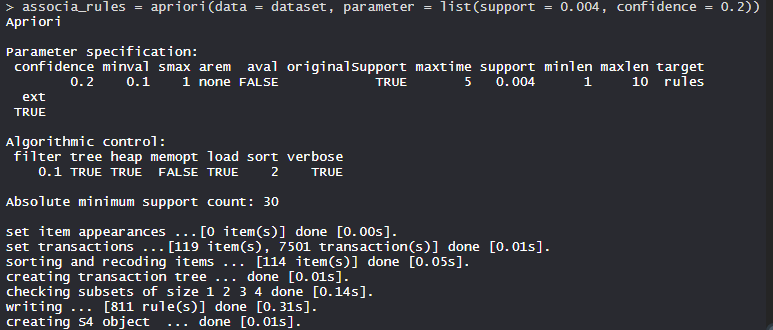
模型最小长度为 1,最大长度为 10,绝对支持数为 30 的目标规则。
- 项目频率图:
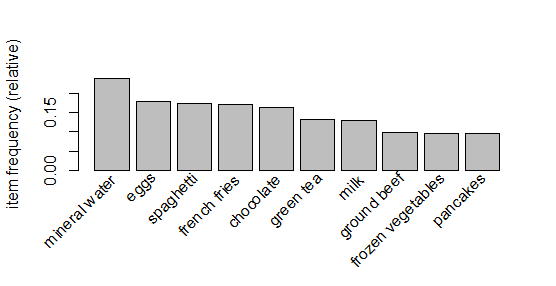
因此,矿泉水是最畅销的产品,其次是鸡蛋、意大利面、炸薯条等。
- 可视化模型:
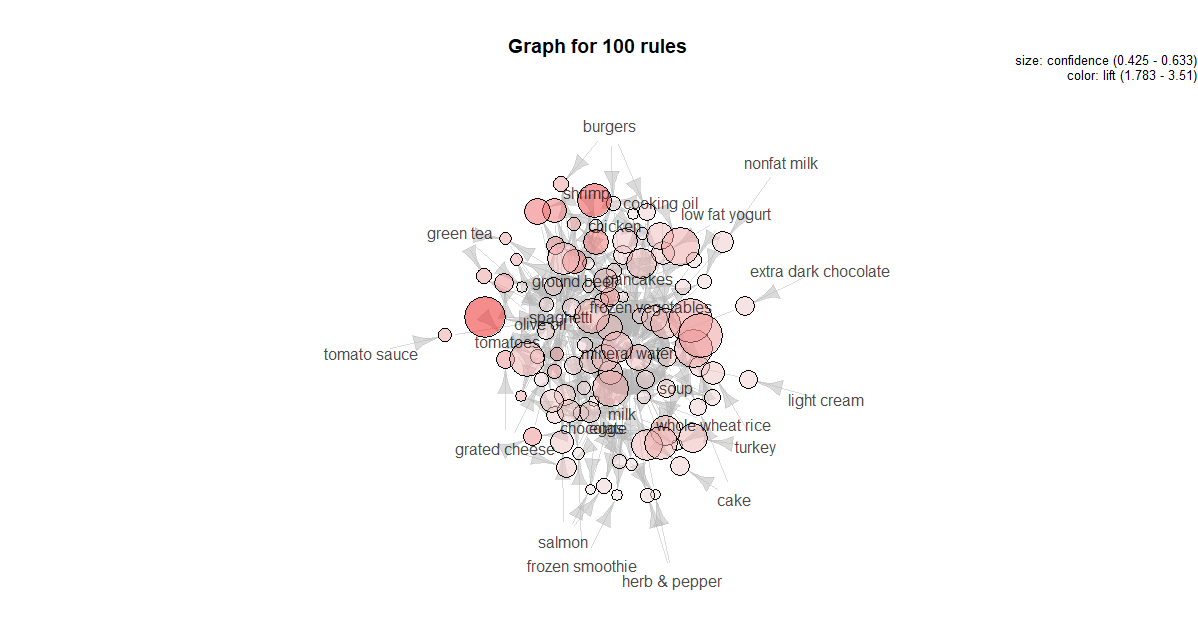
因此,将显示 100 的图形。
因此,关联规则挖掘被广泛应用于电子商务、在线市场和社交媒体网站等推荐系统中,并在业界得到广泛应用。