在Python中测量文档相似度
顾名思义,文档相似度决定了两个给定文档的相似程度。 “文档”是指字符串的集合。例如,一篇文章或一个 .txt 文件。许多组织使用这种文档相似性原则来检查抄袭。许多考试机构也使用它来检查学生是否作弊。因此,了解所有这些是如何工作的非常重要且有趣。
通过计算文档距离来计算文档相似度。文档距离是将单词(文档)视为向量并计算为两个给定文档向量之间的角度的概念。文档向量是给定文档中单词出现的频率。让我们看一个例子:
假设我们有两个文档D1和D2 :
D1 :“这是个极客”
D2 :“这是个极客”
这两份文件中的相似词就变成了:
"This a geek"如果我们通过在 3 轴几何中采用 D1、D2 和类似词将其作为向量进行 3-D 表示,那么我们得到:
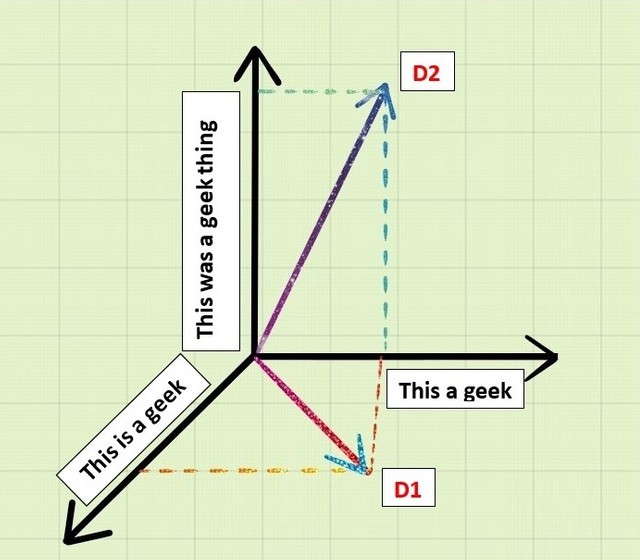
现在如果我们取D1和D2的点积,
D1.D2 = "This"."This"+"is"."was"+"a"."a"+"geek"."geek"+"thing".0D1.D2 = 1+0+1+1+0D1.D2 = 3现在我们知道如何计算这些文档的点积,我们现在可以计算文档向量之间的角度:
cos d = D1.D2/|D1||D2|这里 d 是文档距离。它的值范围从 0 度到 90 度。其中 0 度表示两个文档完全相同,90 度表示两个文档非常不同。
现在我们知道了文档相似度和文档距离,让我们看一个Python程序来计算它们:
文档相似度程序:
我们确认文档相似性的算法将包括三个基本步骤:
- 用单词拆分文档。
- 计算词频。
- 计算文档向量的点积。
第一步,我们将首先使用.read()方法打开和读取文件的内容。当我们阅读内容时,我们会将它们分成一个列表。接下来,我们将计算文件中读取的词频列表。因此,计算每个单词的出现次数,并按字母顺序对列表进行排序。
import math
import string
import sys
# reading the text file
# This functio will return a
# list of the lines of text
# in the file.
def read_file(filename):
try:
with open(filename, 'r') as f:
data = f.read()
return data
except IOError:
print("Error opening or reading input file: ", filename)
sys.exit()
# splitting the text lines into words
# translation table is a global variable
# mapping upper case to lower case and
# punctuation to spaces
translation_table = str.maketrans(string.punctuation+string.ascii_uppercase,
" "*len(string.punctuation)+string.ascii_lowercase)
# returns a list of the words
# in the file
def get_words_from_line_list(text):
text = text.translate(translation_table)
word_list = text.split()
return word_list
现在我们有了单词列表,我们现在将计算单词出现的频率。
# counts frequency of each word
# returns a dictionary which maps
# the words to their frequency.
def count_frequency(word_list):
D = {}
for new_word in word_list:
if new_word in D:
D[new_word] = D[new_word] + 1
else:
D[new_word] = 1
return D
# returns dictionary of (word, frequency)
# pairs from the previous dictionary.
def word_frequencies_for_file(filename):
line_list = read_file(filename)
word_list = get_words_from_line_list(line_list)
freq_mapping = count_frequency(word_list)
print("File", filename, ":", )
print(len(line_list), "lines, ", )
print(len(word_list), "words, ", )
print(len(freq_mapping), "distinct words")
return freq_mapping
最后,我们将计算点积以给出文档距离。
# returns the dot product of two documents
def dotProduct(D1, D2):
Sum = 0.0
for key in D1:
if key in D2:
Sum += (D1[key] * D2[key])
return Sum
# returns the angle in radians
# between document vectors
def vector_angle(D1, D2):
numerator = dotProduct(D1, D2)
denominator = math.sqrt(dotProduct(D1, D1)*dotProduct(D2, D2))
return math.acos(numerator / denominator)
就这样!是时候看看文档相似度函数了:
def documentSimilarity(filename_1, filename_2):
# filename_1 = sys.argv[1]
# filename_2 = sys.argv[2]
sorted_word_list_1 = word_frequencies_for_file(filename_1)
sorted_word_list_2 = word_frequencies_for_file(filename_2)
distance = vector_angle(sorted_word_list_1, sorted_word_list_2)
print("The distance between the documents is: % 0.6f (radians)"% distance)
这是完整的源代码。
import math
import string
import sys
# reading the text file
# This functio will return a
# list of the lines of text
# in the file.
def read_file(filename):
try:
with open(filename, 'r') as f:
data = f.read()
return data
except IOError:
print("Error opening or reading input file: ", filename)
sys.exit()
# splitting the text lines into words
# translation table is a global variable
# mapping upper case to lower case and
# punctuation to spaces
translation_table = str.maketrans(string.punctuation+string.ascii_uppercase,
" "*len(string.punctuation)+string.ascii_lowercase)
# returns a list of the words
# in the file
def get_words_from_line_list(text):
text = text.translate(translation_table)
word_list = text.split()
return word_list
# counts frequency of each word
# returns a dictionary which maps
# the words to their frequency.
def count_frequency(word_list):
D = {}
for new_word in word_list:
if new_word in D:
D[new_word] = D[new_word] + 1
else:
D[new_word] = 1
return D
# returns dictionary of (word, frequency)
# pairs from the previous dictionary.
def word_frequencies_for_file(filename):
line_list = read_file(filename)
word_list = get_words_from_line_list(line_list)
freq_mapping = count_frequency(word_list)
print("File", filename, ":", )
print(len(line_list), "lines, ", )
print(len(word_list), "words, ", )
print(len(freq_mapping), "distinct words")
return freq_mapping
# returns the dot product of two documents
def dotProduct(D1, D2):
Sum = 0.0
for key in D1:
if key in D2:
Sum += (D1[key] * D2[key])
return Sum
# returns the angle in radians
# between document vectors
def vector_angle(D1, D2):
numerator = dotProduct(D1, D2)
denominator = math.sqrt(dotProduct(D1, D1)*dotProduct(D2, D2))
return math.acos(numerator / denominator)
def documentSimilarity(filename_1, filename_2):
# filename_1 = sys.argv[1]
# filename_2 = sys.argv[2]
sorted_word_list_1 = word_frequencies_for_file(filename_1)
sorted_word_list_2 = word_frequencies_for_file(filename_2)
distance = vector_angle(sorted_word_list_1, sorted_word_list_2)
print("The distance between the documents is: % 0.6f (radians)"% distance)
# Driver code
documentSimilarity('GFG.txt', 'file.txt')
输出:
File GFG.txt :
15 lines,
4 words,
4 distinct words
File file.txt :
22 lines,
5 words,
5 distinct words
The distance between the documents is: 0.835482 (radians)