Python|更改 Pandas DataFrame 中的列名和行索引
给定一个 Pandas DataFrame,让我们看看如何更改其列名和行索引。
关于 Pandas 数据框
Pandas DataFrame 是用于存储数据的矩形网格。当存储在 dataFrame 中时,很容易可视化和处理数据。
- 它由行和列组成。
- 每行是某个实例的度量,而列是一个向量,其中包含某些特定属性/变量的数据。
- 每个数据框列在任何特定列中都有同质数据,但数据框行可以在任何特定行中包含同质或异构数据。
- 与二维数组不同,pandas 数据框轴被标记。
Pandas Dataframe 类型有两个属性,称为“列”和“索引”,可用于更改列名和行索引。
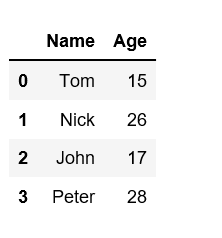
使用字典创建 DataFrame。
# first import the libraries
import pandas as pd
# Create a dataFrame using dictionary
df=pd.DataFrame({"Name":['Tom','Nick','John','Peter'],
"Age":[15,26,17,28]})
# Creates a dataFrame with
# 2 columns and 4 rows
df
- 方法 #1:使用
df.columns和df.index属性更改列名和行索引。为了更改列名,我们提供了一个Python列表,其中包含列
df.columns= ['First_col', 'Second_col', 'Third_col', .....]。
为了更改行索引,我们还为其提供了一个Python列表df.index=['row1', 'row2', 'row3', ......]。# Let's rename already created dataFrame. # Check the current column names # using "columns" attribute. # df.columns # Change the column names df.columns =['Col_1', 'Col_2'] # Change the row indexes df.index = ['Row_1', 'Row_2', 'Row_3', 'Row_4'] # printing the data frame df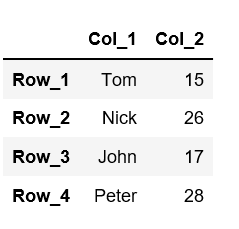
- 方法 #2:使用带有字典的
rename()函数来更改单个列# let's change the first column name # from "A" to "a" using rename() function df = df.rename(columns = {"Col_1":"Mod_col"}) df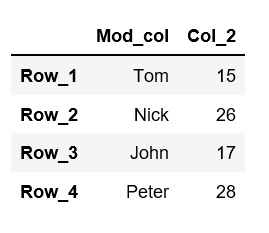
同时更改多个列名 –
# We can change multiple column names by # passing a dictionary of old names and # new names, to the rename() function. df = df.rename({"Mod_col":"Col_1","B":"Col_2"}, axis='columns') df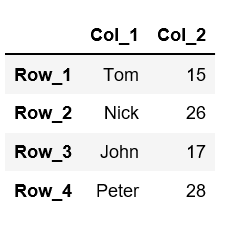
- 方法 #3:使用 Lambda函数重命名列。
lambda函数是一个小型匿名函数,它可以接受任意数量的参数,但只能有一个表达式。使用 lambda函数,我们可以一次修改所有列名。让我们使用 lambda函数在每个列名的末尾添加“x”
df = df.rename(columns=lambda x: x+'x') # this will modify all the column names df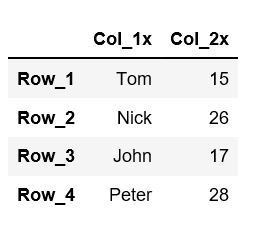
- 方法 #4:使用
values属性重命名列。我们可以直接在要更改名称的列上使用 values 属性。
df.columns.values[1] = 'Student_Age' # this will modify the name of the first column df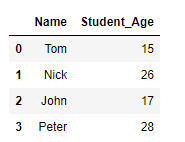
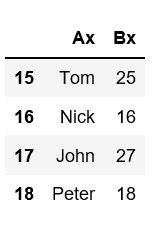
让我们使用 Lambda函数更改行索引。
# To change the row indexes df = pd.DataFrame({"A":['Tom','Nick','John','Peter'], "B":[25,16,27,18]}) # this will increase the row index value by 10 for each row df = df.rename(index = lambda x: x + 10) df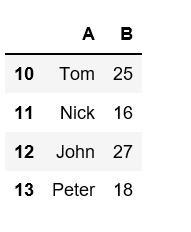
现在,如果我们想同时更改行索引和列名,那么可以使用
rename()函数并同时传递列和索引属性作为参数来实现。df = df.rename(index = lambda x: x + 5, columns = lambda x: x +'x') # increase all the row index label by value 5 # append a value 'x' at the end of each column name. df