Pandas Dataframe 中的重置索引
让我们讨论如何在 Pandas DataFrame 中重置索引。通常我们从 Pandas 中的巨大数据框开始,在操作/过滤数据框之后,我们最终会得到更小的数据框。
当我们查看较小的数据帧时,它可能仍带有原始数据帧的行索引。如果原始索引是numbers ,现在我们有不连续的索引。好吧,pandas 有reset_index()函数。因此,要将索引重置为从 0 开始的默认整数索引,我们可以简单地使用reset_index()函数。
因此,让我们看看我们可以重置 DataFrame 索引的不同方法。
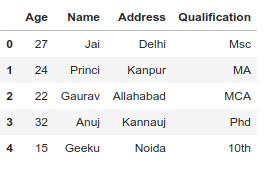
首先查看原始 DataFrame。
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th'] }
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
df
输出: 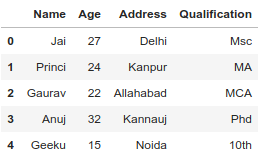
示例 #1:在不删除默认索引的情况下创建自己的索引。
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th'] }
index = {'a', 'b', 'c', 'd', 'e'}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data, index)
# Make Own Index as index
# In this case default index is exist
df.reset_index(inplace = True)
df
输出: 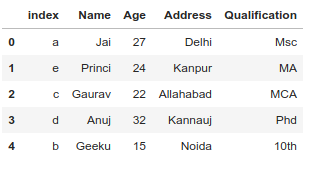 示例 #2:制作自己的索引并删除默认索引。
示例 #2:制作自己的索引并删除默认索引。
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th'] }
# Create own index
index = {'a', 'b', 'c', 'd', 'e'}
# Convert the dictionary into DataFrame
# Make Own Index and Removing Default index
df = pd.DataFrame(data, index)
df
输出: 
示例 3:重置自己的索引,并将默认索引设为索引。
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th'] }
# Create own index
index = {'a', 'b', 'c', 'd', 'e'}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data, index)
# remove own index with default index
df.reset_index(inplace = True, drop = True)
df
输出:  示例 #4:使用删除默认索引将一列数据框作为索引。
示例 #4:使用删除默认索引将一列数据框作为索引。
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th'] }
# Create own index
index = {'a', 'b', 'c', 'd', 'e'}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data, index)
# set index any column of our DF and
# remove default index
df.set_index(['Age'], inplace = True)
df
输出:  示例 5:将一列数据框作为索引而不删除默认索引。
示例 5:将一列数据框作为索引而不删除默认索引。
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th'] }
# Create own index
index = {'a', 'b', 'c', 'd', 'e'}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data, index)
# set any column as index
# Here we set age column as index
df.set_index(['Age'], inplace = True)
# reset index without removing default index
df.reset_index(level =['Age'], inplace = True)
df
输出: