- PyTorch线性回归(1)
- PyTorch-线性回归
- 使用PyTorch进行线性回归
- 使用PyTorch进行线性回归(1)
- R线性回归(1)
- R-线性回归(1)
- 线性回归 (1)
- R-线性回归
- R线性回归
- python中的线性回归(1)
- Python线性回归(1)
- Python线性回归
- python代码示例中的线性回归
- 线性回归 - Javascript 代码示例
- 线性回归 - 无论代码示例
- 回归算法-线性回归(1)
- 回归算法-线性回归
- python 线性回归 - Python (1)
- TensorFlow中的线性回归
- TensorFlow-线性回归
- TensorFlow-线性回归(1)
- TensorFlow中的线性回归(1)
- Python中的单变量线性回归
- Python中的单变量线性回归(1)
- python 线性回归 - Python 代码示例
- 线性回归(Python实现)
- 线性回归(Python实现)
- 线性回归(Python实现)(1)
- 统计-线性回归
📅 最后修改于: 2020-11-10 09:54:20 🧑 作者: Mango
线性回归
线性回归是一种通过最小化距离来找到因变量和自变量之间的线性关系的方法。
线性回归是一种有监督的机器学习方法。该方法用于订单离散类别的分类。在本节中,我们将了解如何建立一个模型,用户可以通过该模型来预测因变量和自变量之间的关系。
简单来说,我们可以说两个变量之间的关系(即独立或因变量)被称为线性。假设Y为因变量,X为自变量,则这两个变量的线性回归关系为
Y = AX + b
- A是斜率。
- b是y截距。
初始状态
最终状态
对于创建或学习基本线性模型,必须理解三个基本概念。
1.模型类
编写所有代码并在需要时编写所有函数是非常典型的,这不是我们的动机。
编写数字优化库总比编写所有代码和函数总要好,但是如果我们在预先编写的库之上构建它来完成任务,那么业务价值也可以增加。为此,我们使用PyTorch的nn包的实现。为此,我们首先要创建一个图层。
线性层使用
每个线性模块都会计算输入的输出,并且对于权重和偏差,它会保留其内部张量。
还有其他几个标准模块。我们将使用模型类格式,它具有两个主要方法,如下所示:
- 初始化:用于定义线性模块。
- 前瞻:借助前瞻方法,在进行预测的基础上,我们将训练线性回归模型
2.优化器
优化器是PyTorch中的重要概念之一。它用于优化我们的权重以使我们的模型适合数据集。有几种优化算法,例如梯度下降和反向传播,可以优化我们的权重值并最适合我们的模型。
通过torch.optim包可实现各种优化算法。要使用torch.optim,您必须构造一个优化器对象,该对象将根据计算机的梯度更新参数并保持当前状态。对象创建如下:
Optimizer=optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
Optimizer=optim.Adam([var1, var2], lr=0.0001))
所有优化器均实现step()方法,该方法将更新参数。有两种使用方式
1)Optimizer.step()
这是一种非常简单的方法,并且得到许多优化程序的支持。在使用向后()方法计算梯度之后,我们可以调用optimizer.step()函数。
例:
for input, target in dataset:
optimizer.zero_grad()
output=model(input)
loss=loss_fn(output, target)
loss.backward()
optimizer.step()
2)Optimizer.step(关闭)
有一些优化算法(例如LBFGS),并且“共轭梯度”需要多次重新评估该函数,因此我们必须将其传递给闭包以允许他们重新计算模型。
例:
for input, target in dataset:
def closure():
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
return loss
optimizer.step(closure)
标准
标准是我们的损失函数,用于发现损失。此函数可从手电筒nn模块中使用。
例:
criterion = torch.nn.MSELoss(size_average = False)
所需的功能和对象
- 进口火炬
- 从torch.autagrad导入变量
我们需要定义一些数据,并通过以下方式将它们分配给变量
xdata=Variable(torch.Tensor([[1.0],[2.0],[3.0]]))
ydata=Variable(torch.Tensor([[2.0],[4.0],[6.0]]))
以下是为我们提供训练完整回归模型的预测的代码。这只是了解我们是如何实现的代码和函数是什么,我们来训练回归模型。
import torch
from torch.autograd import Variable
xdata = Variable(torch.Tensor([[1.0], [2.0], [3.0]]))
ydata = Variable(torch.Tensor([[2.0], [4.0], [6.0]]))
class LRM(torch.nn.Module):
def __init__(self):
super(LRM, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
ypred = self.linear(x)
return ypred
ourmodel = LRM()
criterion = torch.nn.MSELoss(size_average = False)
optimizer = torch.optim.SGD(ourmodel.parameters(), lr = 0.01)
for epoch in range(500):
predy = our_model(xdata)
loss = criterion(predy, ydata)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))
newvar = Variable(torch.Tensor([[4.0]]))
predy = ourmodel(newvar)
print("predict (after training)", 4, our_model(newvar).data[0][0])
输出:
epoch0,loss1.7771836519241333
epoch1,loss1.0423388481140137
epoch2,loss0.7115973830223083
epoch3,loss0.5608030557632446
.
.
.
.
epoch499,loss0.0003389564517419785
predict (after training) 4 tensor(7.9788)
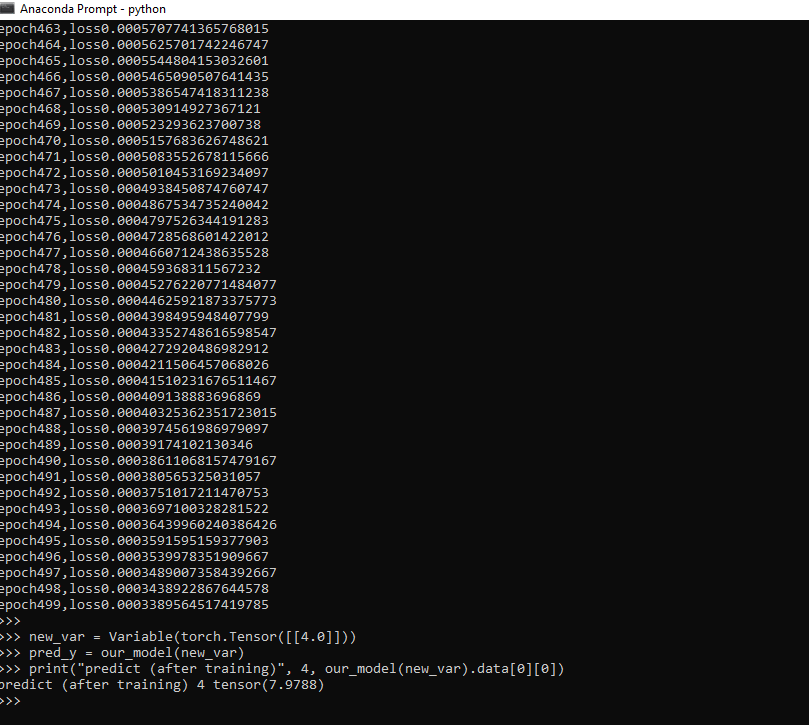
以下概念用于训练完整的回归模型
- 做出预测
- 线性类
- 定制模块
- 创建数据集
- 损失函数
- 梯度下降
- 均方误差
- 训练
以上所有要点对于理解如何训练回归模型都是必不可少的。