- 神经网络在图像识别中的实现
- 用于图像识别的卷积块(1)
- 用于图像识别的卷积块
- 图像识别中的图像转换
- Pytorch图像识别(1)
- Pytorch图像识别
- 特征和图像识别 - Python (1)
- 使用TensorFlow进行图像识别
- 使用TensorFlow进行图像识别(1)
- 特征和图像识别 - Python 代码示例
- 神经网络如何用于数据挖掘?
- PyTorch中的图像识别模型的测试
- PyTorch中的图像识别模型的测试(1)
- 神经网络如何用于 R 编程中的分类(1)
- 神经网络如何用于 R 编程中的分类
- 卷积神经网络模型的验证
- 卷积神经网络模型的验证(1)
- 神经网络如何用于 R 编程中的回归?(1)
- 神经网络如何用于 R 编程中的回归?
- 神经网络的应用
- 神经网络的应用(1)
- 神经网络的应用
- 神经网络的应用(1)
- PyTorch中的图像识别的MNIST数据集
- PyTorch中的图像识别的MNIST数据集(1)
- 神经网络如何工作 (1)
- 神经网络导入 - Python (1)
- 使用 Mobilenet 进行图像识别(1)
- 使用 Mobilenet 进行图像识别
📅 最后修改于: 2020-11-11 01:00:37 🧑 作者: Mango
图像识别的神经网络验证
在训练部分,我们在MNIST数据集(无尽数据集)上训练了我们的模型,它似乎达到了合理的损失和准确性。如果模型可以利用它所学到的知识并将其自身概括为新数据,那么它将是其性能的真实证明。这将通过以下步骤完成:
步骤1:
我们将在训练部分创建的训练数据集的帮助下创建验证集。在这个时候,我们将训练等于false设置为:
validation_dataset=datasets.MNIST(root='./data',train=False,download=True,transform=transform1)
第2步:
现在,就像我们在训练部分中声明训练加载器一样,我们将在验证部分中声明验证加载器。验证加载程序的创建方式也与创建训练加载程序的方式相同,但是这次我们传递的是训练加载程序,而不是训练数据集,并且我们将shuffle设置为false,因为我们不会训练验证数据。无需将其改组,因为它仅用于测试目的。
validation_loader=torch.utils.data.DataLoader(dataset=validation_dataset,batch_size=100,shuffle=False)
第三步:
我们的下一步是分析每个时期的验证损失和准确性。为此,我们必须为丢失的验证运行和校正运行丢失创建两个列表。
val_loss_history=[]
val_correct_history=[]
第四步:
在下一步中,我们将验证模型。该模型将验证相同的纪元。在完成整个训练集的迭代以训练我们的数据之后,我们现在将迭代验证集以测试我们的数据。
我们将首先测量两件事。第一个是我们模型的性能,即多少个正确的分类。我们的模型基于验证集上的测试集来检查是否过拟合。我们将运行损失和验证的运行更正设置为:
val_loss=0.0
val_correct=0.0
步骤5:
现在,我们可以遍历我们的测试数据。因此,在else语句之后,我们将为标签和输入定义一个循环语句为:
for val_input,val_labels in validation_loader:
步骤6:
当我们遍历一批图像时,我们必须将它们展平,并且必须借助view方法来重塑它们。
注意:每个图像张量的形状分别为(1、28和28),这意味着总共784个像素。
根据神经网络的结构,我们的输入值将乘以将输入层连接到第一个隐藏层的权重矩阵。要进行这种乘法,我们必须使图像一维。我们必须将其展平为784像素的单行,而不是每个图像都是28行乘2列。
val_inputs=val_input.view(val_input.shape[0],-1)
现在,借助这些输入,我们得到的输出为
val_outputs=model(val_inputs)
步骤7:
借助输出,我们将计算总分类交叉熵损失,最终将输出与实际标签进行比较。
val_loss1=criteron(val_outputs,val_labels)
我们没有训练我们的神经网络,因此不需要调用zero_grad(),backward()或任何其他方法。并且也不再需要计算导数。在节省内存的操作范围内,我们在For循环之前使用手电筒调用no_grad()方法:
with torch.no_grad():
它将暂时将所有require grad标志设置为false。
步骤8:
现在,我们将以与计算训练损失和训练准确性相同的方式来计算验证损失和准确性:
_,val_preds=torch.max(val_outputs,1)
val_loss+=val_loss1.item()
val_correct+=torch.sum(val_preds==val_labels.data)
步骤9:
现在,我们将计算验证时间损失,其方法与计算训练时间损失的方法相同,在该方法中,我们将总运行损失除以数据集的长度。因此它将写为:
val_epoch_loss=val_loss/len(validation_loader)
val_epoch_acc=correct.float()/len(validation_loader)
val_loss_history.append(val_epoch_loss)
val_correct_history.append(epoch_acc)
步骤10:
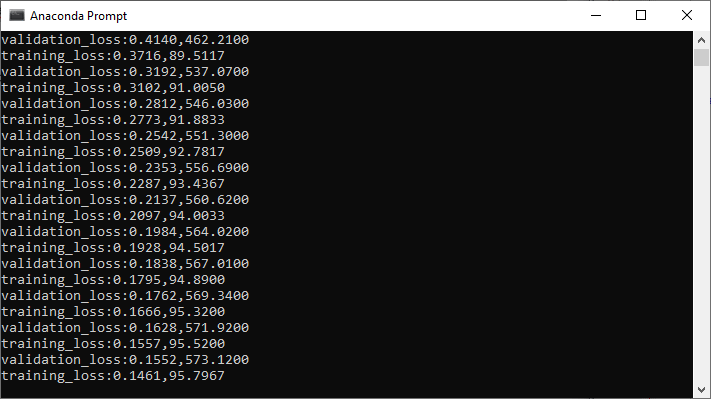
我们将验证损失和验证准确性print为:
print('validation_loss:{:.4f},{:.4f}'.format(val_epoch_loss,val_epoch_acc.item()))
步骤11:
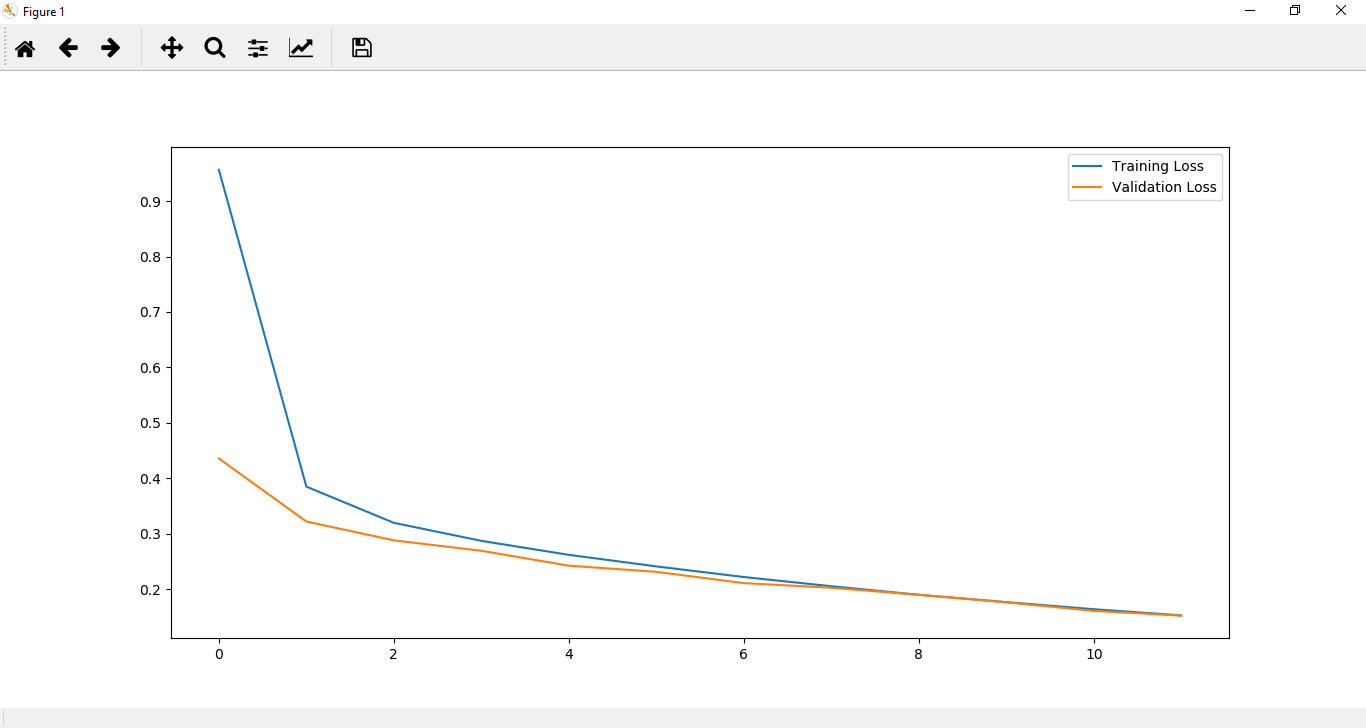
为了更好地理解,我们也不会出于可视化目的对其进行绘制。我们将其绘制为:
plt.plot(loss_history,label='Training Loss')
plt.plot(val_loss_history,label='Validation Loss')
plt.legend()
plt.show()
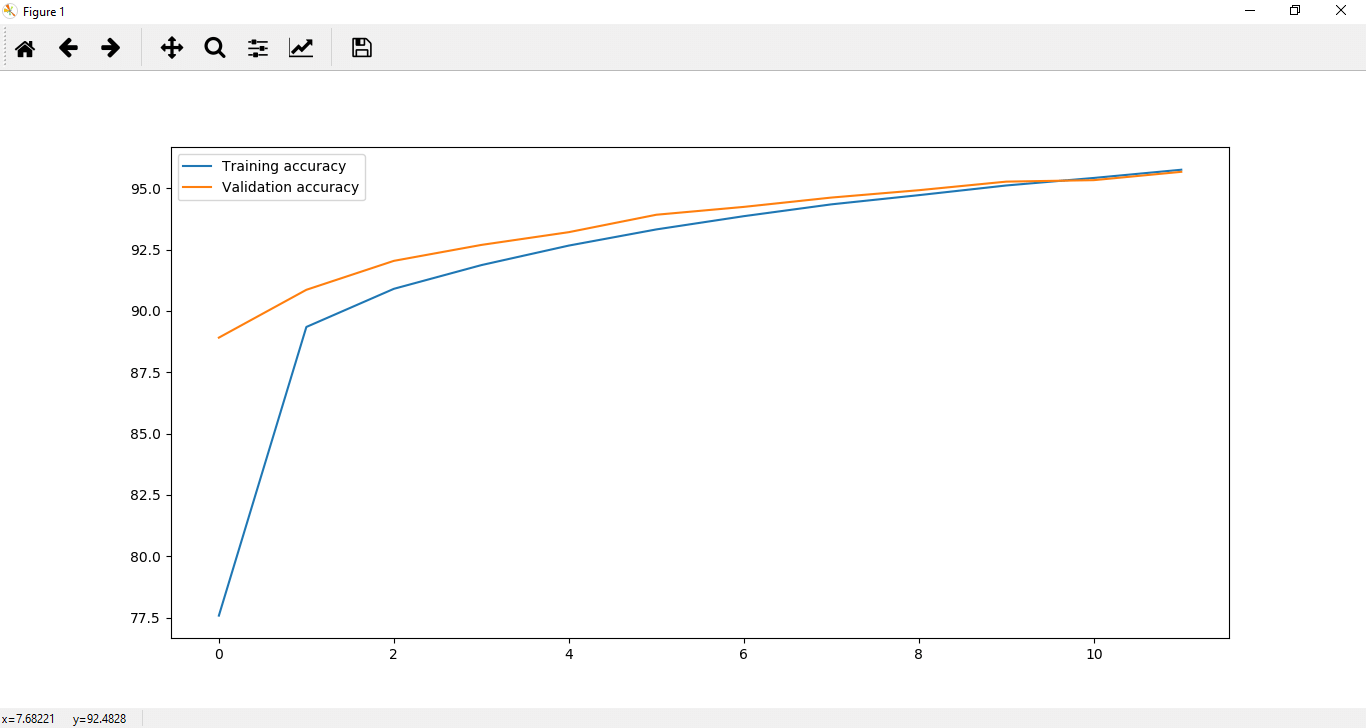
plt.plot(correct_history,label='Training accuracy')
plt.plot(val_correct_history,label='Validation accuracy')
plt.legend()
plt.show()
完整的代码
import torch
import matplotlib.pyplot as plt
import numpy as np
import torch.nn.functional as func
from torch import nn
from torchvision import datasets,transforms
transform1=transforms.Compose([transforms.Resize((28,28)),transforms.ToTensor(),transforms.Normalize((0.5,),(0.5,))])
training_dataset=datasets.MNIST(root='./data',train=True,download=True,transform=transform1)
validation_dataset=datasets.MNIST(root='./data',train=False,download=True,transform=transform1)
training_loader=torch.utils.data.DataLoader(dataset=training_dataset,batch_size=100,shuffle=True)
validation_loader=torch.utils.data.DataLoader(dataset=validation_dataset,batch_size=100,shuffle=False)
def im_convert(tensor):
image=tensor.clone().detach().numpy()
image=image.transpose(1,2,0)
print(image.shape)
image=image*(np.array((0.5,0.5,0.5))+np.array((0.5,0.5,0.5)))
image=image.clip(0,1)
return image
class classification1(nn.Module):
def __init__(self,input_layer,hidden_layer1,hidden_layer2,output_layer):
super().__init__()
self.linear1=nn.Linear(input_layer,hidden_layer1)
self.linear2=nn.Linear(hidden_layer1,hidden_layer2)
self.linear3=nn.Linear(hidden_layer2,output_layer)
def forward(self,x):
x=func.relu(self.linear1(x))
x=func.relu(self.linear2(x))
x=self.linear3(x)
return x
model=classification1(784,125,65,10)
criteron=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=0.0001)
epochs=12
loss_history=[]
correct_history=[]
val_loss_history=[]
val_correct_history=[]
for e in range(epochs):
loss=0.0
correct=0.0
val_loss=0.0
val_correct=0.0
for input,labels in training_loader:
inputs=input.view(input.shape[0],-1)
outputs=model(inputs)
loss1=criteron(outputs,labels)
optimizer.zero_grad()
loss1.backward()
optimizer.step()
_,preds=torch.max(outputs,1)
loss+=loss1.item()
correct+=torch.sum(preds==labels.data)
else:
with torch.no_grad():
for val_input,val_labels in validation_loader:
val_inputs=val_input.view(val_input.shape[0],-1)
val_outputs=model(val_inputs)
val_loss1=criteron(val_outputs,val_labels)
_,val_preds=torch.max(val_outputs,1)
val_loss+=val_loss1.item()
val_correct+=torch.sum(val_preds==val_labels.data)
epoch_loss=loss/len(training_loader)
epoch_acc=correct.float()/len(training_loader)
loss_history.append(epoch_loss)
correct_history.append(epoch_acc)
val_epoch_loss=val_loss/len(validation_loader)
val_epoch_acc=correct.float()/len(validation_loader)
val_loss_history.append(val_epoch_loss)
val_correct_history.append(epoch_acc)
print('training_loss:{:.4f},{:.4f}'.format(epoch_loss,epoch_acc.item()))
print('validation_loss:{:.4f},{:.4f}'.format(val_epoch_loss,val_epoch_acc.item()))
plt.plot(correct_history,label='Correct history ')
plt.plot(val_correct_history,label='Validation correct history')
plt.legend()
plt.show()
plt.plot(correct_history,label='Training accuracy')
plt.plot(val_correct_history,label='Validation accuracy')
plt.legend()
plt.show()