- Lucene-搜索类(1)
- Lucene-搜索类
- Lucene-索引操作
- Lucene-索引操作(1)
- Lucene-排序
- Lucene-排序(1)
- Lucene-索引类
- Lucene-索引类(1)
- Lucene.net - C# (1)
- Lucene教程(1)
- Lucene教程
- Lucene.net - C# 代码示例
- 讨论Lucene
- 讨论Lucene(1)
- Lucene-概述
- Lucene-分析(1)
- Lucene-分析
- Lucene-查询编程
- Lucene-查询编程(1)
- Lucene-环境设置(1)
- Lucene-环境设置
- Lucene-有用的资源(1)
- Lucene-有用的资源
- Lucene-首次应用(1)
- Lucene-首次应用
- C# 操作 - C# (1)
- 搜索 (1)
- Lucene-索引编制过程(1)
- Lucene-索引编制过程
📅 最后修改于: 2020-11-12 04:47:16 🧑 作者: Mango
搜索过程是Lucene提供的核心功能之一。下图说明了该过程及其用法。 IndexSearcher是搜索过程的核心组件之一。
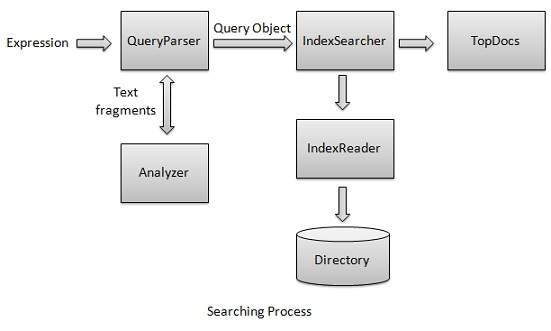
我们首先创建包含索引目录(一个或多个),然后把它传递给IndexSearcher的这将打开目录使用的IndexReader。然后,我们创建一个带有术语的查询,并通过将Query传递给搜索器来使用IndexSearcher进行搜索。 IndexSearcher返回一个TopDocs对象,该对象包含搜索详细信息以及作为搜索操作结果的Document的文档ID。
现在,我们将向您展示一种逐步方法,并通过一个基本示例帮助您了解索引编制过程。
创建一个QueryParser
QueryParser类将用户输入的输入解析为Lucene易于理解的格式查询。请按照以下步骤创建QueryParser-
步骤1-创建QueryParser的对象。
步骤2-初始化使用标准分析器创建的QueryParser对象,该标准分析器具有要在其上运行此查询的版本信息和索引名称。
QueryParser queryParser;
public Searcher(String indexDirectoryPath) throws IOException {
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
创建一个IndexSearcher
IndexSearcher类是搜索器在建立索引过程中创建索引的核心组件。请按照以下步骤创建IndexSearcher-
步骤1-创建IndexSearcher的对象。
步骤2-创建一个Lucene目录,该目录应指向要存储索引的位置。
步骤3-初始化使用索引目录创建的IndexSearcher对象。
IndexSearcher indexSearcher;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
}
搜寻
请按照以下步骤进行搜索-
步骤1-通过QueryParser解析搜索表达式来创建Query对象。
步骤2-通过调用IndexSearcher.search()方法进行搜索。
Query query;
public TopDocs search( String searchQuery) throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
取得文件
以下程序显示如何获取文档。
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
关闭IndexSearcher
以下程序显示了如何关闭IndexSearcher。
public void close() throws IOException {
indexSearcher.close();
}
应用范例
让我们创建一个测试Lucene应用程序来测试搜索过程。
| Step | Description |
|---|---|
| 1 |
Create a project with a name LuceneFirstApplication under a package com.tutorialspoint.lucene as explained in the Lucene – First Application chapter. You can also use the project created in Lucene – First Application chapter as such for this chapter to understand the searching process. |
| 2 |
Create LuceneConstants.java,TextFileFilter.java and Searcher.java as explained in the Lucene – First Application chapter. Keep the rest of the files unchanged. |
| 3 |
Create LuceneTester.java as mentioned below. |
| 4 |
Clean and Build the application to make sure business logic is working as per the requirements. |
LuceneConstants.java
此类用于提供要在整个示例应用程序中使用的各种常量。
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}
TextFileFilter.java
此类用作.txt文件过滤器。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
Searcher.java
此类用于读取对原始数据进行的索引并使用Lucene库搜索数据。
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}
LuceneTester.java
此类用于测试Lucene库的搜索能力。
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) +" ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}
数据和索引目录创建
我们使用了10个名为record1.txt的文本文件到record10.txt,其中包含学生的姓名和其他详细信息,并将它们放在目录E:\ Lucene \ Data中。测试数据。索引目录路径应创建为E:\ Lucene \ Index。在“ Lucene-索引过程”一章中运行索引程序之后,您可以看到在该文件夹中创建的索引文件的列表。
运行程序
一旦完成了源,原始数据,数据目录,索引目录和索引的创建,就可以通过编译和运行程序来继续进行。为此,请保持LuceneTester.Java文件选项卡处于活动状态,并使用Eclipse IDE中可用的“运行”选项,或者使用Ctrl + F11编译并运行您的LuceneTester应用程序。如果您的应用程序成功运行,它将在Eclipse IDE的控制台中显示以下消息-
1 documents found. Time :29 ms
File: E:\Lucene\Data\record4.txt