MongoDB 中的聚合
在 MongoDB 中,聚合操作处理数据记录/文档并返回计算结果。它从各种文档中收集值并将它们分组在一起,然后对分组的数据执行不同类型的操作,如总和、平均值、最小值、最大值等,以返回计算结果。它类似于 SQL 的聚合函数。
MongoDB 提供了三种方式来执行聚合
- 聚合管道
- Map-reduce函数
- 单一用途聚合
聚合管道
在 MongoDB 中,聚合管道由阶段组成,每个阶段都会转换文档。或者换句话说,聚合管道是一个多阶段管道,因此在每个状态下,将文档作为输入并在下一阶段(id 可用)中将文档作为输入并生成结果文档集作为输入并生成输出,这个过程一直持续到最后一个阶段。基本管道阶段提供过滤器来执行类似的查询,文档转换修改结果文档,另一个管道提供用于对文档进行分组和排序的工具。您还可以在分片集合中使用聚合管道。
让我们借助一个示例来讨论聚合管道:

在上面的第一阶段收集火车票价的例子中。在这里,$match 阶段通过 class 字段中的值过滤文档,即 class: “first-class” 并将文档传递给第二阶段。在第二阶段,$group 阶段按 id 字段对文档进行分组,以计算每个唯一 id 的票价总和。
这里,aggregate()函数用于执行聚合,它可以有三个运算符阶段,表达式和累加器。

阶段:每个阶段都从阶段运算符开始,它们是:
- $match:用于过滤文档,可以减少作为下一阶段输入的文档数量。
- $project:用于从集合中选择一些特定的字段。
- $group:用于根据某个值对文档进行分组。
- $sort:用于对重新排列它们的文档进行排序
- $skip:用于跳过n个文档并传递剩余的文档
- $limit:用于传递前 n 个文档,从而限制它们。
- $unwind:它用于展开使用数组的文档,即它解构文档中的数组字段以返回每个元素的文档。
- $out:用于将结果文档写入新集合
表达式:它指的是输入文档中的字段名称,例如 { $group : { _id : “ $id “, total:{$sum:” $fare “}}} 这里$id和$fare是表达式。
累加器:这些基本上都是用在小组赛阶段
- sum:它对每个组中的文档的数值求和
- 数:它 计算文档总数
- avg:计算所有文档中所有给定值的平均值
- min:从所有文档中获取最小值
- max:从所有文档中取最大值
- first:从分组中获取第一个文档
- last:从分组中获取最后一个文档
笔记:
- 在 $group _id 是必填字段
- $out 必须是管道的最后阶段
- $sum:1 将计算文档的数量, $sum:”$fare” 将给出每个 id 生成的总票价的总和。
例子:
在以下示例中,我们正在使用:
Database: GeeksForGeeks
Collection: students
Documents: Seven documents that contain the details of the students in the form of field-value pairs.
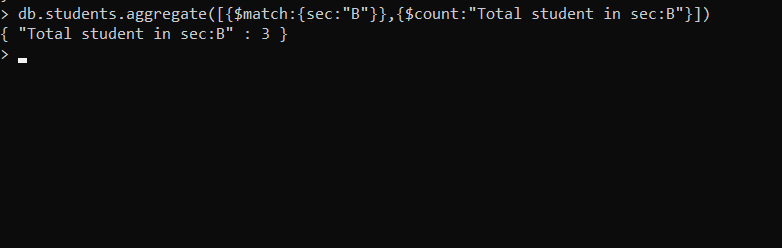
- 只显示一个部分的学生总数
db.students.aggregate([{$match:{sec:"B"}},{$count:"Total student in sec:B"}])在这个例子中,为了统计 B 部分的学生人数,我们首先使用$match运算符过滤文档,然后我们使用$count累加器计算从 $ 过滤后通过的文档总数比赛。
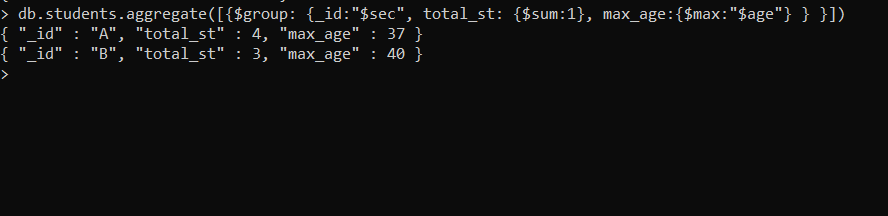
- 显示两个部分的学生总数和两个部分的最大年龄
db.students.aggregate([{$group: {_id:"$sec", total_st: {$sum:1}, max_age:{$max:"$age"} } }])在这个例子中,我们使用$group来分组,这样我们就可以对文档中的每个其他部分进行计数,这里$sum对每个组中的文档求和,并且$max accumulator 应用于年龄表达式,它将找到最大年龄每个文件。
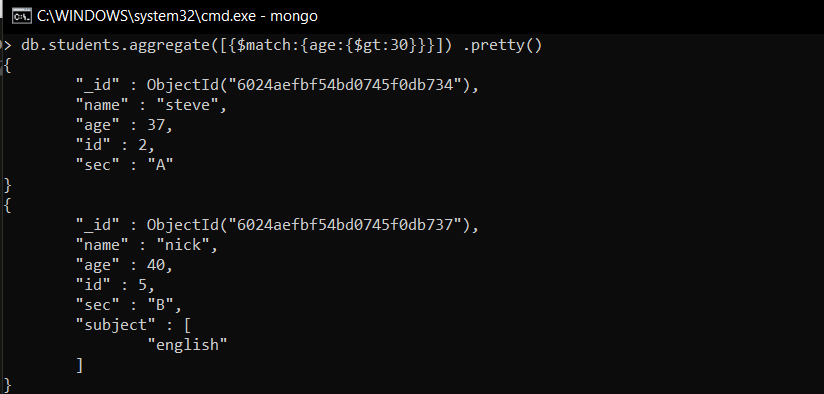
- 使用匹配阶段显示年龄大于 30 岁的学生的详细信息
db.students.aggregate([{$match:{age:{$gt:30}}}])在本例中,我们显示年龄大于 30 岁的学生。因此我们使用$match运算符过滤掉文档。
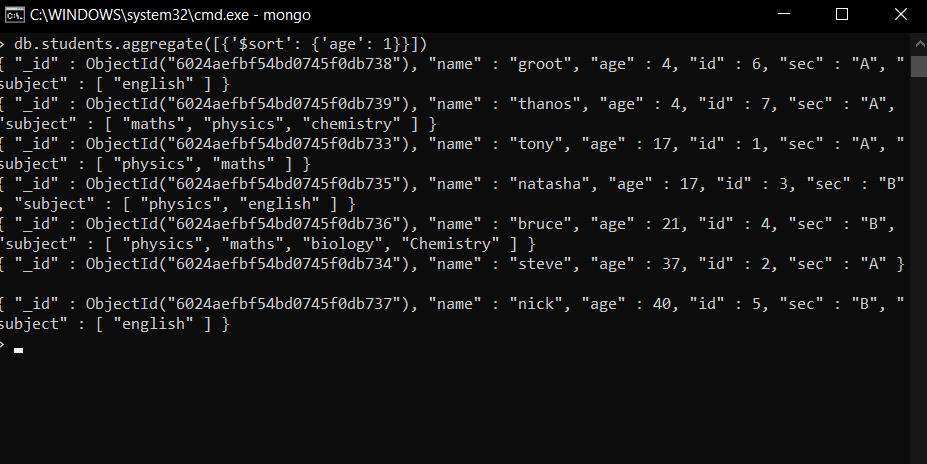
- 学生按年龄排序
db.students.aggregate([{'$sort': {'age': 1}}])在这个例子中,我们使用$sort运算符按升序排序,我们提供 'age':1 如果我们想按降序排序,我们可以简单地将 1 更改为 -1,即 'age':-1。
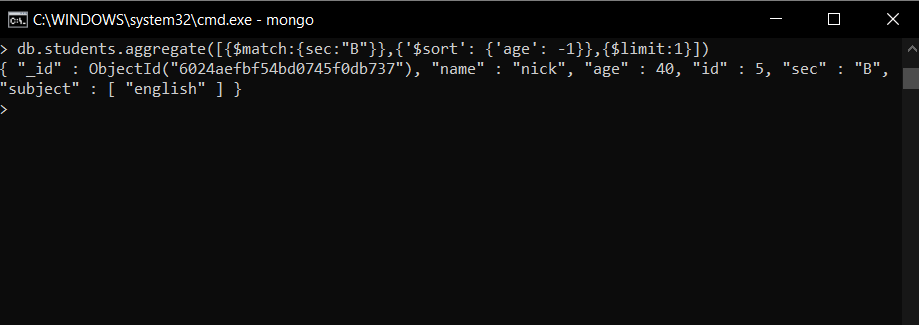
- 显示部分中年龄最大的学生的详细信息 - B
db.students.aggregate([{$match:{sec:"B"}},{'$sort': {'age': -1}},{$limit:1}])在这个例子中,首先,我们只选择那些有 B 部分的文档,因此,我们使用$match运算符 然后我们通过设置 'age':-1 使用$sort按降序对文档进行排序,然后我们使用$limit只显示最上面的结果。
- 根据科目解散学生
在我们的集合中对数组展开工作,我们有一系列科目(其中包含不同的科目,如数学、物理、英语等),因此展开将在此基础上完成,即数组将被解构,输出将只有一个主题不是一组较早存在的主题。
db.students.aggregate([{$unwind:"$subject"}]) 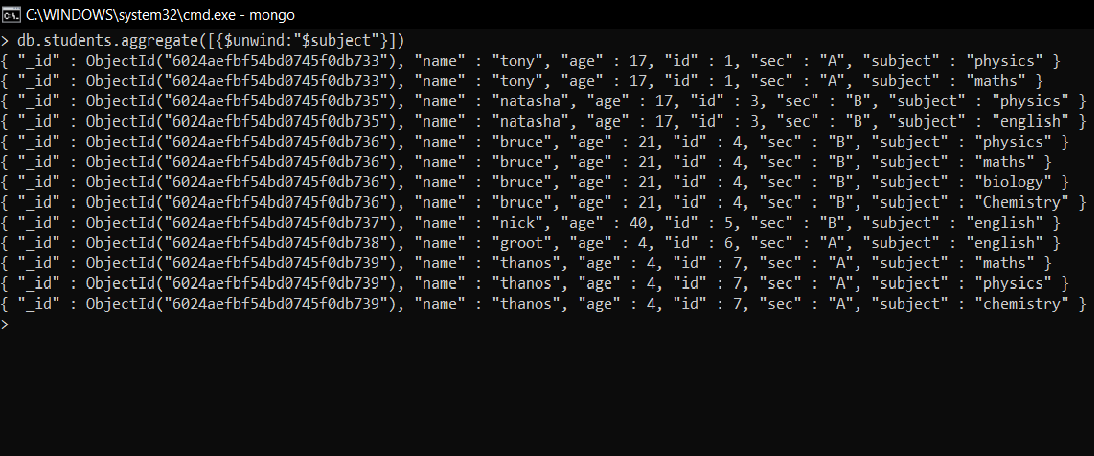
地图缩小
Map reduce 用于聚合大量数据的结果。 Map reduce有两个主要功能,一个是将所有文档分组的映射,第二个是对分组数据执行操作的reduce 。
句法:
db.collectionName.mapReduce(mappingFunction, reduceFunction, {out:'Result'});例子:
在以下示例中,我们正在使用:
Database: GeeksForGeeks
Collection: studentsMark
Documents: Seven documents that contain the details of the students in the form of field-value pairs.
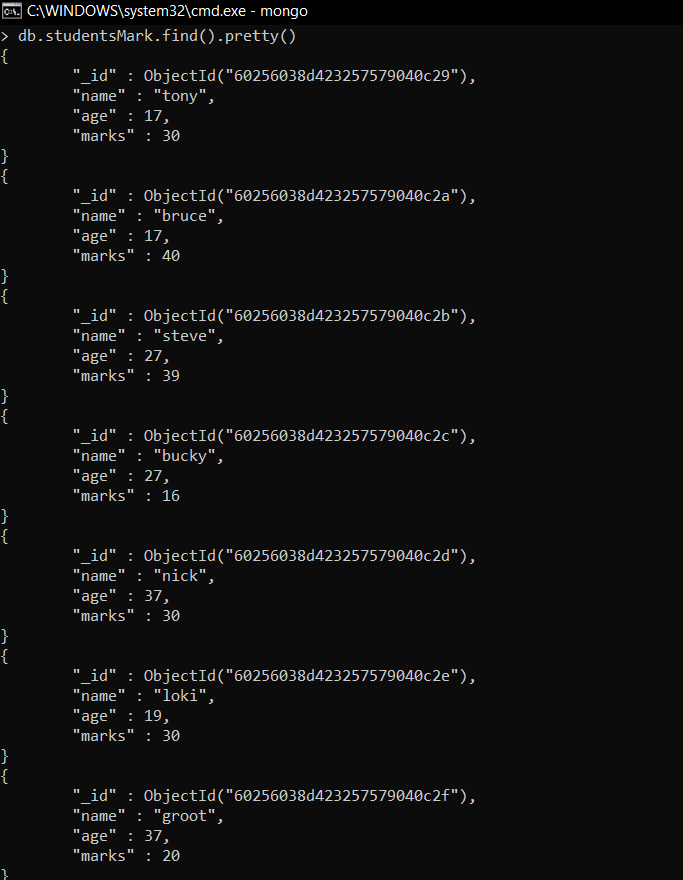
var mapfunction = function(){emit(this.age, this.makrs)}
var reducefunction = function(key, values){return Array.sum(values)}
db.studentsMarks.mapReduce(mapfunction, reducefunction, {'out':'Result'})现在,我们将根据年龄对文件进行分组,并找出每个年龄组的总分。因此,我们将创建两个变量,第一个 mapfunction 将发出 age 作为键(在输出中表示为“_id”)并将此发出的数据标记为值传递给我们的 reducefunction,它将 key 和 value 作为分组数据,然后它对其执行操作。执行归约后,结果存储在一个集合中,在这种情况下,集合是结果。
单一目的聚合
当我们需要对文档进行简单访问时使用它,例如计算文档数量或查找文档中的所有不同值。它只是使用count()、distinct() 和estimatedDocumentCount() 方法提供对公共聚合过程的访问,因此它缺乏管道的灵活性和功能。
例子:
在以下示例中,我们正在使用:
Database: GeeksForGeeks
Collection: studentsMark
Documents: Seven documents that contain the details of the students in the form of field-value pairs.
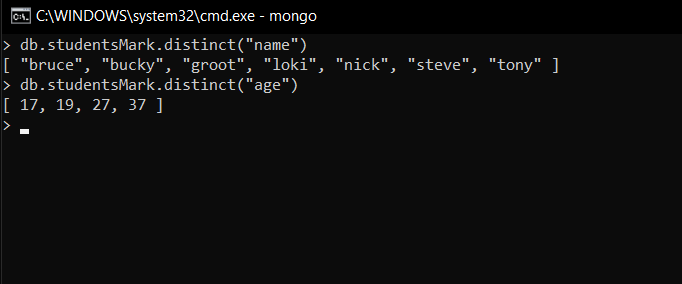
- 显示不同的名字和年龄(非重复)
db.studentsMarks.distinct("name")在这里,我们使用一个 distinct() 方法来查找指定字段(即名称)的不同值。
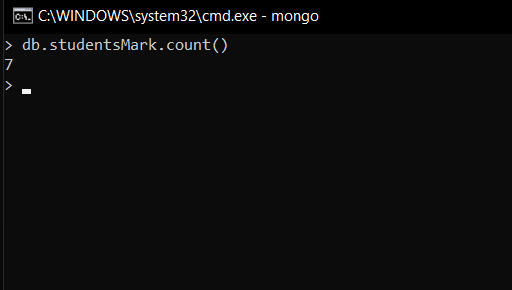
- 计算文档总数
db.studentsMarks.count()在这里,我们使用 count() 来查找文档的总数,与 find() 方法不同,它不会查找所有文档,而是对它们进行计数并返回一个数字。