- PHP 7-快速指南(1)
- PHP 7-快速指南
- AJAX-快速指南(1)
- AJAX-快速指南
- JDBC-快速指南(1)
- JDBC-快速指南
- 移动计算-快速指南
- 移动计算-快速指南(1)
- 区块链-快速指南
- 敏捷-快速指南
- 敏捷-快速指南(1)
- Spark SQL-数据框
- Spark SQL-数据框(1)
- Underscore.JS-快速指南(1)
- Underscore.JS-快速指南
- Bulma-快速指南
- Bulma-快速指南(1)
- Pytest-快速指南
- DLL-快速指南
- DLL-快速指南(1)
- Splunk-快速指南
- Highcharts-快速指南
- Highcharts-快速指南(1)
- OAuth 2.0-快速指南(1)
- OAuth 2.0-快速指南
- PhoneGap-快速指南
- PhoneGap-快速指南(1)
- RADIUS-快速指南(1)
- SOAP-快速指南(1)
📅 最后修改于: 2020-11-29 08:03:31 🧑 作者: Mango
行业正在广泛使用Hadoop分析其数据集。原因是Hadoop框架基于简单的编程模型(MapReduce),它使计算解决方案具有可扩展性,灵活性,容错性和成本效益。在这里,主要的关注点是在查询之间的等待时间和运行程序的等待时间方面,保持处理大型数据集的速度。
Apache Software Foundation引入Spark是为了加快Hadoop计算计算软件过程。
与通常的看法相反, Spark不是Hadoop的修改版,并且实际上不依赖Hadoop,因为它具有自己的集群管理。 Hadoop只是实施Spark的方法之一。
Spark通过两种方式使用Hadoop:一种是存储,另一种是处理。由于Spark具有自己的集群管理计算,因此仅将Hadoop用于存储目的。
Apache Spark
Apache Spark是一种快如闪电的集群计算技术,专为快速计算而设计。它基于Hadoop MapReduce,并扩展了MapReduce模型以有效地将其用于更多类型的计算,其中包括交互式查询和流处理。 Spark的主要功能是其内存中的群集计算,可提高应用程序的处理速度。
Spark旨在涵盖各种工作负载,例如批处理应用程序,迭代算法,交互式查询和流。除了在各自的系统中支持所有这些工作负载之外,它还减少了维护单独工具的管理负担。
Apache Spark的演变
Spark是Hadoop的子项目之一,该子项目由Matei Zaharia在2009年在UC Berkeley的AMPLab中开发。它在BSD许可下于2010年开源。它于2013年捐赠给Apache软件基金会,现在Apache Spark从2014年2月起已成为顶级Apache项目。
Apache Spark的功能
Apache Spark具有以下功能。
-
速度-Spark有助于在Hadoop集群中运行应用程序,内存速度最高可提高100倍,而在磁盘上运行时则可提高10倍。这可以通过减少对磁盘的读/写操作次数来实现。它将中间处理数据存储在内存中。
-
支持多种语言-Spark提供Java,Scala或Python内置的API。因此,您可以使用不同的语言编写应用程序。 Spark提供了80个高级运算符用于交互式查询。
-
高级分析-Spark不仅支持“地图”和“减少”。它还支持SQL查询,流数据,机器学习(ML)和图算法。
基于Hadoop构建的Spark
下图显示了如何使用Hadoop组件构建Spark的三种方式。
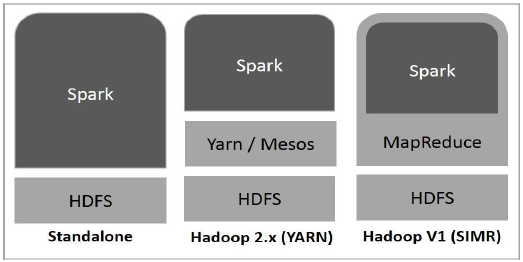
Spark部署有以下三种方式。
-
独立-Spark独立部署意味着Spark占据了HDFS(Hadoop分布式文件系统)之上的位置,并且为HDFS明确分配了空间。在这里,Spark和MapReduce将并排运行以覆盖集群上的所有Spark作业。
-
Hadoop Yarn -Hadoop Yarn部署意味着,Spark在Yarn上运行,无需任何预安装或root访问。它有助于将Spark集成到Hadoop生态系统或Hadoop堆栈中。它允许其他组件在堆栈顶部运行。
-
MapReduce中的Spark(SIMR)-MapReduce中的Spark除了独立部署外,还用于启动Spark作业。使用SIMR,用户可以启动Spark并使用其Shell,而无需任何管理访问权限。
Spark的组成
下图描述了Spark的不同组件。
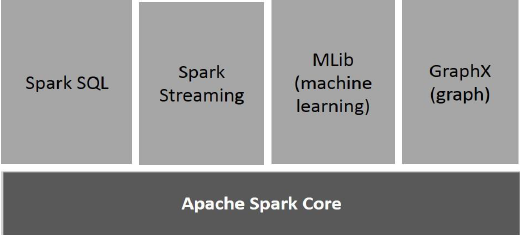
Apache Spark核心
Spark Core是所有其他功能都基于的Spark平台的基础通用执行引擎。它提供了外部存储系统中的内存中计算和引用数据集。
Spark SQL
Spark SQL是Spark Core之上的组件,它引入了一个称为SchemaRDD的新数据抽象,该抽象为结构化和半结构化数据提供支持。
火花流
Spark Streaming利用Spark Core的快速调度功能来执行流分析。它以小批量提取数据,并对那些小批量数据执行RDD(弹性分布式数据集)转换。
MLlib(机器学习库)
MLlib是基于Spark的分布式机器学习框架,因为它基于分布式内存的Spark体系结构。根据基准,它是由MLlib开发人员针对交替最小二乘(ALS)实现而完成的。 Spark MLlib的速度是Apache Mahout的基于Hadoop磁盘的版本的9倍(在Mahout获得Spark接口之前)。
GraphX
GraphX是基于Spark的分布式图形处理框架。它提供了一个用于表达图形计算的API,该API可以通过使用Pregel抽象API对用户定义的图形进行建模。它还为此抽象提供了优化的运行时。
火花– RDD
弹性分布式数据集
弹性分布式数据集(RDD)是Spark的基本数据结构。它是对象的不可变分布式集合。 RDD中的每个数据集都分为逻辑分区,可以在群集的不同节点上进行计算。 RDD可以包含任何类型的Python,Java或Scala对象,包括用户定义的类。
正式而言,RDD是记录的只读分区集合。可以通过对稳定存储上的数据或其他RDD进行确定性操作来创建RDD。 RDD是可以并行操作的元素的容错集合。
有两种创建RDD的方法-并行化驱动程序中的现有集合,或引用外部存储系统(例如共享文件系统,HDFS,HBase或提供Hadoop输入格式的任何数据源)中的数据集。
Spark利用RDD的概念来实现更快,更有效的MapReduce操作。让我们首先讨论MapReduce操作是如何发生的以及为什么它们效率不高。
MapReduce中的数据共享速度很慢
MapReduce被广泛采用,用于在集群上使用并行分布式算法处理和生成大型数据集。它允许用户使用一组高级运算符来编写并行计算,而不必担心工作分配和容错性。
不幸的是,在大多数当前框架中,在计算之间重用数据的唯一方法(例如:两个MapReduce作业之间)是将其写入外部稳定存储系统(例如:HDFS)。尽管此框架提供了许多用于访问群集的计算资源的抽象,但用户仍然需要更多。
迭代和交互式应用程序都需要跨并行作业更快地共享数据。由于复制,序列化和磁盘IO ,MapReduce中的数据共享速度很慢。对于存储系统,大多数Hadoop应用程序花费90%以上的时间进行HDFS读写操作。
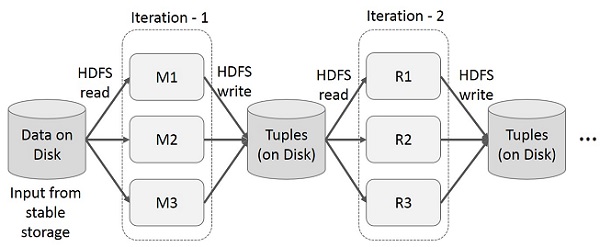
MapReduce上的迭代操作
在多阶段应用程序中跨多个计算重用中间结果。下图说明了在MapReduce上进行迭代操作时当前框架的工作方式。由于数据复制,磁盘I / O和序列化,这会导致相当大的开销,这会使系统变慢。
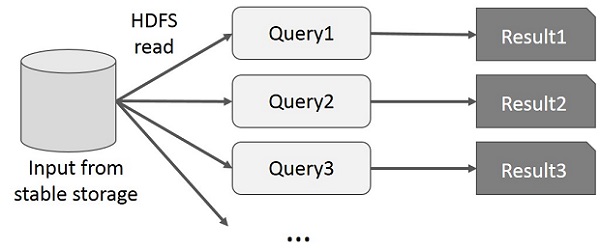
MapReduce上的交互式操作
用户对同一数据子集运行临时查询。每个查询都会在稳定存储上执行磁盘I / O,这可能会影响应用程序的执行时间。
下图说明了在MapReduce上进行交互式查询时当前框架的工作方式。
使用Spark RDD进行数据共享
由于复制,序列化和磁盘IO ,MapReduce中的数据共享速度很慢。在大多数Hadoop应用程序中,它们花费90%以上的时间进行HDFS读写操作。
认识到此问题后,研究人员开发了一种名为Apache Spark的专用框架。火花的关键思想为R esilient d istributed d atasets(RDD);它支持内存处理计算。这意味着,它将内存状态存储为跨作业的对象,并且该对象可在这些作业之间共享。内存中的数据共享比网络和磁盘快10到100倍。
现在让我们尝试找出在Spark RDD中如何进行迭代和交互操作。
Spark RDD上的迭代操作
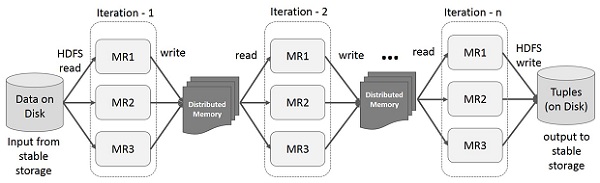
下图显示了Spark RDD上的迭代操作。它将中间结果存储在分布式内存中,而不是稳定存储(磁盘)中,并使系统运行更快。
注–如果分布式内存(RAM)足以存储中间结果(JOB的状态),则它将这些结果存储在磁盘上
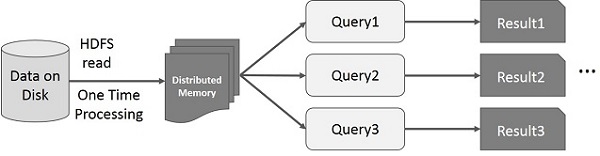
Spark RDD上的交互式操作
此图显示了在Spark RDD上的交互操作。如果对同一组数据重复执行不同的查询,则可以将这些特定数据保留在内存中,以缩短执行时间。
默认情况下,每次在其上执行操作时,都可能会重新计算每个转换后的RDD。但是,您也可以将RDD保留在内存中,在这种情况下,Spark将在下次查询时将元素保留在群集中,以加快访问速度。还支持将RDD持久保存在磁盘上,或在多个节点之间复制。
Spark-安装
Spark是Hadoop的子项目。因此,最好将Spark安装到基于Linux的系统中。以下步骤显示了如何安装Apache Spark。
步骤1:验证Java安装
Java安装是安装Spark的必要步骤之一。尝试使用以下命令来验证JAVA版本。
$java -version
如果您的系统上已经安装了Java,则会看到以下响应-
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您的系统上没有安装Java,请在继续下一步之前先安装Java。
步骤2:验证Scala安装
您应该使用Scala语言来实现Spark。因此,让我们使用以下命令来验证Scala的安装。
$scala -version
如果您的系统上已经安装了Scala,则会看到以下响应-
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
如果您的系统上未安装Scala,请继续执行下一步以进行Scala安装。
第三步:下载Scala
通过访问以下链接下载Scala下载最新版本的Scala 。对于本教程,我们使用的是scala-2.11.6版本。下载后,您将在下载文件夹中找到Scala tar文件。
步骤4:安装Scala
请按照以下给定的步骤安装Scala。
提取Scala tar文件
键入以下命令以提取Scala tar文件。
$ tar xvf scala-2.11.6.tgz
移动Scala软件文件
使用以下命令将Scala软件文件移动到相应目录(/ usr / local / scala) 。
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv scala-2.11.6 /usr/local/scala
# exit
设置Scala的PATH
使用以下命令为Scala设置PATH。
$ export PATH = $PATH:/usr/local/scala/bin
验证Scala安装
安装后,最好进行验证。使用以下命令来验证Scala安装。
$scala -version
如果您的系统上已经安装了Scala,则会看到以下响应-
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
步骤5:下载Apache Spark
通过访问以下链接下载Spark下载最新版本的Spark 。在本教程中,我们使用spark-1.3.1-bin-hadoop2.6版本。下载后,您将在下载文件夹中找到Spark tar文件。
步骤6:安装Spark
请按照以下给出的步骤安装Spark。
提取火花焦油
以下命令用于提取spark tar文件。
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgz
移动Spark软件文件
以下命令用于将Spark软件文件移动到相应目录(/ usr / local / spark) 。
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
# exit
设置Spark环境
将以下行添加到〜/ .bashrc文件。这意味着将火花软件文件所在的位置添加到PATH变量中。
export PATH = $PATH:/usr/local/spark/bin
使用以下命令来获取〜/ .bashrc文件。
$ source ~/.bashrc
步骤7:验证Spark安装
编写以下命令以打开Spark Shell。
$spark-shell
如果spark安装成功,那么您将找到以下输出。
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
Spark SQL-简介
Spark引入了用于结构化数据处理的编程模块,称为Spark SQL。它提供了一个称为DataFrame的编程抽象,并且可以充当分布式SQL查询引擎。
Spark SQL的功能
以下是Spark SQL的功能-
-
集成-将SQL查询与Spark程序无缝混合。使用Spark SQL,您可以在Spark中以分布式数据集(RDD)的形式查询结构化数据,并使用Python,Scala和Java中的集成API。这种紧密的集成使与复杂的分析算法一起运行SQL查询变得容易。
-
统一数据访问-从各种来源加载和查询数据。 Schema-RDD提供了一个单一接口,可有效使用结构化数据,包括Apache Hive表,镶木地板文件和JSON文件。
-
Hive兼容性-在现有仓库上运行未修改的Hive查询。 Spark SQL重用了Hive前端和MetaStore,使您与现有的Hive数据,查询和UDF完全兼容。只需将其与Hive一起安装即可。
-
标准连接-通过JDBC或ODBC连接。 Spark SQL包括具有行业标准JDBC和ODBC连接的服务器模式。
-
可伸缩性-对交互式查询和长查询使用相同的引擎。 Spark SQL利用RDD模型来支持中间查询的容错能力,从而使其也可以扩展到大型作业。不必担心为历史数据使用其他引擎。
Spark SQL架构
下图说明了Spark SQL的体系结构-
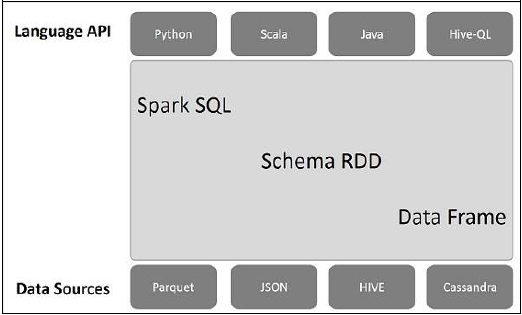
该体系结构包含三层,即语言API,模式RDD和数据源。
-
语言API -Spark与其他语言和Spark SQL兼容。这些语言API(Python,scala,java,HiveQL)也支持它。
-
模式RDD -Spark Core设计有称为RDD的特殊数据结构。通常,Spark SQL适用于架构,表和记录。因此,我们可以将Schema RDD用作临时表。我们可以将此模式RDD称为数据帧。
-
数据源-通常,spark-core的数据源是文本文件,Avro文件等。但是,Spark SQL的数据源是不同的。这些是Parquet文件,JSON文档,HIVE表和Cassandra数据库。
在后面的章节中,我们将讨论更多这些内容。
Spark SQL-数据框
DataFrame是数据的分布式集合,被组织为命名列。从概念上讲,它等效于具有良好优化技术的关系表。
可以从不同来源的数组(例如Hive表,结构化数据文件,外部数据库或现有RDD)构造DataFrame。该API是为现代大数据和数据科学应用程序设计的,灵感来自R编程中的DataFrame和Python的Pandas 。
DataFrame的功能
这是DataFrame的一些特点-
-
能够在单个节点群集到大型群集上处理千字节到PB大小的数据。
-
支持不同的数据格式(Avro,csv,弹性搜索和Cassandra)和存储系统(HDFS,HIVE表,mysql等)。
-
通过Spark SQL Catalyst优化器(树转换框架)进行最先进的优化和代码生成。
-
可以通过Spark-Core轻松地与所有大数据工具和框架集成。
-
提供适用于Python,Java,Scala和R编程的API。
SQLContext
SQLContext是一个类,用于初始化Spark SQL的功能。初始化SQLContext类对象需要SparkContext类对象(sc)。
以下命令用于通过spark-shell初始化SparkContext。
$ spark-shell
默认情况下,spark-shell启动时,SparkContext对象将使用名称sc初始化。
使用以下命令创建SQLContext。
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)
例
让我们考虑一个名为employee.json的JSON文件中的员工记录示例。使用以下命令创建DataFrame(df),并读取具有以下内容的名为employee.json的JSON文档。
employee.json-将文件放置在当前scala>指针所在的目录中。
{
{"id" : "1201", "name" : "satish", "age" : "25"}
{"id" : "1202", "name" : "krishna", "age" : "28"}
{"id" : "1203", "name" : "amith", "age" : "39"}
{"id" : "1204", "name" : "javed", "age" : "23"}
{"id" : "1205", "name" : "prudvi", "age" : "23"}
}
DataFrame操作
DataFrame为结构化数据操作提供了特定于域的语言。在这里,我们包括一些使用DataFrames进行结构化数据处理的基本示例。
请按照下面给出的步骤执行DataFrame操作-
阅读JSON文档
首先,我们必须阅读JSON文档。基于此,生成一个名为(dfs)的DataFrame。
使用以下命令来读取名为employee.json的JSON文档。数据显示为带有字段-ID,名称和年龄的表格。
scala> val dfs = sqlContext.read.json("employee.json")
输出-字段名称是自动从employee.json获取的。
dfs: org.apache.spark.sql.DataFrame = [age: string, id: string, name: string]
显示数据
如果要查看DataFrame中的数据,请使用以下命令。
scala> dfs.show()
输出-您可以以表格格式查看员工数据。
:22, took 0.052610 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
| 23 | 1204 | javed |
| 23 | 1205 | prudvi |
+----+------+--------+
使用printSchema方法
如果要查看DataFrame的结构(架构),请使用以下命令。
scala> dfs.printSchema()
输出
root
|-- age: string (nullable = true)
|-- id: string (nullable = true)
|-- name: string (nullable = true)
使用选择方法
使用以下命令从DataFrame的三列中获取名称-column。
scala> dfs.select("name").show()
输出-您可以看到名称列的值。
:22, took 0.044023 s
+--------+
| name |
+--------+
| satish |
| krishna|
| amith |
| javed |
| prudvi |
+--------+
使用年龄过滤器
使用以下命令查找年龄大于23(年龄> 23)的员工。
scala> dfs.filter(dfs("age") > 23).show()
输出
:22, took 0.078670 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
+----+------+--------+
使用groupBy方法
使用以下命令对相同年龄的员工数进行计数。
scala> dfs.groupBy("age").count().show()
输出-两名雇员的年龄为23岁。
:22, took 5.196091 s
+----+-----+
|age |count|
+----+-----+
| 23 | 2 |
| 25 | 1 |
| 28 | 1 |
| 39 | 1 |
+----+-----+
以编程方式运行SQL查询
SQLContext使应用程序可以在运行SQL函数的同时以编程方式运行SQL查询,并将结果作为DataFrame返回。
通常,在后台,SparkSQL支持两种不同的方法将现有的RDD转换为DataFrames-
| Sr. No | Methods & Description |
|---|---|
| 1 | Inferring the Schema using Reflection
This method uses reflection to generate the schema of an RDD that contains specific types of objects. |
| 2 | Programmatically Specifying the Schema
The second method for creating DataFrame is through programmatic interface that allows you to construct a schema and then apply it to an existing RDD. |
Spark SQL-数据源
DataFrame接口允许不同的DataSource在Spark SQL上工作。它是一个临时表,可以作为普通的RDD使用。将DataFrame注册为表可让您对其数据运行SQL查询。
在本章中,我们将介绍使用不同的Spark DataSource加载和保存数据的一般方法。此后,我们将详细讨论可用于内置数据源的特定选项。
SparkSQL中提供了不同类型的数据源,其中一些如下所示-
| Sr. No | Data Sources |
|---|---|
| 1 | JSON Datasets
Spark SQL can automatically capture the schema of a JSON dataset and load it as a DataFrame. |
| 2 | Hive Tables
Hive comes bundled with the Spark library as HiveContext, which inherits from SQLContext. |
| 3 | Parquet Files
Parquet is a columnar format, supported by many data processing systems. |