- 塔伦德-大数据(1)
- 塔伦德-简介
- 塔伦德-有用的资源
- 塔伦德-有用的资源(1)
- 塔伦德-地图缩小(1)
- 塔伦德-地图缩小
- 塔伦德-管理工作(1)
- 塔伦德-管理工作
- 内联 JavaScript 如何与 HTML 一起工作?
- 内联 JavaScript 如何与 HTML 一起工作?(1)
- 工作点(1)
- 工作点
- 与 HTML 一起Flutter(1)
- 与 HTML 一起Flutter
- 如何将 r 与变量一起使用 (1)
- 如何将 + 与字符串一起使用 - Python 代码示例
- node 和 bash 一起使用 - Javascript (1)
- 请工作 - Python (1)
- node 和 bash 一起使用 - Javascript 代码示例
- 如何将 r 与变量一起使用 - 无论代码示例
- 如何一起打印两个数组 - Javascript (1)
- 引导类路径未与 一起设置(1)
- python一起添加字典 - Python(1)
- 请工作 - Python 代码示例
- 一起安装 Discord - Shell-Bash (1)
- 如何一起打印两个数组 - Javascript 代码示例
- JavaScript如何工作
- python一起添加字典 - Python代码示例
- 如何将 Go 与 MongoDB 一起使用?
📅 最后修改于: 2020-11-29 08:52:30 🧑 作者: Mango
在本章中,让我们学习如何在Talend中处理Pig作业。
创建Talend Pig工作
在本节中,让我们学习如何在Talend上运行Pig作业。在这里,我们将处理NYSE数据以找出IBM的平均库存量。
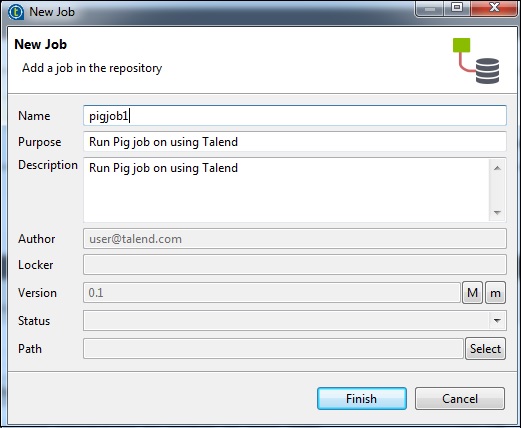
为此,右键单击作业设计并创建一个新作业– Pigjob。提及作业的详细信息,然后单击“完成”。
向Pig Job添加组件
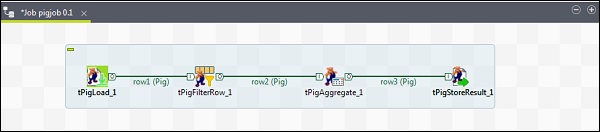
要将组件添加到Pig作业,请从托盘到设计器窗口拖放四个Talend组件:tPigLoad,tPigFilterRow,tPigAggregate,tPigStoreResult。
然后,右键单击tPigLoad,然后将Pig Combine行创建到tPigFilterRow。接下来,右键单击tPigFilterRow,然后将Pig Combine行创建到tPigAggregate。右键单击tPigAggregate,然后将Pig组合行创建到tPigStoreResult。
配置组件和转换
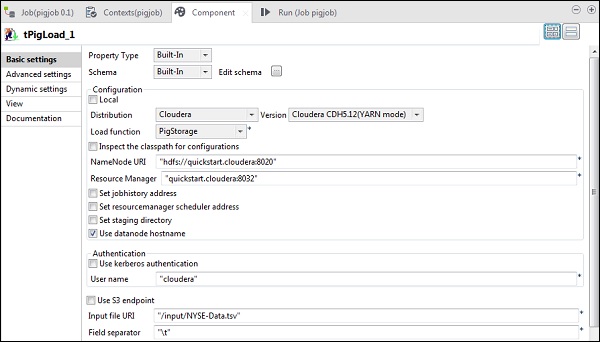
在tPigLoad中,将发行版称为cloudera和cloudera的版本。请注意,Namenode URI应为“ hdfs://quickstart.cloudera:8020”,资源管理器应为“ quickstart.cloudera:8020”。另外,用户名应为“ cloudera”。
在输入文件URI中,将NYSE输入文件的路径提供给Pig作业。请注意,此输入文件应存在于HDFS上。
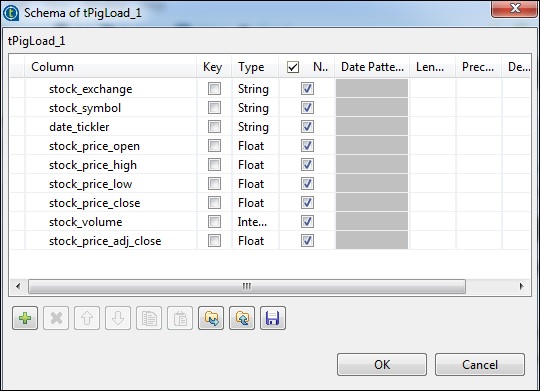
单击编辑架构,添加列及其类型,如下所示。
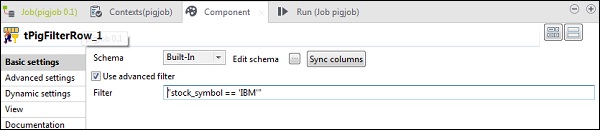
在tPigFilterRow中,选择“使用高级过滤器”选项,然后在“过滤器”选项中放入“ stock_symbol = =’IBM’”。
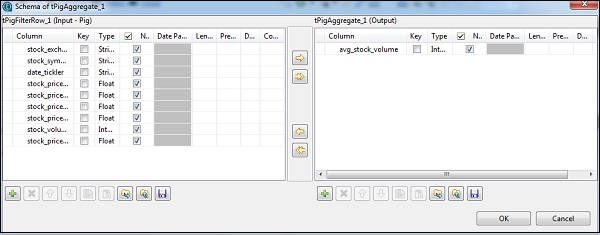
在tAggregateRow中,单击“编辑模式”,然后在输出中添加avg_stock_volume列,如下所示。
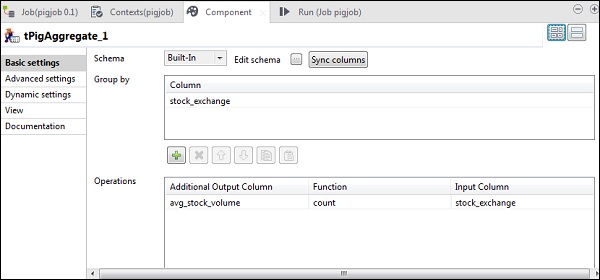
现在,将stock_exchange列放入“按选项分组”。在操作字段中添加avg_stock_volume列,并将计数功能和stock_exchange作为输入列。
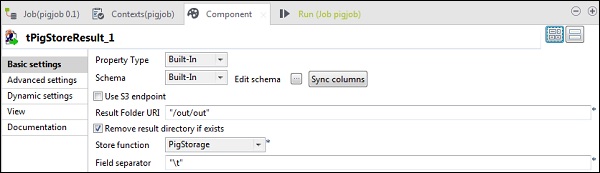
在tPigStoreResult中,在“结果文件夹URI”中提供要存储Pig作业结果的输出路径。选择存储函数作为PigStorage,选择字段分隔符(非强制性)作为“ \ t”。
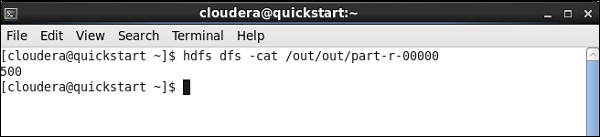
执行养猪工作
现在单击运行以执行您的Pig作业。 (忽略警告)
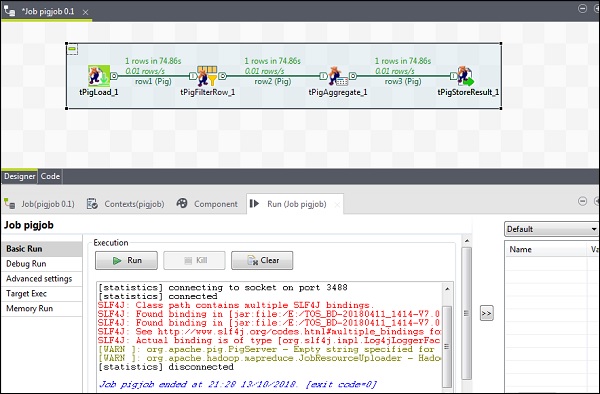
作业完成后,转到您提到的用于存储清管作业结果的HDFS路径中检查输出。 IBM的平均库存量为500。