神经网络中的激活函数
建议在阅读本文之前先了解什么是神经网络。在构建神经网络的过程中,您要做出的选择之一是在网络的隐藏层和输出层使用什么激活函数。本文讨论了一些选择。
神经网络的元素:-
输入层:-该层接受输入特征。它向网络提供来自外界的信息,在这一层不进行任何计算,这里的节点只是将信息(特征)传递给隐藏层。
隐藏层:-该层的节点不暴露于外部世界,它们是任何神经网络提供的抽象的一部分。隐藏层对通过输入层输入的特征执行各种计算,并将结果传输到输出层。
输出层:-该层将网络学到的信息带到外部世界。
什么是激活函数以及为什么要使用它们?
激活函数的定义:-激活函数通过计算加权和并进一步添加偏置来决定是否应该激活神经元。激活函数的目的是将非线性引入神经元的输出。
解释 :-
我们知道,神经网络具有对应于权重、偏差及其各自激活函数的神经元。在神经网络中,我们会根据输出的误差更新神经元的权重和偏差。这个过程被称为反向传播。激活函数使反向传播成为可能,因为梯度与误差一起提供以更新权重和偏差。
为什么我们需要非线性激活函数:-
没有激活函数的神经网络本质上只是一个线性回归模型。激活函数对输入进行非线性变换,使其能够学习和执行更复杂的任务。
数学证明:-
假设我们有一个像这样的神经网络:- 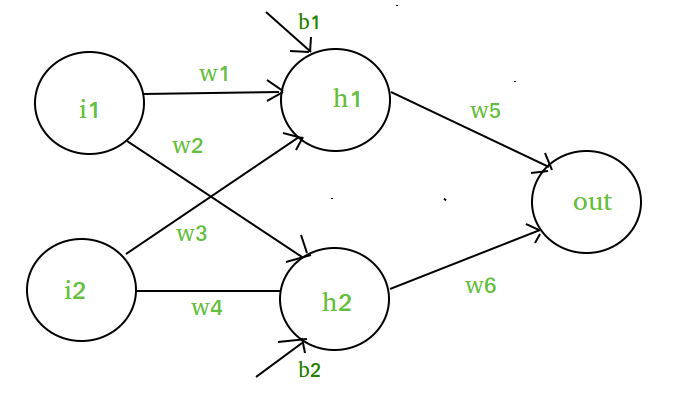
图表元素:-
隐藏层,即第 1 层:-
z(1) = W(1)X + b(1)
a(1) = z(1)
Here,
- z(1) is the vectorized output of layer 1
- W(1) be the vectorized weights assigned to neurons
of hidden layer i.e. w1, w2, w3 and w4 - X be the vectorized input features i.e. i1 and i2
- b is the vectorized bias assigned to neurons in hidden
layer i.e. b1 and b2 - a(1) is the vectorized form of any linear function.
(Note: We are not considering activation function here)
第 2 层,即输出层:-
// Note : Input for layer
// 2 is output from layer 1
z(2) = W(2)a(1) + b(2)
a(2) = z(2)
输出层计算:
// Putting value of z(1) here
z(2) = (W(2) * [W(1)X + b(1)]) + b(2)
z(2) = [W(2) * W(1)] * X + [W(2)*b(1) + b(2)]
Let,
[W(2) * W(1)] = W
[W(2)*b(1) + b(2)] = b
Final output : z(2) = W*X + b
Which is again a linear function
即使在应用了隐藏层之后,这个观察结果仍然是线性函数,因此我们可以得出结论,无论我们在神经网络中附加多少隐藏层,所有层的行为方式都相同,因为两个线性函数的组合是线性函数本身。神经元不能仅通过附加的线性函数学习。非线性激活函数将让它根据与误差的差异进行学习。
因此我们需要激活函数。
激活功能的变体:-
1)。线性函数:-
- 方程:线性函数的方程类似于直线,即y = ax
- 无论我们有多少层,如果本质上都是线性的,那么最后一层的最终激活函数只不过是第一层输入的线性函数。
- 范围: -inf 到 +inf
- 用途:线性激活函数仅用于一个地方,即输出层。
- 问题:如果我们将线性函数微分以带来非线性,结果将不再依赖于输入“x”并且函数将变为常数,它不会为我们的算法引入任何突破性的行为。
例如:房屋价格的计算是一个回归问题。房价可能有任何大/小值,因此我们可以在输出层应用线性激活。即使在这种情况下,神经网络也必须在隐藏层具有任何非线性函数。
2)。 Sigmoid函数:-
- 它是一个绘制为“S”形图的函数。
- 方程:
A = 1/(1 + e -x ) - 性质:非线性。请注意,X 值介于 -2 到 2 之间,Y 值非常陡峭。这意味着,x 的微小变化也会导致 Y 值的巨大变化。
- 值范围: 0 到 1
- 用途:通常用于二元分类的输出层,其中结果为 0 或 1,因为 sigmoid函数的值仅在 0 和 1 之间,因此如果值大于0.5 ,则可以轻松预测结果为1 ,否则为0 .
3)。 Tanh函数:-几乎总是比 sigmoid函数更好的激活是 Tanh函数,也称为正切双曲函数。它实际上是 sigmoid函数的数学变换版本。两者是相似的,可以相互推导出来。
f(x) = tanh(x) = 2/(1 + e-2x) - 1
OR
tanh(x) = 2 * sigmoid(2x) - 1 - 值范围:- -1 到 +1
- 性质:-非线性
- 用途:-通常用于神经网络的隐藏层,因为它的值介于-1 到 1之间,因此隐藏层的平均值为 0 或非常接近它,因此有助于通过使平均值接近 0 来使数据居中. 这使得下一层的学习更加容易。
4)。 RELU:-代表整流线性单元。它是使用最广泛的激活函数。主要在神经网络的隐藏层实现。
- 方程:- A(x) = max(0,x) 。如果 x 为正,则给出输出 x,否则为 0。
- 值范围:- [0, inf)
- 性质:-非线性,这意味着我们可以轻松地反向传播错误并通过 ReLU函数激活多层神经元。
- 用途:- ReLu 的计算成本低于 tanh 和 sigmoid,因为它涉及更简单的数学运算。一次只有几个神经元被激活,使网络变得稀疏,从而使其高效且易于计算。
简单来说,RELU 的学习速度比 sigmoid 和 Tanh函数快得多。
5)。 Softmax函数:- softmax函数也是一种 sigmoid函数,但在我们尝试处理分类问题时很方便。
- 性质:-非线性
- 用途:-通常在尝试处理多个类时使用。 softmax函数会将每个类别的输出压缩在 0 到 1 之间,并且还会除以输出的总和。
- 输出:- softmax函数理想地用于分类器的输出层,我们实际上试图获得定义每个输入类别的概率。
选择正确的激活功能
- 基本的经验法则是,如果您真的不知道要使用什么激活函数,那么只需使用RELU,因为它是一种通用的激活函数,并且在当今大多数情况下都在使用。
- 如果您的输出用于二元分类,那么sigmoid函数是输出层非常自然的选择。
脚注:-
激活函数对输入进行非线性变换,使其能够学习和执行更复杂的任务。
参考 :
了解神经网络中的激活函数