神经网络中的激活函数 |套装2
文章 Activation-functions-neural-networks 将有助于理解激活函数的使用以及它的一些变体的解释,如线性、sigmoid、tanh、Relu 和 softmax。激活函数还有其他一些变体,如 Elu、Selu、Leaky Relu、Softsign 和 Softplus,本文将对其进行简要讨论。
泄漏 Relu函数:
Leaky Rectified linear unit (Leaky Relu) 是 Relu函数的扩展,用于克服垂死神经元问题。 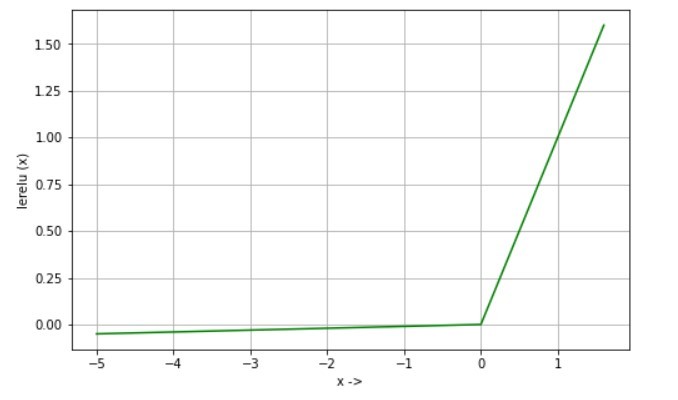
方程:
lerelu(x) = x if x>0
lerelu(x) = 0.01 * x if x<=0 衍生物:
d/dx lerelu(x) = 1 if x>0
d/dx lerelu(x) = 0.01 if x<=0
用途:如果输入为负,则 Relu 返回 0,因此神经元变得不活动,因为它对梯度流没有贡献。 Leaky Relu 通过在输入为负时允许小值流动来克服这个问题。因此,如果使用 Relu 学习速度太慢,可以尝试使用 Leaky Relu 来查看是否有任何改进。
埃卢函数:
指数线性单元也类似于 Leaky Relu,但对于负输入有所不同。它还有助于克服垂死的神经元问题。 
方程:
elu(x) = x if x>0
elu(x) = alpha * (exp(x)-1) if x<0
衍生物:
d/dx elu(x) = 1 if x>0
d/dx elu(x) = elu(x) + alpha if x<=0
用途:与Leaky Relu的目的相同,代价函数向零收敛比Relu和Leaky Relu更快。例如,使用 Elu 在 Imagenet 上学习神经网络比使用 Relu 更快。
塞卢函数:
Scaled Exponential Linear Unit 是 Elu 的缩放形式。只需将 Elu 的输出乘以预定的“比例”参数,您就会得到 selu 给出的所需输出。 
方程:
selu(x) = scale * x if x>0
selu(x) = scale * alpha * (exp(x)-1) if x<=0
where,
alpha = 1.67326324
scale = 1.05070098
衍生物:
d/dx selu(x) = scale if x>0
d/dx selu(x) = selu(x) + scale * alpha if x<=0
用途:此激活函数用于自归一化神经网络 (SNN),该网络用于训练受梯度消失和爆炸问题影响较小的深度和鲁棒网络。
软签名函数:
Softsign函数是 tanh函数的替代方法,其中 tanh 呈指数收敛,softsign 呈多项式收敛。 
方程:
softsign(x) = x / (1 + |x|)
衍生物:
d/dx softsign(x) = 1 / (1 + |x|)^2
用途:主要用于回归问题,可以在深度神经网络中用于文本到语音的转换。
软加函数:
Softplus函数是 Relu 激活函数的平滑形式,其导数是 sigmoid函数。它还有助于克服垂死的神经元问题。  方程:
方程:
softplus(x) = log(1 + exp(x))
衍生物:
d/dx softplus(x) = 1 / (1 + exp(-x))
用途:一些实验表明,softplus 比 Relu 和 sigmoid 需要更少的 epochs 来收敛。它可以用于语音识别系统。