- HCatalog-创建表(1)
- HCatalog-创建表
- HCatalog-安装
- HCatalog-安装(1)
- HCatalog-更改表(1)
- HCatalog-更改表
- HCatalog-显示表(1)
- HCatalog-显示表
- HCatalog-索引
- HCatalog-索引(1)
- HCatalog教程
- HCatalog教程(1)
- HCatalog-视图(1)
- HCatalog-视图
- 讨论Hcatalog
- 讨论Hcatalog(1)
- HCatalog-CLI(1)
- HCatalog-CLI
- HCatalog-有用的资源
- HCatalog-有用的资源(1)
- HCatalog-显示分区
- HCatalog-显示分区(1)
- HCatalog-输入输出格式(1)
- HCatalog-输入输出格式
- HCatalog-加载器和存储器(1)
- HCatalog-加载器和存储器
- R树简介(1)
- 图简介(1)
- 块图简介(1)
📅 最后修改于: 2020-11-30 04:22:16 🧑 作者: Mango
什么是HCatalog?
HCatalog是用于Hadoop的表存储管理工具。它将Hive元存储的表格数据公开给其他Hadoop应用程序。它使使用不同数据处理工具(Pig,MapReduce)的用户可以轻松地将数据写入网格。它确保用户不必担心数据存储在何处或以何种格式存储。
HCatalog就像Hive的关键组件一样工作,它使用户能够以任何格式和任何结构存储其数据。
为什么选择HCatalog?
为正确的工作启用正确的工具
Hadoop生态系统包含用于数据处理的不同工具,例如Hive,Pig和MapReduce。尽管这些工具不需要元数据,但是当它们存在时,它们仍然可以从中受益。共享元数据存储还可以使用户跨各种工具更轻松地共享数据。使用MapReduce或Pig加载并规范化数据,然后通过Hive分析数据的工作流非常普遍。如果所有这些工具共享一个metastore,则每个工具的用户都可以立即访问使用另一工具创建的数据。无需加载或传输步骤。
捕获处理状态以实现共享
HCatalog可以发布您的分析结果。因此,其他程序员可以通过“ REST”访问您的分析平台。您发布的模式对其他数据科学家也很有用。其他数据科学家将您的发现用作后续发现的输入。
将Hadoop与所有内容集成
Hadoop作为处理和存储环境为企业带来了很多机会。但是,要推动采用,它必须与现有工具一起使用并扩展现有工具。 Hadoop应该用作您的分析平台的输入或与您的运营数据存储和Web应用程序集成。组织应该享受Hadoop的价值,而不必学习全新的工具集。 REST服务使用熟悉的API和类似SQL的语言为企业打开了平台。企业数据管理系统使用HCatalog与Hadoop平台进行更深入的集成。
HCatalog体系结构
下图显示了HCatalog的总体体系结构。
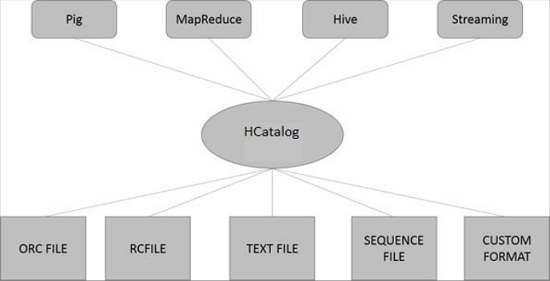
HCatalog支持以可以写入SerDe (串行化器-反序列化器)的任何格式读取和写入文件。默认情况下,HCatalog支持RCFile,CSV,JSON,SequenceFile和ORC文件格式。要使用自定义格式,必须提供InputFormat,OutputFormat和SerDe。
HCatalog建立在Hive Metastore之上,并包含Hive的DDL。 HCatalog为Pig和MapReduce提供读写接口,并使用Hive的命令行界面发布数据定义和元数据探索命令。