📌 相关文章
- Hive中的动态分区
- Hive中的动态分区(1)
- Hive动态分区概述
- Hive动态分区概述(1)
- Apache Hive – 静态分区示例
- Apache Hive – 静态分区示例(1)
- hive 中的分区和分桶代码 (1)
- 在分区 (1)
- 猪和Hive的区别
- 猪和Hive的区别(1)
- 猪和Hive的区别
- Hive – 删除表(1)
- Hive – 删除表
- Hive-创建表
- Hive-创建表(1)
- hive 中的分区和分桶代码 - 任何代码示例
- Hive-安装(1)
- Hive-安装
- 什么是Hive(1)
- 什么是Hive
- Hive更改表
- Hive更改表(1)
- 如何在Hive创建表?(1)
- 如何在Hive创建表?
- Hive中的存储桶(1)
- Hive中的存储桶
- Hive教程(1)
- Hive教程
- Hive-简介(1)
📜 在Hive中进行分区
📅 最后修改于: 2020-12-03 03:48:32 🧑 作者: Mango
在Hive中进行分区
Hive中的分区意味着根据特定列的值(例如日期,课程,城市或国家/地区)将表格分为几个部分。分区的优势在于,由于数据存储在切片中,因此查询响应时间变得更快。
我们知道Hadoop用于处理大量数据,因此始终需要使用最佳方法来处理它。 Hive中的分区就是最好的例子。
假设我们有一个在一所大学学习的1000万学生的数据。现在,我们必须获取特定课程的学生。如果使用传统方法,则必须遍历整个数据。这导致性能下降。在这种情况下,我们可以采用更好的方法,即在Hive中进行分区,然后根据特定列在不同的数据集中划分数据。
Hive中的分区可以通过两种方式执行:
静态分区
在静态或手动分区中,需要在将数据加载到表中时手动传递已分区列的值。因此,数据文件不包含分区列。
静态分区示例
- 首先,选择我们要在其中创建表的数据库。
hive> use test;
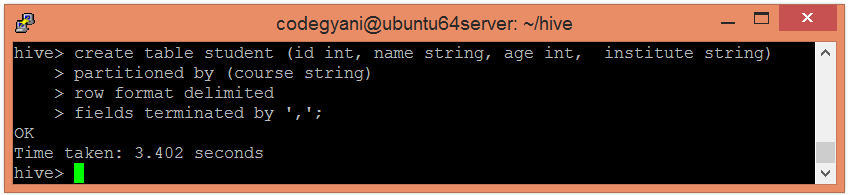
- 使用以下命令创建表并提供分区的列:-
hive> create table student (id int, name string, age int, institute string)
partitioned by (course string)
row format delimited
fields terminated by ',';
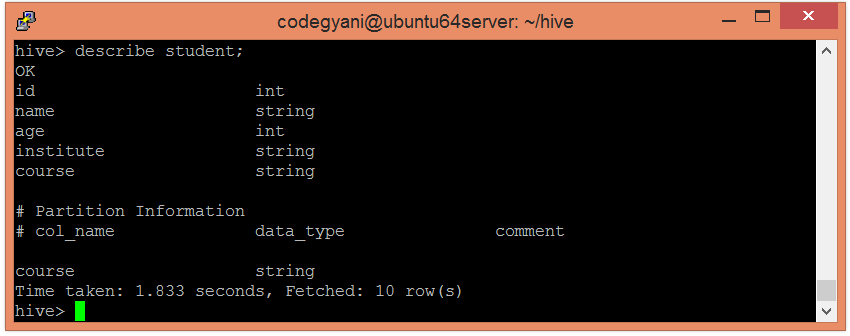
- 让我们检索与表关联的信息。
hive> describe student;
- 使用以下命令将数据加载到表中,并将分区列的值与它一起传递:-
hive> load data local inpath '/home/codegyani/hive/student_details1' into table student
partition(course= "java");
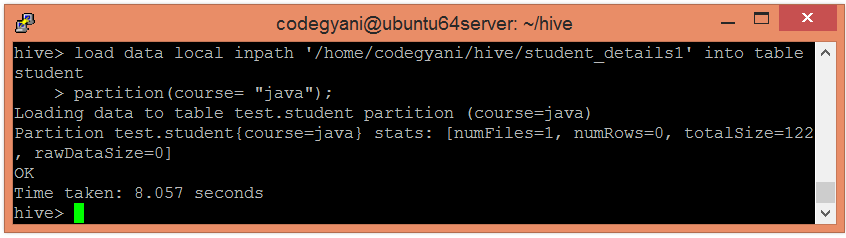
在这里,我们根据课程对研究所的学生进行划分。
- 使用以下命令将另一个文件的数据加载到同一表中,并将分区列的值与之一起传递:-
hive> load data local inpath '/home/codegyani/hive/student_details2' into table student
partition(course= "hadoop");
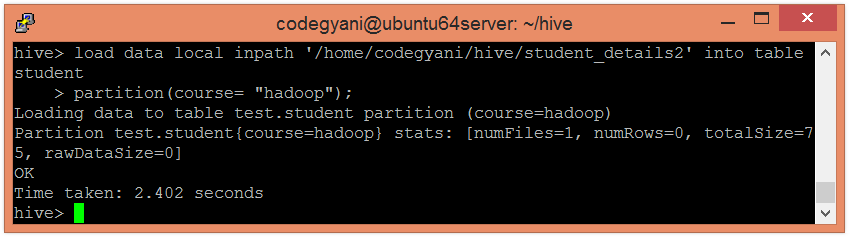
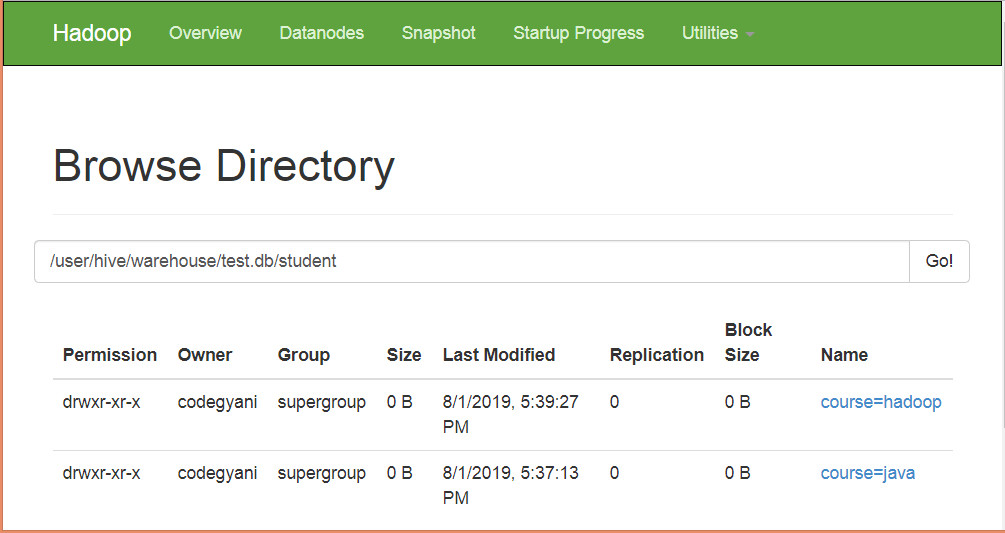
在下面的屏幕截图中,我们可以看到学生桌分为两类。
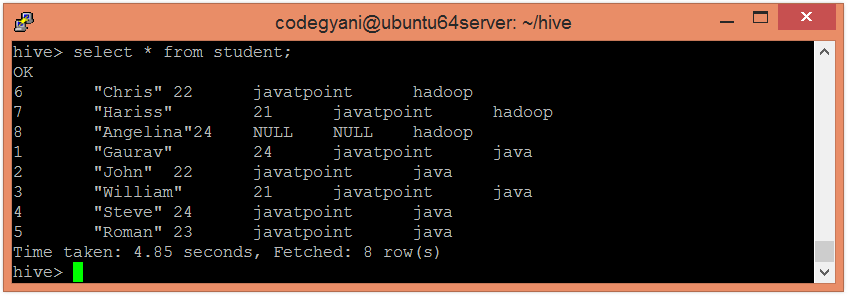
- 让我们使用以下命令来检索功能的全部数据:-
hive> select * from student;
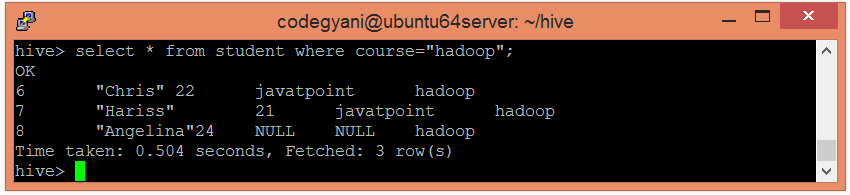
- 现在,尝试使用以下命令检索基于分区列的数据:-
hive> select * from student where course="java";
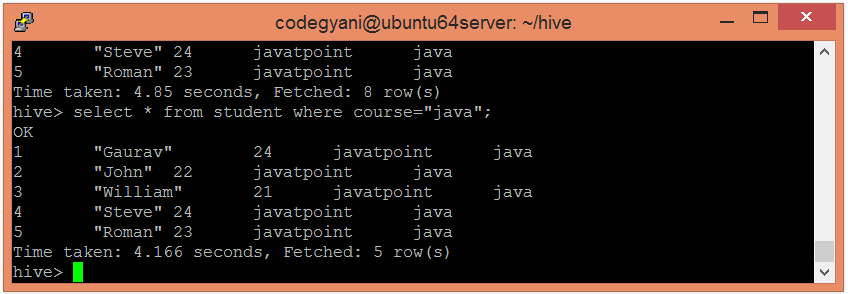
在这种情况下,我们不会检查整个数据。因此,这种方法改善了查询响应时间。
- 我们还使用以下命令来检索另一个分区数据集的数据:-
hive> select * from student where course= "hadoop";