Apache Hive的分区非常需要在扫描Hive表时提高性能。它允许在Hive上工作的用户查询Hive表的一小部分或所需部分。
假设我们有一个包含 5000 条记录的学生表,我们只想处理属于“A”部分的学生数据。然而,学生表包含属于所有部分(A、B、C、D)的学生记录,但通过分区,我们不需要处理所有这 5000 条记录。在这里,分区帮助我们根据学生的部分来分离学生的数据。这样做会增加执行查询的时间,并且我们不需要扫描“学生”表中可用的所有其他不必要的数据。
配置单元中的分区可以是静态的,也可以是动态的。在本文中,我们将在 hive 中实现静态分区。
静态分区的特点
- 分区是手动添加的所以也称为手动分区
- 与动态分区相比,静态分区中的数据加载速度更快,因此当我们要加载大量文件时,首选静态分区。
- 在静态分区中,根据我们要设置的分区加载单个文件。
- where 子句用于在静态分区中使用限制
- 允许在静态分区中更改分区,而动态分区不支持 Alter 语句。
要执行以下操作,请确保您的配置单元正在运行。以下是在本地系统上启动配置单元的步骤。
第 1 步:启动所有 Hadoop 守护进程
start-dfs.sh # this will start namenode, datanode and secondary namenode
start-yarn.sh # this will start node manager and resource manager
jps # To check running daemons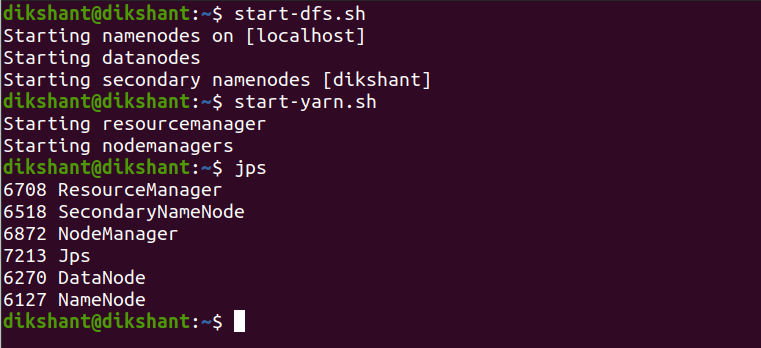
第 2 步:从终端启动 hive
hive
现在,我们都准备好执行快速演示了。
静态分区
在静态分区中,我们根据某些属性对表进行分区。我们用来分隔记录的属性或列不存在于加载到表中的实际数据中,但我们使用Hive可用的分区语句将它们分开。分区是手动分区的,这就是静态分区也称为手动分区的原因。下面是一个很好解释的例子,可以帮助你很好地理解它。
第 1 步:让我们创建一个具有以下属性(student_name、father_name 和百分比)的表 ‘student’ 并使用默认数据库中的 ‘section’ 对其进行分区。
注意:请勿在create table
CREATE TABLE student(student_name STRING ,father_name STRING ,percentage FLOAT)
partitioned by (section STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
第 2 步:描述表以查看有关表属性和分区列的信息
describe student;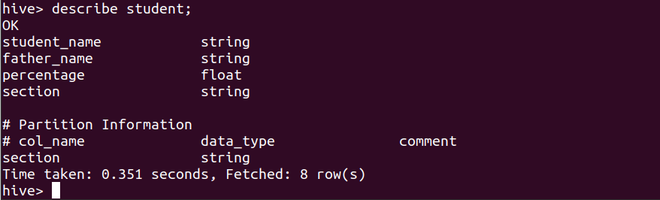
在这里我们可以看到section列已经被标记为partition属性,并且也被添加到了表属性列表中。
第 3 步:创建 4 个不同的文件,其中包含来自各个部分(学生 A、学生 B、学生 C、学生 D)的学生数据,确保永远不会将作为我们分区列的部分列添加到实际表中。
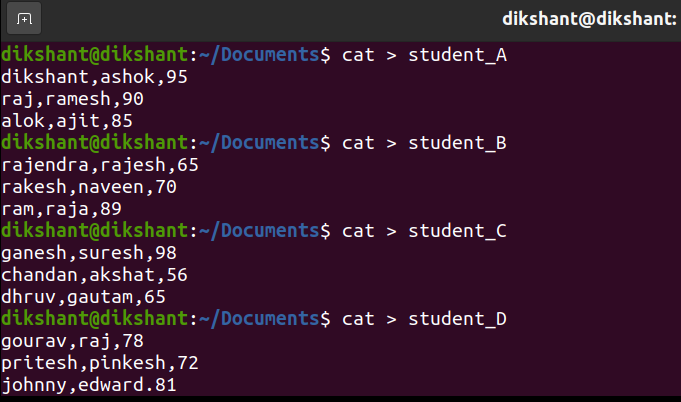
根据他们的部分创建学生表
第 4 步:将包含学生分段数据的 4 个不同文件中的数据与分区属性值一起加载到我们的学生表中。
一种。从 student_A 加载数据,分区为“A”
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_A' INTO TABLE student
partition(section = "A");湾加载来自 student_B 分区的数据,分区为“B”
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_B' INTO TABLE student
partition(section = 'B');C。加载来自 student_C 分区的数据,分区为“C”
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_C' INTO TABLE student
partition(section = 'C');d 。加载来自 student_D 分区的数据,分区为“D”
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_D' INTO TABLE student
partition(section = 'D');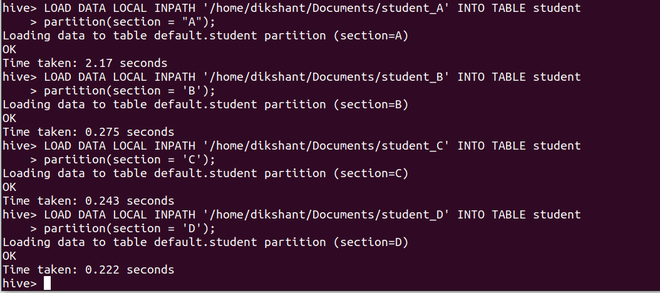
第 5 步:现在转到您的 HDFS(/user/hive/warehouse/) 并检查 student 表以查看分区是如何制作的。
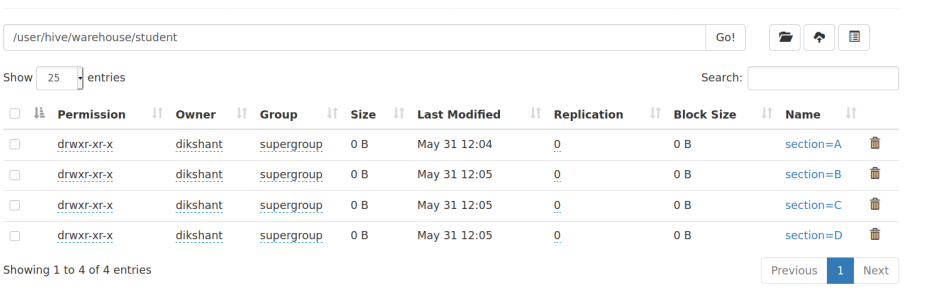
在这里我们可以很容易地观察到学生表被分区并根据他们的部分包含学生的数据。现在如果我们要处理student属于section_A的数据,我们不需要遍历整个表,因为它是分区的。每个分区都包含表中提到的分区的数据。
下面的选择查询将从学生表中选择所有内容。正如我们所观察到的,我们没有添加任何部分列,但由于它是在分区中手动提及的,因此添加了它。
select * from student;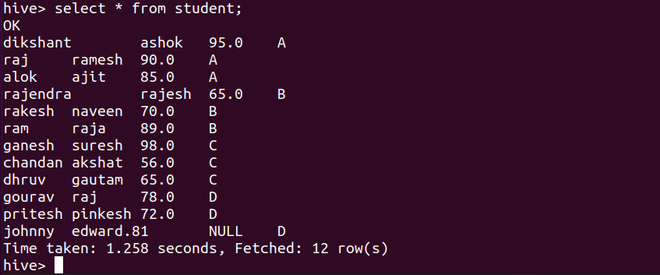
现在,如果我们使用 where 子句对这个学生表进行操作,如下所示。 Hive永远不会查询所有这 12 条记录。它只是对我们在这个学生表中所做的分区进行处理。在我们的例子中,它只会查询section=A分区。
select * from student where section="A";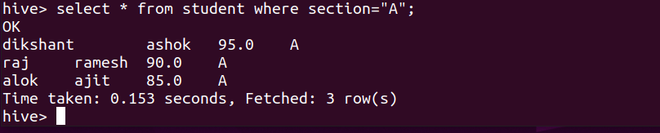
这就是我们在 hive 中执行静态分区的方式。