自然语言处理 |训练 Unigram 标注器
单个标记被称为Unigram ,例如 – hello;电影;编码。本文重点介绍unigram tagger 。
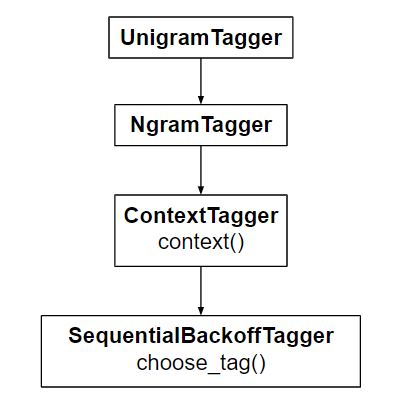
Unigram Tagger:为了确定词性标签,它只使用一个单词。 UnigramTagger继承自 NgramTagger,后者是ContextTagger的子类,后者继承自SequentialBackoffTagger 。因此, UnigramTagger是一个基于单个单词上下文的标注器。
代码 #1:训练 UnigramTagger。
# Loading Libraries
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
代码 #2:使用树库语料库的前 1000 个标记句子作为数据进行训练。
# Using data
train_sents = treebank.tagged_sents()[:1000]
# Initializing
tagger = UnigramTagger(train_sents)
# Lets see the first sentence
# (of the treebank corpus) as list
treebank.sents()[0]
输出 :
['Pierre',
'Vinken',
', ',
'61',
'years',
'old',
', ',
'will',
'join',
'the',
'board',
'as',
'a',
'nonexecutive',
'director',
'Nov.',
'29',
'.']
代码#3:训练后查找标记结果。
tagger.tag(treebank.sents()[0])
输出 :
[('Pierre', 'NNP'),
('Vinken', 'NNP'),
(', ', ', '),
('61', 'CD'),
('years', 'NNS'),
('old', 'JJ'),
(', ', ', '),
('will', 'MD'),
('join', 'VB'),
('the', 'DT'),
('board', 'NN'),
('as', 'IN'),
('a', 'DT'),
('nonexecutive', 'JJ'),
('director', 'NN'),
('Nov.', 'NNP'),
('29', 'CD'),
('.', '.')]
代码是如何工作的?
UnigramTagger从标记句子列表中构建上下文模型。因为UnigramTagger继承自ContextTagger ,所以它必须实现一个context()方法,而不是提供一个choose_tag()方法,该方法采用与choose_tag()相同的三个参数。上下文标记用于创建模型,并在创建模型后查找最佳标签。上图中也以图形方式解释了这一点。
覆盖上下文模型——
所有从ContextTagger继承而不是训练自己的模型的标注器都可以采用预先构建的模型。这个模型只是一个将上下文键映射到标签的Python字典。上下文键(UnigramTagger 中的单个词)将取决于ContextTagger subclass从其context()方法返回的内容。代码 #4:覆盖上下文模型
tagger = UnigramTagger(model ={'Pierre': 'NN'})
tagger.tag(treebank.sents()[0])
输出 :
[('Pierre', 'NN'),
('Vinken', None),
(', ', None),
('61', None),
('years', None),
('old', None),
(', ', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)]