毫升 |初始网络V1
Inception net 在 CNN 分类器中取得了一个里程碑,当时之前的模型只是为了提高性能和准确性而更深入,但要牺牲计算成本。另一方面,Inception 网络经过精心设计。它使用了很多技巧来提高性能,无论是速度还是准确性。它是 2014 年 ImageNet 大规模视觉识别竞赛图像分类竞赛的获胜者,与 ZFNet(2013 年的获胜者)、AlexNet(2012 年的获胜者)相比有显着的改进,并且错误率相对较低。 VGGNet(2014 年亚军)。
VGGNet 等更深层次的 CNN 模型面临的主要问题是:
- 尽管以前的网络(如 VGG)在 ImageNet 数据集上取得了显着的准确性,但由于深度架构,部署这些类型的模型在计算上非常昂贵。
- 非常深的网络容易过拟合。在整个网络中传递梯度更新也很困难。
在深入研究 Inception Net 模型之前,有必要了解 Inception 网络中使用的一个重要概念:
1 X 1 卷积: 1×1卷积简单地将输入像素及其所有相应通道映射到输出像素。 1×1卷积作为降维模块,在一定程度上减少了计算量。
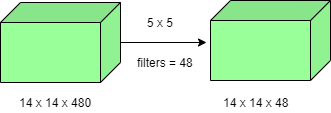
这里涉及的操作数是(14×14×48)×(5×5×480)=112.9M
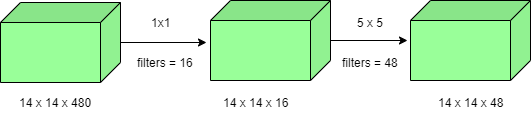
1×1卷积运算次数= (14×14×16)×(1×1×480)=1.5M
5×5卷积运算次数= (14×14×48)×(5×5×16)=3.8M
加法后得到, 1.5M + 3.8M = 5.3M
这比 112.9M 小得多!因此,1×1 卷积有助于减小模型大小,这也有助于减少过拟合问题。
降维的初始模型: 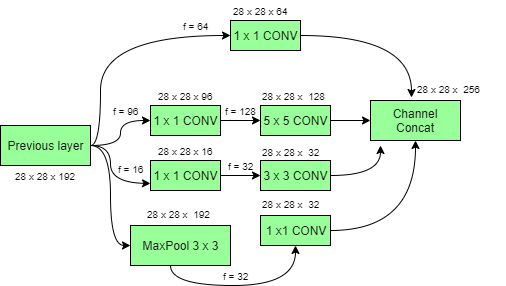
深度卷积网络的计算成本很高。但是,通过引入 1 x 1 卷积可以大大降低计算成本。在这里,通过在3×3和5×5卷积之前添加额外的 1×1卷积来限制输入通道的数量。虽然添加一个额外的操作似乎违反直觉,但1×1卷积比5×5卷积便宜得多。请注意, 1×1卷积是在最大池化层之后而不是之前引入的。最后,网络中的所有通道连接在一起,即(28 x 28 x (64 + 128 + 32 + 32)) = 28 x 28 x 256。
Inception Network 的 GoogLeNet 架构:
这个架构总共有22层!使用降维的初始模块,构建神经网络架构。这就是众所周知的GoogLeNet (Inception v1) 。 GoogLeNet 有9 个这样的初始模块线性拟合。它有22层深( 27层,包括池化层)。在架构的最后,全连接层被全局平均池化所取代,该池化计算每个特征图的平均值。这确实大大减少了参数的总数。
因此,Inception Net 是对先前版本的 CNN 模型的胜利。它在 ImageNet 上达到了 top-5 的精度,在不影响速度和精度的情况下,在很大程度上降低了计算成本。