📌 相关文章
- 使用Python进行数据分析和可视化2(1)
- 使用Python进行数据分析和可视化 |设置 2(1)
- 使用Python进行数据分析和可视化 |设置 2
- 使用Python Pandas进行数据分析和可视化(1)
- 使用Python Pandas进行数据分析和可视化
- 大数据分析-数据可视化
- 大数据分析-数据可视化(1)
- 使用Python在 Pandas 中进行数据分析(1)
- Python | 使用Pandas进行数据分析
- 使用Python在 Pandas 中进行数据分析
- Python | 使用Pandas进行数据分析(1)
- 使用 Pandas 进行数据分析(1)
- 使用 Pandas 进行数据分析
- Excel数据分析-数据可视化
- Excel数据分析-数据可视化(1)
- 数据可视化和数据分析之间的区别(1)
- 数据可视化和数据分析之间的区别(1)
- 数据可视化和数据分析之间的区别
- 数据可视化和数据分析之间的区别
- 数据分析的使用
- 数据分析的使用(1)
- Python|使用Python可视化 O(n)(1)
- Python|使用Python可视化 O(n)
- 使用 SciPy 进行数据分析(1)
- 使用 SciPy 进行数据分析
- 使用Python Seaborn 进行数据可视化(1)
- 使用Python Seaborn 进行数据可视化
- 数据分析和数据分析的区别
- 数据分析和数据分析的区别(1)
📜 使用Python进行数据分析和可视化2
📅 最后修改于: 2020-04-17 07:06:56 🧑 作者: Mango
先决条件:Python中的NumPy,数据可视化分析与Python | 1
1.以CSV格式存储DataFrame:
熊猫提供to.csv('filename', index = "False|True")了将DataFrame写入CSV文件的功能。这filename是您要创建的CSV文件的名称,并index告诉您是否应覆盖DataFrame的索引(如果默认)。如果设置,则索引不会被覆盖。默认情况下,索引的值将覆盖索引。 index = FalseTRUE
范例:
import pandas as pd
# 将三个系列分配给s1,s2,s3
s1 = pd.Series([0, 4, 8])
s2 = pd.Series([1, 5, 9])
s3 = pd.Series([2, 6, 10])
# 取得索引和列值
dframe = pd.DataFrame([s1, s2, s3])
# 分配列名
dframe.columns =['芒果', 'For', '芒果']
# 将数据写入CSV文件
dframe.to_csv('芒果文档.csv', index = False)
dframe.to_csv('芒果文档1.csv', index = True)输出:
芒果文档1.csv 
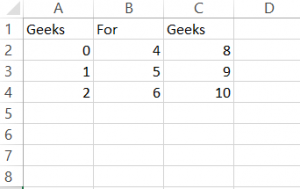
芒果文档2.csv 

2.处理丢失的数据
- 数据分析阶段还具有处理数据集中缺失数据的能力,因此,熊猫也同样能够达到预期。这是发挥作用
dropna和/或fillna方法的地方。在处理丢失的数据时,作为数据分析师,您应该删除包含NaN值的列(dropna方法),或者使用整个列条目的均值或众数填充丢失的数据(fillna方法)。具有重要意义,并取决于数据和影响将在我们的结果中产生。
删除丢失的数据:
考虑这是下面的代码生成的DataFrame:
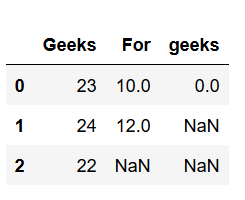

import pandas as pd
# 创建一个DataFrame
dframe = pd.DataFrame({'芒果': [23, 24, 22],
'For': [10, 12, np.nan],
'芒果': [0, np.nan, np.nan]},
columns =['芒果', 'For', '芒果'])
# 这将删除所有具有NAN值的行
# 如果未定义轴,则沿着行,即axis = 0
dframe.dropna(inplace = True)
print(dframe)
# 如果轴等于1
dframe.dropna(axis = 1, inplace = True)
print(dframe)输出:
轴= 0

 轴= 1
轴= 1


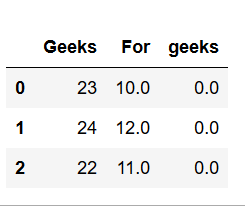
填写丢失的值:
现在,使用数据的均值或众数替换任何NaN值fillna,这可以根据需要替换特定列或整个DataFrame中的所有NaN值。
import numpy as np
import pandas as pd
# 创建一个DataFrame
dframe = pd.DataFrame({'芒果': [23, 24, 22],
'For': [10, 12, np.nan],
'芒果': [0, np.nan, np.nan]},
columns = ['芒果', 'For', '芒果'])
# 使用完整的Dataframe函数的fillna将应用于每一列
dframe.fillna(value = dframe.mean(), inplace = True)
print(dframe)
# 一栏填充值
dframe['For'].fillna(value = dframe['For'].mean(),
inplace = True)
print(dframe)输出:

3. Groupby方法(聚合):
groupby方法允许我们根据任何行或列将数据分组在一起,因此我们可以进一步应用聚合函数来分析数据。使用映射器(dict或键函数,将给定函数应用于组,将结果作为序列返回)或按一系列列对系列进行分组。
考虑这是下面的代码生成的DataFrame:
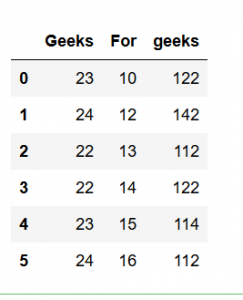

import pandas as pd
import numpy as np
# 创建DataFrame
dframe = pd.DataFrame({'芒果': [23, 24, 22, 22, 23, 24],
'For': [10, 12, 13, 14, 15, 16],
'芒果': [122, 142, 112, 122, 114, 112]},
columns = ['芒果', 'For', '芒果'])
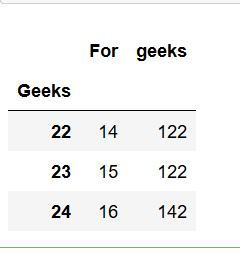
# 应用groupby和聚合函数max查找列的最大值
print(dframe.groupby(['芒果']).max())输出: