📌 相关文章
- PyTorch-递归神经网络
- 循环神经网络 pytorch - Python (1)
- 循环神经网络 pytorch - Python 代码示例
- PyTorch-神经网络基础(1)
- PyTorch-神经网络基础
- TensorFlow-递归神经网络(1)
- TensorFlow-递归神经网络
- 如何保存神经网络 pytorch - Python 代码示例
- PyTorch-卷积神经网络(1)
- PyTorch-卷积神经网络
- PyTorch-实现第一个神经网络(1)
- PyTorch-实现第一个神经网络
- 在 PyTorch 中调整神经网络的学习率
- 在 PyTorch 中调整神经网络的学习率(1)
- CNTK-递归神经网络
- CNTK-递归神经网络(1)
- PyTorch-功能块的神经网络
- PyTorch-功能块的神经网络(1)
- PyTorch (1)
- 使用 PyTorch 使用验证训练神经网络(1)
- 使用 PyTorch 使用验证训练神经网络
- TensorFlow中的递归神经网络(RNN)(1)
- TensorFlow中的递归神经网络(RNN)
- pytorch 逆 - Python (1)
- pytorch 1.7 - Python (1)
- C-递归(1)
- C++ 递归(1)
- 头与尾递归 (1)
- C-递归
📜 PyTorch-递归神经网络
📅 最后修改于: 2020-12-10 05:23:58 🧑 作者: Mango
递归神经网络是一种遵循顺序方法的面向深度学习的算法。在神经网络中,我们始终假设每个输入和输出都独立于所有其他层。这些类型的神经网络称为递归,因为它们以顺序的方式执行数学计算,从而完成一项任务。
下图指定了递归神经网络的完整方法和工作方式-
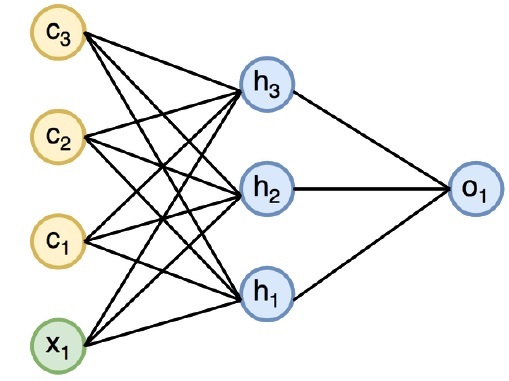
在上图中,将c1,c2,c3和x1视为输入,其中包括一些隐藏的输入值,即分别传递o1输出的h1,h2和h3。现在,我们将重点介绍如何在递归神经网络的帮助下实现PyTorch以创建正弦波。
在训练过程中,我们将遵循训练模型的方法,一次只有一个数据点。输入序列x由20个数据点组成,目标序列被认为与输入序列相同。
第1步
使用以下代码导入用于实现递归神经网络的必要软件包-
import torch
from torch.autograd import Variable
import numpy as np
import pylab as pl
import torch.nn.init as init
第2步
我们将设置输入层大小为7的模型超参数。将有6个上下文神经元和1个输入神经元用于创建目标序列。
dtype = torch.FloatTensor
input_size, hidden_size, output_size = 7, 6, 1
epochs = 300
seq_length = 20
lr = 0.1
data_time_steps = np.linspace(2, 10, seq_length + 1)
data = np.sin(data_time_steps)
data.resize((seq_length + 1, 1))
x = Variable(torch.Tensor(data[:-1]).type(dtype), requires_grad=False)
y = Variable(torch.Tensor(data[1:]).type(dtype), requires_grad=False)
我们将生成训练数据,其中x是输入数据序列,y是必需的目标序列。
第三步
在递归神经网络中使用均值为零的正态分布初始化权重。 W1将表示接受输入变量,而w2将表示生成的输出,如下所示-
w1 = torch.FloatTensor(input_size,
hidden_size).type(dtype)
init.normal(w1, 0.0, 0.4)
w1 = Variable(w1, requires_grad = True)
w2 = torch.FloatTensor(hidden_size, output_size).type(dtype)
init.normal(w2, 0.0, 0.3)
w2 = Variable(w2, requires_grad = True)
第4步
现在,创建唯一定义神经网络的前馈函数非常重要。
def forward(input, context_state, w1, w2):
xh = torch.cat((input, context_state), 1)
context_state = torch.tanh(xh.mm(w1))
out = context_state.mm(w2)
return (out, context_state)
第5步
下一步是开始循环神经网络的正弦波实现的训练过程。外循环遍历每个循环,内循环遍历序列的元素。在这里,我们还将计算均方误差(MSE),这有助于预测连续变量。
for i in range(epochs):
total_loss = 0
context_state = Variable(torch.zeros((1, hidden_size)).type(dtype), requires_grad = True)
for j in range(x.size(0)):
input = x[j:(j+1)]
target = y[j:(j+1)]
(pred, context_state) = forward(input, context_state, w1, w2)
loss = (pred - target).pow(2).sum()/2
total_loss += loss
loss.backward()
w1.data -= lr * w1.grad.data
w2.data -= lr * w2.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
context_state = Variable(context_state.data)
if i % 10 == 0:
print("Epoch: {} loss {}".format(i, total_loss.data[0]))
context_state = Variable(torch.zeros((1, hidden_size)).type(dtype), requires_grad = False)
predictions = []
for i in range(x.size(0)):
input = x[i:i+1]
(pred, context_state) = forward(input, context_state, w1, w2)
context_state = context_state
predictions.append(pred.data.numpy().ravel()[0])
第6步
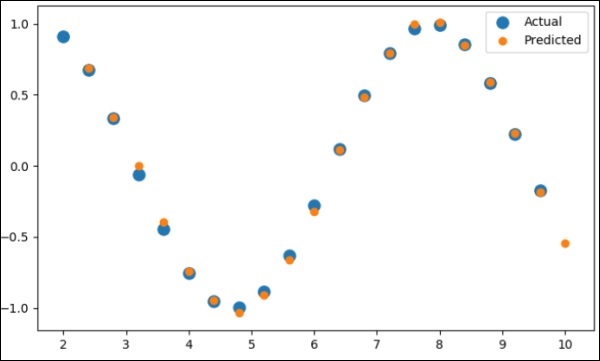
现在,是时候绘制正弦波作为所需方式了。
pl.scatter(data_time_steps[:-1], x.data.numpy(), s = 90, label = "Actual")
pl.scatter(data_time_steps[1:], predictions, label = "Predicted")
pl.legend()
pl.show()
输出
上述过程的输出如下-