📌 相关文章
- PyTorch的基础
- PyTorch的基础(1)
- 循环神经网络 pytorch - Python (1)
- PyTorch-递归神经网络
- PyTorch-递归神经网络
- PyTorch-递归神经网络(1)
- 循环神经网络 pytorch - Python 代码示例
- 如何保存神经网络 pytorch - Python 代码示例
- PyTorch-卷积神经网络(1)
- PyTorch-卷积神经网络
- PyTorch-实现第一个神经网络
- PyTorch-实现第一个神经网络(1)
- 在 PyTorch 中调整神经网络的学习率
- 在 PyTorch 中调整神经网络的学习率(1)
- PyTorch-功能块的神经网络(1)
- PyTorch-功能块的神经网络
- PyTorch (1)
- 使用 PyTorch 使用验证训练神经网络
- 使用 PyTorch 使用验证训练神经网络(1)
- C++基础
- C++基础(1)
- pytorch 逆 - Python (1)
- pytorch 1.7 - Python (1)
- 使用 Pytorch Lightning 训练神经网络
- 使用 Pytorch Lightning 训练神经网络(1)
- 基础 CSS 下拉基础(1)
- 基础 CSS 下拉基础
- 神经网络的应用
- 神经网络的应用
📜 PyTorch-神经网络基础
📅 最后修改于: 2020-12-10 05:21:07 🧑 作者: Mango
神经网络的主要原理包括基本元素的集合,即人工神经元或感知器。它包括几个基本输入,例如x1,x2…..xn,如果总和大于激活电位,它将产生一个二进制输出。
下面提到了样本神经元的示意图-
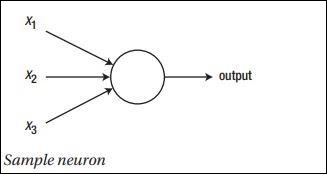
产生的输出可以被认为是具有激活电位或偏置的加权和。
$$ Output = \ sum_jw_jx_j + Bias $$
下面描述了典型的神经网络架构-
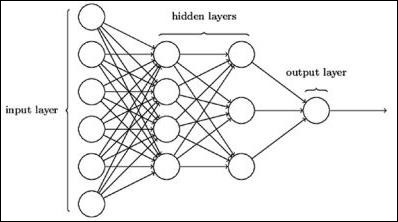
输入和输出之间的层称为隐藏层,并且层之间连接的密度和类型是配置。例如,完全连接的配置将L层的所有神经元连接到L + 1的神经元。对于更明显的定位,我们只能将一个本地社区(例如9个神经元)连接到下一层。图1-9显示了两个隐藏的层,它们具有密集的连接。
各种类型的神经网络如下-
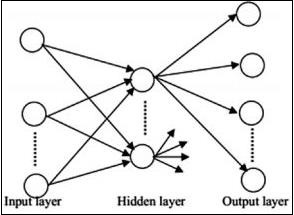
前馈神经网络
前馈神经网络包括神经网络家族的基本单元。此类神经网络中的数据移动是通过当前的隐藏层从输入层到输出层。一层的输出用作输入层,对网络体系结构中的任何类型的环路都有限制。
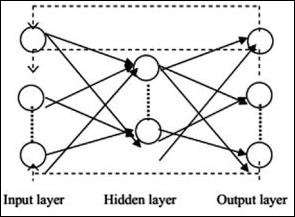
递归神经网络
递归神经网络是数据模式因此在一段时间内发生变化的时候。在RNN中,同一层应用于接受输入参数并在指定的神经网络中显示输出参数。
可以使用torch.nn包构建神经网络。
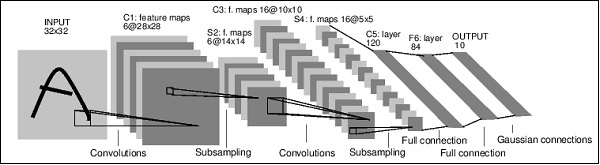
这是一个简单的前馈网络。它获取输入,将其一层又一层地馈入,然后最终给出输出。
借助PyTorch,我们可以将以下步骤用于神经网络的典型训练过程-
- 定义具有一些可学习的参数(或权重)的神经网络。
- 遍历输入数据集。
- 通过网络处理输入。
- 计算损失(输出正确的距离)。
- 将梯度传播回网络的参数。
- 更新网络的权重,通常使用如下所示的简单更新
rule: weight = weight -learning_rate * gradient