📌 相关文章
- 时间序列Python库
- Python时间序列(1)
- Python时间序列
- 时间序列Python库(1)
- 时间序列-编程语言
- 时间序列-编程语言(1)
- Pandas 时间序列
- 在 laravel 中验证时间 - PHP (1)
- 在 laravel 中验证时间 - PHP 代码示例
- 时间序列教程
- 时间序列教程(1)
- 验证 (1)
- 去验证器 (1)
- 验证 (1)
- 验证 (1)
- 时间序列-应用
- 时间序列-应用(1)
- 时间序列-简介(1)
- 时间序列-简介
- 在 R 中合并时间序列
- 在 R 中合并时间序列(1)
- 计算对数组进行排序的最前移或最后移出的最小次数(1)
- 计算对数组进行排序的最前移或最后移出的最小次数
- 计算对数组进行排序的最前移或最后移出的最小次数(1)
- 计算对数组进行排序的最前移或最后移出的最小次数
- 讨论时间序列(1)
- 讨论时间序列
- 如何在javascript中验证时间戳格式(1)
- R-时间序列分析(1)
📜 时间序列-前移验证
📅 最后修改于: 2020-12-10 06:27:04 🧑 作者: Mango
在时间序列建模中,随着时间的推移,预测变得越来越不准确,因此,当模型可用于进一步的预测时,采用实际数据重新训练模型是一种更为现实的方法。由于训练统计模型并不耗时,因此,前向验证是获得最准确结果的最优选解决方案。
让我们对数据进行一步向前验证,并将其与我们之前获得的结果进行比较。
在[333]中:
prediction = []
data = train.values
for t In test.values:
model = (ExponentialSmoothing(data).fit())
y = model.predict()
prediction.append(y[0])
data = numpy.append(data, t)
在[335]中:
test_ = pandas.DataFrame(test)
test_['predictionswf'] = prediction
在[341]中:
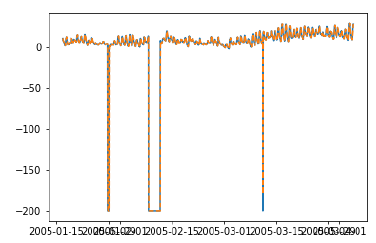
plt.plot(test_['T'])
plt.plot(test_.predictionswf, '--')
plt.show()
在[340]中:
error = sqrt(metrics.mean_squared_error(test.values,prediction))
print ('Test RMSE for Triple Exponential Smoothing with Walk-Forward Validation: ', error)
Test RMSE for Triple Exponential Smoothing with Walk-Forward Validation: 11.787532205759442
我们可以看到我们的模型现在性能明显更好。实际上,趋势是如此接近,以至于绘图上的预测与实际值重叠。您也可以尝试在ARIMA模型上应用前向验证。