- 使用 Logistic 回归进行位置预测
- 使用线性回归预测python代码示例
- 如何在 r 中进行预测 (1)
- 使用 Keras 的 Softmax 回归
- 使用 Keras 的 Softmax 回归(1)
- 如何在 r 中进行预测 - 无论代码示例
- Keras-使用LSTM RNN进行时间序列预测
- Keras-使用LSTM RNN进行时间序列预测(1)
- 毫升 |使用线性回归进行降雨预测
- 毫升 |使用线性回归进行降雨预测(1)
- keras (1)
- keras 模型预测输入张量列表 - Python (1)
- 在Python中使用 Keras 进行图像处理
- keras 模型预测输入张量列表 - Python 代码示例
- Python|使用 Keras 进行图像分类(1)
- Python|使用 Keras 进行图像分类
- 使用 python seaborn 进行回归 - Python (1)
- 使用Tensorflow进行线性回归(1)
- 使用Tensorflow进行线性回归
- 使用Tensorflow进行线性回归
- 回归python(1)
- 使用 python seaborn 进行回归 - Python 代码示例
- Keras-模型评估和模型预测(1)
- Keras-模型评估和模型预测
- 毫升 |使用逻辑回归预测心脏病。(1)
- 毫升 |使用逻辑回归预测心脏病。
- 使用PyTorch进行线性回归
- 使用PyTorch进行线性回归(1)
- 毫升 |使用 Keras 进行字加密
📅 最后修改于: 2020-12-11 04:59:58 🧑 作者: Mango
在本章中,让我们编写一个基于MPL的简单ANN进行回归预测。到目前为止,我们仅完成了基于分类的预测。现在,我们将尝试通过分析先前(连续)的值及其影响因素来预测下一个可能的值。
回归MPL可以表示如下-
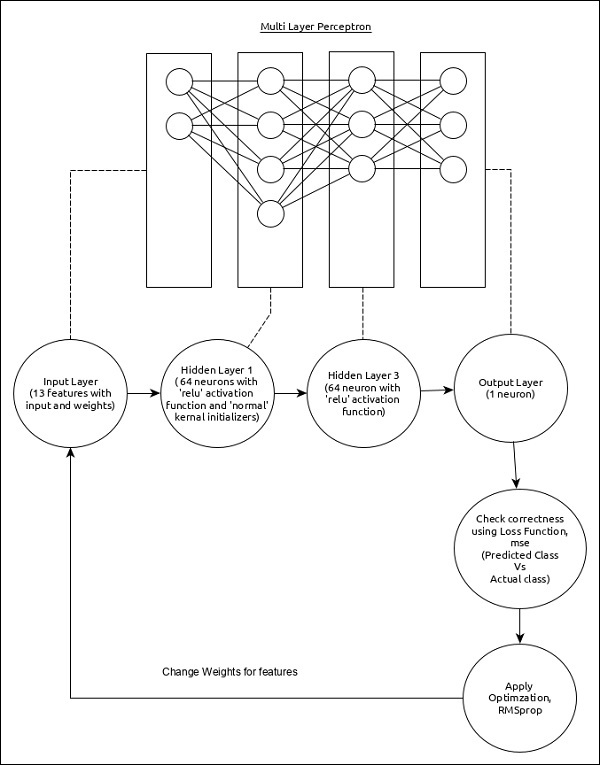
该模型的核心特征如下-
-
输入层由(13,)个值组成。
-
第一层, Dense由64个单元和带有“正常”内核初始化程序的“ relu”激活函数。
-
第二层, Dense由64个单元和“ relu”激活函数。
-
输出层, Dense由1个单元组成。
-
使用mse作为损失函数。
-
使用RMSprop作为优化程序。
-
使用准确性作为指标。
-
使用128作为批处理大小。
-
使用500作为时代。
步骤1-导入模块
让我们导入必要的模块。
import keras
from keras.datasets import boston_housing
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import RMSprop
from keras.callbacks import EarlyStopping
from sklearn import preprocessing
from sklearn.preprocessing import scale
第2步-加载数据
让我们导入波士顿住房数据集。
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()
这里,
boston_housing是Keras提供的数据集。它代表了波士顿地区的住房信息收集,每个都有13个特征。
步骤3-处理数据
让我们根据模型更改数据集,以便可以将其输入模型。可以使用以下代码更改数据-
x_train_scaled = preprocessing.scale(x_train)
scaler = preprocessing.StandardScaler().fit(x_train)
x_test_scaled = scaler.transform(x_test)
在这里,我们已经使用sklearn.preprocessing.scale函数对训练数据进行了标准化。 preprocessing.StandardScaler()。fit函数返回具有训练数据的标准化均值和标准偏差的标量,我们可以使用scalar.transform函数将其应用于测试数据。这也将使用与训练数据相同的设置来标准化测试数据。
步骤4-创建模型
让我们创建实际的模型。
model = Sequential()
model.add(Dense(64, kernel_initializer = 'normal', activation = 'relu',
input_shape = (13,)))
model.add(Dense(64, activation = 'relu')) model.add(Dense(1))
第5步-编译模型
让我们使用选定的损失函数,优化器和指标来编译模型。
model.compile(
loss = 'mse',
optimizer = RMSprop(),
metrics = ['mean_absolute_error']
)
步骤6-训练模型
让我们使用fit()方法训练模型。
history = model.fit(
x_train_scaled, y_train,
batch_size=128,
epochs = 500,
verbose = 1,
validation_split = 0.2,
callbacks = [EarlyStopping(monitor = 'val_loss', patience = 20)]
)
在这里,我们使用了回调函数EarlyStopping 。此回调的目的是监视每个时期的损失值,并将其与以前的时期损失值进行比较,以找到训练方面的改进。如果耐心时间没有改善,则整个过程将停止。
执行应用程序将给出以下信息作为输出-
Train on 323 samples, validate on 81 samples Epoch 1/500 2019-09-24 01:07:03.889046: I
tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this
TensorFlow binary was not co mpiled to use: AVX2 323/323
[==============================] - 0s 515us/step - loss: 562.3129
- mean_absolute_error: 21.8575 - val_loss: 621.6523 - val_mean_absolute_erro
r: 23.1730 Epoch 2/500
323/323 [==============================] - 0s 11us/step - loss: 545.1666
- mean_absolute_error: 21.4887 - val_loss: 605.1341 - val_mean_absolute_error
: 22.8293 Epoch 3/500
323/323 [==============================] - 0s 12us/step - loss: 528.9944
- mean_absolute_error: 21.1328 - val_loss: 588.6594 - val_mean_absolute_error
: 22.4799 Epoch 4/500
323/323 [==============================] - 0s 12us/step - loss: 512.2739
- mean_absolute_error: 20.7658 - val_loss: 570.3772 - val_mean_absolute_error
: 22.0853 Epoch 5/500
323/323 [==============================] - 0s 9us/step - loss: 493.9775
- mean_absolute_error: 20.3506 - val_loss: 550.9548 - val_mean_absolute_error: 21.6547
..........
..........
..........
Epoch 143/500
323/323 [==============================] - 0s 15us/step - loss: 8.1004
- mean_absolute_error: 2.0002 - val_loss: 14.6286 - val_mean_absolute_error:
2. 5904 Epoch 144/500
323/323 [==============================] - 0s 19us/step - loss: 8.0300
- mean_absolute_error: 1.9683 - val_loss: 14.5949 - val_mean_absolute_error:
2. 5843 Epoch 145/500
323/323 [==============================] - 0s 12us/step - loss: 7.8704
- mean_absolute_error: 1.9313 - val_loss: 14.3770 - val_mean_absolute_error: 2. 4996
步骤7-评估模型
让我们使用测试数据评估模型。
score = model.evaluate(x_test_scaled, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
执行上面的代码将输出以下信息-
Test loss: 21.928471583946077 Test accuracy: 2.9599233234629914
步骤8-预测
最后,使用以下测试数据进行预测-
prediction = model.predict(x_test_scaled)
print(prediction.flatten())
print(y_test)
上述应用程序的输出如下-
[ 7.5612316 17.583357 21.09344 31.859276 25.055613 18.673872 26.600405 22.403967 19.060272 22.264952
17.4191 17.00466 15.58924 41.624374 20.220217 18.985565 26.419338 19.837091 19.946192 36.43445
12.278508 16.330965 20.701359 14.345301 21.741161 25.050423 31.046402 27.738455 9.959419 20.93039
20.069063 14.518344 33.20235 24.735163 18.7274 9.148898 15.781284 18.556862 18.692865 26.045074
27.954073 28.106823 15.272034 40.879818 29.33896 23.714525 26.427515 16.483374 22.518442 22.425386
33.94826 18.831465 13.2501955 15.537227 34.639984 27.468002 13.474407 48.134598 34.39617
22.8503124.042334 17.747198 14.7837715 18.187277 23.655672 22.364983 13.858193 22.710032 14.371148
7.1272087 35.960033 28.247292 25.3014 14.477208 25.306196 17.891165 20.193708 23.585173 34.690193
12.200583 20.102983 38.45882 14.741723 14.408362 17.67158 18.418497 21.151712 21.157492 22.693687
29.809034 19.366991 20.072294 25.880817 40.814568 34.64087 19.43741 36.2591 50.73806 26.968863 43.91787
32.54908 20.248306 ] [ 7.2 18.8 19. 27. 22.2 24.5 31.2 22.9 20.5 23.2 18.6 14.5 17.8 50. 20.8 24.3 24.2
19.8 19.1 22.7 12. 10.2 20. 18.5 20.9 23. 27.5 30.1 9.5 22. 21.2 14.1 33.1 23.4 20.1 7.4 15.4 23.8 20.1
24.5 33. 28.4 14.1 46.7 32.5 29.6 28.4 19.8 20.2 25. 35.4 20.3 9.7 14.5 34.9 26.6 7.2 50. 32.4 21.6 29.8
13.1 27.5 21.2 23.1 21.9 13. 23.2 8.1 5.6 21.7 29.6 19.6 7. 26.4 18.9 20.9 28.1 35.4 10.2 24.3 43.1 17.6
15.4 16.2 27.1 21.4 21.5 22.4 25. 16.6 18.6 22. 42.8 35.1 21.5 36. 21.9 24.1 50. 26.7 25. ]
两种阵列的输出相差约10-30%,这表明我们的模型在合理范围内进行了预测。