📌 相关文章
- 使用Keras进行深度学习-保存模型(1)
- 使用Keras进行深度学习-保存模型
- 使用Keras进行深度学习-训练模型(1)
- 使用Keras进行深度学习-训练模型
- 使用Keras进行深度学习-深度学习(1)
- 使用Keras进行深度学习-深度学习
- 使用Keras进行深度学习-讨论
- 使用Keras进行深度学习-设置项目(1)
- 使用Keras进行深度学习-设置项目
- Keras-深度学习(1)
- Keras-深度学习
- Keras进行深度学习-简介(1)
- Keras进行深度学习-简介
- Keras中的深度学习-建立深度学习模型
- Keras中的深度学习-建立深度学习模型(1)
- Keras-模型编译(1)
- Keras-模型编译
- 使用Keras进行深度学习-有用的资源(1)
- 使用Keras进行深度学习-有用的资源
- 使用Keras进行深度学习-准备数据
- Keras深度学习教程(1)
- Keras深度学习教程
- 使用Keras进行深度学习-导入库(1)
- 使用Keras进行深度学习-导入库
- ML – 在 Keras 中保存深度学习模型
- ML – 在 Keras 中保存深度学习模型(1)
- Keras进行深度学习-结论
- Keras进行深度学习-结论(1)
- Keras-深度学习概述
📜 使用Keras进行深度学习-编译模型
📅 最后修改于: 2020-12-11 05:04:54 🧑 作者: Mango
使用一个称为compile的单个方法调用执行编译。
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
编译方法需要几个参数。 loss参数被指定为类型‘categorical_crossentropy’ 。指标参数设置为“准确性” ,最后我们使用亚当优化器来训练网络。此阶段的输出如下所示-

现在,我们准备将数据输入到我们的网络中。
加载数据中
如前所述,我们将使用Keras提供的mnist数据集。当我们将数据加载到系统中时,我们会将其拆分为训练和测试数据。通过调用load_data方法来加载数据,如下所示:
(X_train, y_train), (X_test, y_test) = mnist.load_data()
此阶段的输出如下所示:

现在,我们将学习加载的数据集的结构。
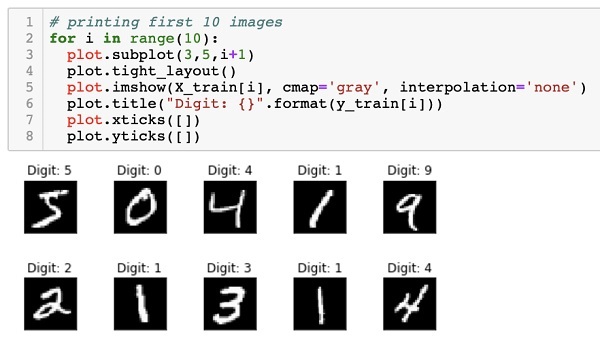
提供给我们的数据是大小为28 x 28像素的图形图像,每个图像包含0到9之间的一位数字。我们将在控制台上显示前十个图像。这样做的代码如下-
# printing first 10 images
for i in range(10):
plot.subplot(3,5,i+1)
plot.tight_layout()
plot.imshow(X_train[i], cmap='gray', interpolation='none')
plot.title("Digit: {}".format(y_train[i]))
plot.xticks([])
plot.yticks([])
在10个计数的迭代循环中,我们在每次迭代中创建一个子图,并在其中显示来自X_train矢量的图像。我们从相应的y_train向量为每个图像添加标题。注意,y_train载体含有在X_train矢量对应的图像的实际值。我们通过使用null参数调用xticks和yticks这两个方法来删除x和y轴标记。运行代码时,您将看到以下输出-
接下来,我们将准备数据以将其输入到我们的网络中。