- AI与Python中的¢Â€A“的游戏- Tutorialspoint(1)
- AI与Python中的¢Â€A“的游戏- Tutorialspoint
- 机器学习-传统AI
- 机器学习-传统AI(1)
- 机器学习 python (1)
- 机器学习 python 代码示例
- 机器学习中的 P 值(1)
- 机器学习 (1)
- 机器学习中的 P 值
- C++中的机器学习
- C++中的机器学习(1)
- AI与Python中的¢Â€“引物概念- Tutorialspoint
- AI与Python中的¢Â€“引物概念- Tutorialspoint(1)
- 学习 python 机器学习 - 任何代码示例
- 使用Python机器学习-方法(1)
- 使用Python机器学习-方法
- 机器学习 - 任何代码示例
- 机器学习-什么是P值(1)
- 在机器学习中什么是“i” (1)
- 机器学习-什么是P值
- 什么是机器学习?
- 什么是机器学习?(1)
- 使用Python进行机器学习(1)
- 使用Python进行机器学习
- 机器学习-什么是机器学习? -指导点(1)
- 机器学习-什么是机器学习? -指导点
- 机器学习-今天的AI可以做什么? -指导点(1)
- 机器学习-今天的AI可以做什么? -指导点
- ai (1)
📅 最后修改于: 2020-12-11 05:32:02 🧑 作者: Mango
学习是指通过学习或经验获得知识或技能。基于此,我们可以定义机器学习(ML)如下-
可以将其定义为计算机科学领域,更具体地讲,是人工智能的应用,它为计算机系统提供了学习数据的能力并从经验中进行改进而无需进行明确编程的能力。
基本上,机器学习的主要重点是允许计算机自动学习而无需人工干预。现在出现的问题是,如何开始和完成这种学习?可以从观察数据开始。数据也可以是一些示例,说明或一些直接的经验。然后,根据该输入,机器通过查找数据中的某些模式来做出更好的决策。
机器学习(ML)的类型
机器学习算法可帮助计算机系统学习而无需明确编程。这些算法分为有监督的或无监督的。现在让我们看看一些算法-
监督机器学习算法
这是最常用的机器学习算法。之所以称为监督,是因为可以将其从训练数据集中学习算法的过程视为指导学习过程的教师。在这种ML算法中,可能的结果已经为人所知,并且训练数据还标有正确答案。可以理解如下-
假设我们有输入变量x和输出变量y,并且我们应用了一种算法来学习从输入到输出的映射函数,例如-
Y = f(x)
现在,主要目标是很好地近似映射函数,以便当我们有新的输入数据(x)时,我们可以预测该数据的输出变量(Y)。
主要是监督学习的问题可以分为以下两种:
-
分类-当我们具有分类输出(例如“ black”,“ teaching”,“ non-teaching”等)时,此问题称为分类问题。
-
回归-当我们拥有诸如“距离”,“千克”等的实际值输出时,此问题称为回归问题。
决策树,随机森林,knn,逻辑回归是监督式机器学习算法的示例。
无监督机器学习算法
顾名思义,这类机器学习算法没有任何主管可以提供任何指导。这就是为什么无监督机器学习算法与真正的人工智能紧密结合的原因。可以理解如下-
假设我们有输入变量x,那么将没有监督学习算法中的相应输出变量。
简而言之,我们可以说在无监督学习中将没有正确的答案,也没有指导老师。算法有助于发现数据中有趣的模式。
无监督学习问题可以分为以下两种问题:
-
聚类-在聚类问题中,我们需要发现数据中的固有分组。例如,根据客户的购买行为对其进行分组。
-
关联-一个问题称为关联问题,因为这类问题需要发现描述我们数据大部分的规则。例如,找到同时购买x和y的客户。
无监督机器学习算法的示例包括用于聚类的K均值,用于关联的Apriori算法。
强化机器学习算法
很少使用这类机器学习算法。这些算法训练系统做出特定决策。基本上,机器处于使用反复试验法不断训练自身的环境中。这些算法会从过去的经验中吸取教训,并尝试捕获可能的最佳知识以做出准确的决策。马尔可夫决策过程是强化机器学习算法的一个示例。
最常见的机器学习算法
在本节中,我们将学习最常见的机器学习算法。算法描述如下-
线性回归
它是统计和机器学习中最著名的算法之一。
基本概念-主要是线性回归是一种线性模型,它假设输入变量说x和单个输出变量说y之间存在线性关系。换句话说,可以说y可以根据输入变量x的线性组合来计算。变量之间的关系可以通过拟合最佳线来建立。
线性回归的类型
线性回归具有以下两种类型-
-
简单线性回归-如果线性回归算法只有一个自变量,则称为简单线性回归。
-
多元线性回归-如果线性回归算法具有多个独立变量,则称为多元线性回归。
线性回归主要用于基于连续变量估计实际值。例如,可以通过线性回归估算一天中商店的实际销售额(基于实际价值)。
逻辑回归
它是一种分类算法,也称为对数回归。
主要是逻辑回归是一种分类算法,用于根据给定的一组独立变量估算离散值(例如0或1,是或否,是或否)。基本上,它预测概率,因此其输出位于0到1之间。
决策树
决策树是一种监督学习算法,主要用于分类问题。
基本上,它是一个基于自变量表示为递归分区的分类器。决策树具有形成根树的节点。根树是有向树,其节点称为“ root”。根没有任何传入边缘,而所有其他节点都有一个传入边缘。这些节点称为叶子或决策节点。例如,考虑以下决策树以查看一个人是否适合。

支持向量机(SVM)
它用于分类和回归问题。但主要用于分类问题。 SVM的主要概念是将每个数据项绘制为n维空间中的一个点,而每个要素的值就是特定坐标的值。这里n是我们将拥有的功能。以下是了解SVM概念的简单图形表示-
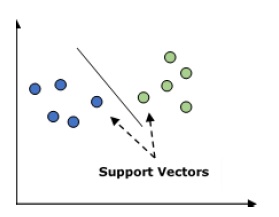
在上图中,我们有两个特征,因此我们首先需要在二维空间中绘制这两个变量,其中每个点都有两个坐标,称为支持向量。该行将数据分为两个不同的分类组。这行将是分类器。
朴素贝叶斯
这也是一种分类技术。这种分类技术背后的逻辑是将贝叶斯定理用于构建分类器。假设是预测变量是独立的。简而言之,它假定类中某个特定功能的存在与任何其他功能的存在无关。以下是贝叶斯定理的方程式-
$$ P \ left(\ frac {A} {B} \ right)= \ frac {P \ left(\ frac {B} {A} \ right)P \ left(A \ right)} {P \ left( B \ right}} $$
朴素贝叶斯模型易于构建,对大型数据集特别有用。
K最近邻居(KNN)
它用于问题的分类和回归。它被广泛用于解决分类问题。该算法的主要概念是,它用于存储所有可用案例,并通过其k个邻居的多数票对新案例进行分类。然后将案例分配给其最接近K的邻居中最常见的一类,通过距离函数度量。距离函数可以是欧几里得距离,明可夫斯基距离和汉明距离。考虑以下使用KNN-
-
在计算上,KNN比用于分类问题的其他算法昂贵。
-
所需变量的规格化,否则范围较大的变量可能会对它产生偏差。
-
在KNN中,我们需要进行诸如噪声消除之类的预处理阶段。
K均值聚类
顾名思义,它用于解决聚类问题。基本上,这是一种无监督的学习。 K-Means聚类算法的主要逻辑是通过多个聚类对数据集进行分类。请按照以下步骤通过K均值形成聚类-
-
K均值为每个聚类选择k个点,称为质心。
-
现在,每个数据点都形成一个具有最接近质心的聚类,即k个聚类。
-
现在,它将基于现有群集成员找到每个群集的质心。
-
我们需要重复这些步骤,直到收敛为止。
随机森林
它是一种监督分类算法。随机森林算法的优点是可以用于分类和回归类问题。基本上,它是决策树(即森林)的集合,或者您可以说决策树的集合。随机森林的基本概念是,每棵树都给出一个分类,然后森林从中选择最佳分类。以下是随机森林算法的优点-
-
随机森林分类器可用于分类和回归任务。
-
他们可以处理缺失的值。
-
即使我们在森林中有更多的树木,也不会完全适合模型。