- 合并排序算法
- 合并排序算法(1)
- 排序算法-合并排序(1)
- 排序算法-合并排序
- 数据结构-合并排序算法
- 数据结构-合并排序算法(1)
- 排序算法可视化:合并排序
- 排序算法可视化:合并排序(1)
- 合并排序(1)
- 3路合并排序
- 就地合并排序
- 就地合并排序(1)
- 就地合并排序 | 2套
- 就地合并排序 | 2套(1)
- 3路合并排序(1)
- 合并排序
- 壳排序算法(1)
- 桶排序算法(1)
- 桶排序算法
- 壳排序算法
- Python合并排序
- Python合并排序(1)
- Java程序以实现合并排序算法
- Java程序以实现合并排序算法(1)
- 合并排序 - Java (1)
- 合并排序 java (1)
- 合并3个排序的数组(1)
- 合并3个排序的数组
- c 中字符串的合并排序(1)
📅 最后修改于: 2020-12-12 08:12:26 🧑 作者: Mango
外部排序合并算法
到目前为止,我们已经看到排序是任何数据库系统中的重要术语。这意味着按升序或降序排列数据。我们不仅将排序用于生成排序输出,而且还将其用于满足各种数据库算法的条件。在查询处理中,排序方法用于有效地执行各种关系操作,例如联接等。但是需要为系统提供分类的输入值。为了对任何关系进行排序,我们必须在排序键上建立一个索引,并使用该索引来按排序顺序读取该关系。但是,使用索引时,我们会按逻辑而非物理方式对关系进行排序。因此,将对以下情况进行排序:
情况1:关系的大小比主内存小或中等。
情况2:关系的大小大于内存大小。
在情况1中,小或中等大小的关系不超过主存储器的大小。因此,我们可以将它们放入内存中。因此,我们可以使用标准排序方法,例如快速排序,合并排序等。
对于情况2,标准算法无法正常工作。因此,对于大小超过内存大小的这种关系,我们使用外部排序合并算法。
不适合内存的关系的排序,因为它们的大小大于内存的大小。这种类型的排序称为“外部排序” 。结果,外部排序合并是用于外部排序的最合适的方法。
外部排序合并算法
在这里,我们将详细讨论外部排序合并算法阶段:
在算法中,M表示主存储器缓冲区中可用于排序的磁盘块数。
阶段1:最初,我们创建了许多排序的运行。排序每个。这些运行只包含关系的一些记录。
i = 0;
repeat
read either M blocks or the rest of the relation having a smaller size;
sort the in-memory part of the relation;
write the sorted data to run file Ri;
i =i+1;
Until the end of the relation
在阶段1中,我们可以看到我们正在对磁盘块执行排序操作。完成阶段1的步骤后,进入阶段2。
阶段2:在阶段2中,我们合并运行。考虑运行的总数,即N小于M。因此,我们可以为每个运行分配一个块,并且仍然保留一些空间来容纳一个输出块。我们执行以下操作:
read one block of each of N files Ri into a buffer block in memory;
repeat
select the first tuple among all buffer blocks (where selection is made in sorted order);
write the tuple to the output, and then delete it from the buffer block;
if the buffer block of any run Ri is empty and not EOF(Ri)
then read the next block of Ri into the buffer block;
Until all input buffer blocks are empty
完成阶段2后,我们将获得一个排序的关系作为输出。然后对输出文件进行缓冲,以最大程度地减少磁盘写入操作。当此算法合并N次运行时,这就是为什么将其称为N向合并。
但是,如果关系的大小大于内存大小,则在阶段1中将生成M个或更多运行。此外,在处理阶段2时,不可能为每个运行分配单个块。在这种情况下,合并操作过程需要多次通过。由于M-1输入缓冲块具有足够的内存,每次合并都可以轻松地将M-1运行作为其输入。因此,初始阶段的工作方式如下:
- 它合并了第一个M-1运行,以获取下一个运行的单个运行。
- 同样,它将合并下一个M-1运行。继续执行此步骤,直到处理完所有初始运行为止。在此,运行次数的M-1值降低了。但是,如果此减小的值大于或等于M,则需要创建另一遍。对于此新遍,输入将是第一遍创建的运行。
- 每次通过的工作是将运行次数减少M-1值。该作业会根据需要重复多次,直到运行次数小于或等于M。
- 因此,最终通过将产生排序的输出。
外部分类合并方法的成本估算
外部分类合并的成本分析是使用算法中的上述阶段进行的:
- 假设b r表示包含关系r的记录的块数。
- 在第一阶段,它读取关系的每个块并将其写回。总共需要2b r块传输。
- 最初,运行次数的值为[b r / M]。由于每次合并遍历的运行次数减少M-1,因此需要总数为[log M-1 (b r / M)]的合并遍历。
每遍只读取和写入关系的每个块一次。但是有两个例外:
- 最后一遍可以给出排序的输出,而无需将其结果写入磁盘
- 在通过过程中,可能会无法读取或写入某些运行。
忽略了这么小的例外,外部排序的块传输总数就出来了:
b r ( 2Γlog M-1 (b r / M)˥+ 1)
我们需要增加磁盘查找成本,因为每次运行都需要为其读取和写入数据。如果在阶段2(即合并阶段)中,为每个运行分配了b b个缓冲块,或者每个运行一次读取b b个数据,则每个合并需要[b r / b b ]来寻求读取数据。输出是顺序写入的,因此,如果输入与输出位于同一磁盘上,则磁头将需要在连续块的写入之间移动。因此,为每个合并遍历添加总计2 [b r / b b ]的搜索,并且搜索总数为:
2ΓB r的/ M˥+γBR / B B˥(2ΓlogM-1(B R / M)˥ – 1)
因此,我们需要计算磁盘搜索的总数,以分析外部合并排序算法的成本。
外部合并排序算法的示例
让我们了解外部合并排序算法的工作原理,并借助示例分析外部排序的成本。
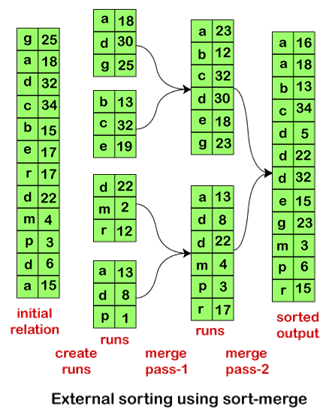
假设对于关系R,我们正在执行外部排序合并。在这种情况下,假设只有一个块可以容纳一个元组,而内存最多可以容纳三个块。因此,在处理阶段2(即合并阶段)时,它将使用两个块作为输入,并使用一个块作为输出。