- 哈希联接和排序合并联接之间的区别(1)
- 哈希联接和排序合并联接之间的区别
- 嵌套循环联接和哈希联接之间的区别(1)
- 嵌套循环联接和哈希联接之间的区别
- 合并联接算法
- 合并联接算法(1)
- SQL |联接(内联接、左联接、右联接和完全联接)(1)
- SQL |联接(内联接、左联接、右联接和完全联接)
- 双管道联接算法
- 双管道联接算法(1)
- SQL |联接(内部联接,左侧联接,右侧联接和完全联接)
- SQL |联接(内部联接,左侧联接,右侧联接和完全联接)(1)
- 左联接和右联接之间的区别
- SQL |联接(笛卡尔联接和自联接)
- SQL |联接(笛卡尔联接和自联接)
- SQL |联接(笛卡尔联接和自联接)(1)
- SQL |联接(笛卡尔联接和自联接)(1)
- 嵌套循环联接算法(1)
- 嵌套循环联接算法
- SQL左联接(1)
- T-SQL-联接表
- SQL左联接
- T-SQL-联接表(1)
- MS SQL Server中的左联接和右联接(1)
- MS SQL Server中的左联接和右联接
- MySQL联接(1)
- MySQL左联接(1)
- MySQL 右联接(1)
- MySQL联接
📅 最后修改于: 2020-12-12 08:13:22 🧑 作者: Mango
哈希联接算法
哈希联接算法用于执行自然联接或等效联接操作。哈希联接算法背后的概念是将每个给定关系的元组划分为集合。分区是基于联接属性上相同的哈希值完成的。哈希函数提供哈希值。在算法中使用哈希函数的主要目的是减少比较次数并提高完成关系上联接操作的效率。
例如,假设有两个元组a和b都满足连接条件。这意味着它们的连接属性具有相同的值。假设a和b元组都由哈希值i组成。这意味着,元组应该是在我和元组乙方应在B I。因此,我们仅将a i中的元组与b i的b个元组进行比较。我们不需要比较任何其他分区中的b个元组。因此,以这种方式,哈希联接操作起作用。
哈希联接算法
这是哈希连接算法,其中我们计算了两个给定关系r和s的自然连接。在算法中,使用了各种术语:
吨– [R⋈吨S:它定义元组吨r和t s,这是进一步接着伸出重复属性的属性的串联。
t r和t s :分别是关系r和s的元组。
让我们通过以下步骤了解哈希联接算法:
步骤1:在算法中,首先,我们对关系r和s进行了划分。
步骤2:分区后,我们使用for循环(从i = 0到n h)在每个分区对i上执行单独的索引嵌套循环联接。
步骤3:为执行嵌套循环联接,它首先在每个s i上创建一个哈希索引,然后使用r i中的元组进行探测。在算法中,关系r是探针输入,关系s是构建输入。
使用哈希联接算法有一个好处,即si上的哈希索引是内置内存,因此对于获取元组,我们不需要访问磁盘。最好使用较小的输入关系作为构建关系。
哈希联接中的递归分区
递归分区是系统重复输入的分区直到构建输入的每个分区都适合内存的分区。当n h的值大于或等于存储块数时,需要进行递归分区。由于缓冲区块不足,一口气很难分割关系。因此,最好将关系拆分为多次遍历。一次可以将输入分成几个分区,因为有足够的块可用作输出缓冲区。分别读取通过过程构建的每个存储桶,并在下一个过程中进一步分区,以创建较小的分区。同样,散列函数在不同的通道中也不同。因此,最好使用递归分区来处理这种情况。
哈希联接中的溢出
由于以下情况,哈希表中的溢出条件发生在构建关系的任何分区i中:
情况1:当s i上的哈希索引大于主存储器时,就会发生溢出情况。
情况2:当构建关系中有多个元组,并且join属性的值相同时。
情况3:当散列函数不具有随机性和均匀性特征时。
情况4:当某些分区的元组比平均分区多,而其他分区的元组更少时,这种分区称为“偏斜” 。
处理溢出
我们可以使用各种方法来处理哈希表溢出的情况。
- 使用软糖系数
通过使用软键增加分区的数量,我们可以处理少量的偏斜。软糖系数是一个较小的值,会增加分区的数量。因此,这将有助于减小每个分区的预期大小,包括其哈希索引小于内存大小。不幸的是,使用模糊因素使用户对分区的大小保持保守。因此,溢出的可能性仍然是可能的。但是,使用软键系数适合处理较小的溢出,但不足以处理哈希表中的较大的溢出。
结果,我们还有另外两种方法来处理溢出。
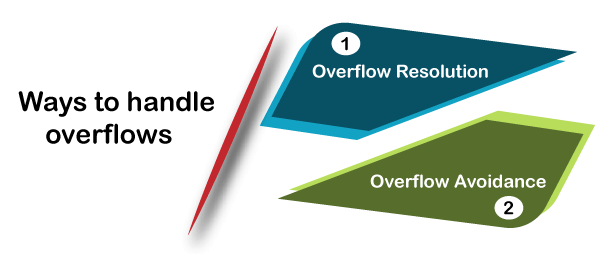
1.溢出分辨率
当检测到哈希索引溢出时,将在构建阶段应用溢出解决方法。溢出解决方案通过以下方式工作:
如果大小大于内存大小,它将为任何分区i查找s i 。它再次分割等建立关系,就是我为较小的分区通过不同的哈希函数。类似地,它通过新的哈希函数对探测关系r i进行分区,并且只有那些具有匹配分区的元组才被加入。但是,这是一种不太谨慎的方法,因为该方法会等待这种情况发生,然后采取必要的措施来解决问题。
2.避免溢出
避免溢出方法在分区时会使用谨慎的方法,以避免在构建阶段发生溢出。避免溢出的方法如下:
最初将构建关系划分为几个小分区,然后合并其中的一些分区。这些分区的组合方式使每个组合分区都适合内存。同样,它将探测关系r划分为s上的组合分区。但是,在这种方法中,r i的大小无关紧要。
如果s中的大量元组的join属性值相同,则溢出解析和避免溢出方法在某些分区上可能会失败。在这种情况下,最好使用块嵌套循环联接,而不是应用散列联接技术来完成那些分区上的联接操作。
哈希联接的成本分析
为了分析哈希联接的成本,我们认为在哈希联接中不会发生溢出。我们将仅考虑以下两种情况:
1.不需要递归分区
我们需要完全读写关系r和s来对它们进行分区。为此,总共需要进行2(b r + b s )个块传输。术语b r和b s是保持关系r和s的记录的块数。两种关系都会读取每个分区一次,以进行更多的b r + b s块传输。但是,这些分区所占用的块数可能比b r + b s略多,这会导致部分填充的块。要访问这样的部分填充的块,每个关系可能需要大约2n h的开销。因此,哈希联接成本估算需要:
块传输次数= 3(b r + b s )+ 4n h
在这里,我们可以忽略4n h的开销值,因为它远小于b r + b s值。
磁盘的数量寻求= 2(γBR / B Bꓶ+γBS / B Bꓶ)+ 2Nħ
在这里,我们假设每个输入缓冲区分配有b b个块,并且构建以及探测阶段仅需要对该关系的每个n h分区进行一次搜索,因为我们可以顺序读取每个分区。
2.需要递归分区
在这种情况下,每次通过将每个分区的大小减小M-1个预期因子,并且还会重复进行直到直到每个分区的大小最多为M个块为止。因此,为了对关系s进行分区,我们需要:
通过次数=ΓlogM -1 (b s )-1ꓶ
构建和探测关系的分区所需的通过次数相同。与每次通过一样,读取和写入s的每个块,并且总共需要2b s log log M-1 (b s )-1ꓶ块传输来拆分关系s。因此,哈希联接成本估算需要:
块传输次数= 2(b r + b s )ΓlogM -1 (b s )-1ꓶ+ b r + b s
磁盘的数量寻求= 2(γBR / B Bꓶ+γBS / B Bꓶ)ΓlogM-1(B S) – 1ꓶ
在这里,我们假设为缓冲每个分区,我们为其分配了b b个块。此外,在构建和探测阶段,我们忽略了相对较少的搜索。
结果,如果主存储器的大小增加或很大,则可以进一步改进哈希联接算法。
混合哈希联接
这是一种哈希联接类型,可用于执行内存大小相对较大的联接操作。但是,构建关系仍不完全适合内存。因此,混合哈希联接算法解决了哈希联接算法的缺点。