目标检测的选择性搜索 |卷积神经网络
目标定位问题是目标检测中最困难的部分。一种方法是我们使用不同大小的滑动窗口来定位图像中的对象。这种方法称为穷举搜索。这种方法在计算上非常昂贵,因为我们需要在数千个窗口中搜索对象,即使对于小图像尺寸也是如此。已经进行了一些优化,例如采用不同比例的窗口大小(而不是增加一些像素)。但即使在此之后,由于窗口数量的原因,它也不是很有效。本文研究了选择性搜索算法,该算法同时使用穷举搜索和分割(一种通过分配不同颜色来分离图像中不同形状对象的方法)。
选择性搜索算法:
- 使用Felzenszwalb 等人在他的论文“Efficient Graph-Based Image Segmentation”中描述的方法生成输入图像的初始子分割。

- 递归地将较小的相似区域组合成较大的区域。我们使用贪心算法将相似区域组合成更大的区域。算法写在下面。
Greedy Algorithm : 1. From set of regions, choose two that are most similar. 2. Combine them into a single, larger region. 3. Repeat the above steps for multiple iterations.
- 使用分割的区域建议来生成候选对象位置。
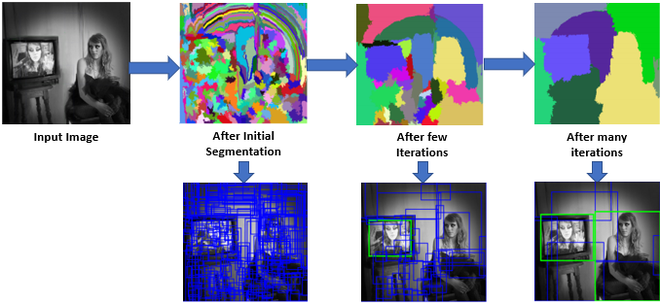
分割的相似性:
选择性搜索论文在将初始的小分割组合成更大的分割时考虑了四种类型的相似性。这些相似之处是:
- 颜色相似度:特别是对于每个区域,我们生成图像中每个颜色通道的直方图。在本文中,每个颜色通道的直方图中取 25 个 bin。这为我们提供了 75 个 bin(每个 R、G 和 B 25 个),并且所有通道组合成每个区域的向量 (n = 75)。然后我们使用以下等式找到相似性:


- 纹理相似度:使用生成的图像的 8 个高斯导数计算纹理相似度,并为每个颜色通道提取具有 10 个 bin 的直方图。这为每个区域提供了 10 x 8 x 3 = 240 维向量。我们使用这个等式得出相似性。


- 尺寸相似度:尺寸相似度的基本思想是使较小的区域容易合并。如果不考虑这种相似性,那么更大的区域会不断与更大的区域合并,并且只会在这个位置生成多个尺度的区域提议。


- 填充相似度:填充相似度衡量两个区域相互匹配的程度。如果两个区域非常适合彼此(例如一个区域存在于另一个区域中),那么它们应该被合并,如果两个区域甚至没有相互接触,那么它们不应该被合并。


现在,以上四种相似性结合起来形成了最终的相似性。

结果 :
来衡量这个方法的性能。该论文描述了一种称为 MABO(平均平均最佳重叠)的评估参数。
有两个版本的选择性搜索来了Fast和Quality 。它们之间的区别在于 Quality 生成的边界框比 Fast 多得多,因此需要更多时间来计算,但具有更高的召回率和 ABO(平均最佳重叠)和 MABO(平均平均最佳重叠)。我们计算 ABO 如下。

正如我们可以观察到的,当所有相似性结合使用时,它给了我们最好的 MABO。但是,也可以得出结论,RGB 不是在这种方法中使用的最佳配色方案。 HSV、Lab 和 rgI 都比 RGB 表现更好,这是因为它们对阴影和亮度变化不敏感。
但是当我们将这些不同的相似性、配色方案和阈值 (k) 进行多样化和组合时,

在选择性搜索论文中,基于 MABO 的贪心方法在不同的策略上得到了上述结果。可以说,这种结合不同策略的方法虽然给出了更好的 MABO,但运行时间也大大增加。
对象识别中的选择性搜索:
在选择性搜索论文中,作者使用该算法进行目标检测,并通过将地面实况示例和与地面实况重叠 20-50% 的样本假设(作为负示例)提供给 SVM 分类器并训练它来识别假阳性来训练模型。下面给出了使用的模型架构。
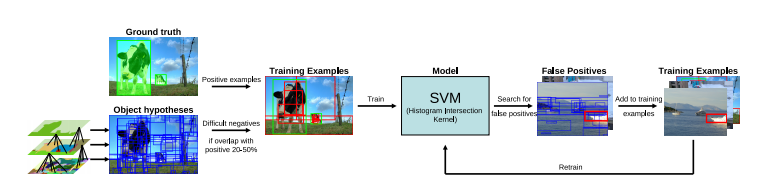
对象识别架构(来源:选择性搜索论文)
在 VOC 2007 测试集上生成的结果是,

正如我们所看到的,它在 VOC 2007 测试集上产生了非常高的召回率和最佳 MABO,与实现类似召回率和 MABO 的其他算法相比,它需要处理的窗口数量少得多。
应用:
选择性搜索广泛用于早期最先进的架构,如 R-CNN、Fast R-CNN 等。但是,由于它处理的窗口数量,它需要 1.8 到 3.7 秒(快速选择性搜索)生成对于实时对象检测系统来说不够好的区域建议。
参考:
- 选择性搜索论文(Selective Search for Object Detection)
- 斯坦福计算机视觉幻灯片