AUC-ROC 曲线
机器学习的一个重要方面是模型评估。您需要有一些机制来评估您的模型。这就是这些性能指标出现的地方,它们让我们了解模型的好坏。如果您熟悉机器学习的一些基础知识,那么您必须掌握其中一些指标,例如准确度、精度、召回率、auc-roc 等。
假设您正在研究一个二元分类问题并提出一个准确率为 95% 的模型,现在有人问您这是什么意思,您可以足够快地说出您的模型做出的 100 个预测,其中 95 个是正确的。好吧,让我们稍微提高一下,现在基本指标是召回率,你被问到同样的问题,你可能会在这里花点时间,但最终,你会想出一个解释,比如 100 个相关数据点(一般为正类) ) 您的模型能够识别其中的 80 个。到目前为止一切顺利,现在让我们假设您使用 AUC-ROC 作为指标评估您的模型并得到 0.75 的值,然后我再次向您提出相同的问题 0.75 或 75% 意味着什么,现在您可能需要给出它想一想,你们中的一些人可能会说模型正确识别数据点的可能性为 75%,但现在您可能已经意识到事实并非如此。让我们尝试对分类问题最常用的性能指标之一有一个基本的了解。
历史:
如果您参加过任何在线机器学习竞赛/黑客马拉松,那么您一定遇到过 Area Under Curve Receiver Operator Characteristic aka AUC-ROC,他们中的许多人都将其作为分类问题的评估标准。让我们承认,当您第一次听说它时,您一定曾经有过这个想法,这个长名字是怎么回事?好吧,ROC曲线的起源可以追溯到二战时期,它最初是用来分析雷达信号的。美国陆军试图测量其雷达接收器正确识别日本飞机的能力。现在我们有了一些起源故事,让我们开始谈正事
几何解释:
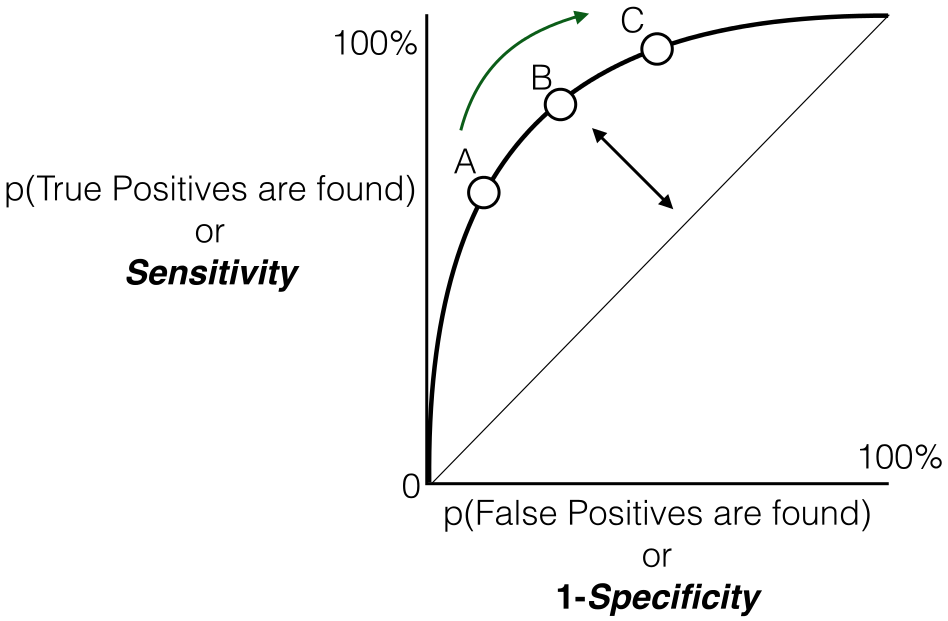
这是您在使用 Google AUC-ROC 时会遇到的最常见的定义。基本上,ROC 曲线是显示分类模型在所有可能阈值下的性能的图表(阈值是一个特定值,超过该值你说一个点属于特定类别)。曲线绘制在两个参数之间
- 真阳性率
- 假阳性率
在理解之前,TPR和FPR让我们快速看一下混淆矩阵。

资料来源:知识共享
- 真阳性:实际阳性和预测为阳性
- 真阴性:实际阴性和预测为阴性
- 假阳性(I 型错误) :实际阴性但预测为阳性
- 假阴性(II型错误) :实际阳性但预测为阴性
简单来说,您可以将 False Positive 称为false alarm ,将 False Negative 称为miss 。现在让我们看看什么是TPR和FPR。

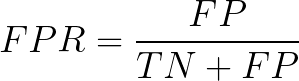
基本上,TPR/Recall/Sensitivity 是正确识别的正例的比率,而 FPR 是错误分类的负例的比率。
如前所述,ROC 只是 TPR 和 FPR 在所有可能阈值上的图,而 AUC 是该 ROC 曲线下方的整个区域。
资料来源:知识共享
概率解释:
我们查看了几何解释,但我想这仍然不足以发展 0.75 AUC 实际含义背后的直觉,现在让我们从概率的角度来看 AUC-ROC。
让我先谈谈 AUC 是做什么的,然后我们将在此基础上建立我们的理解
AUC measures how well a model is able to distinguish between classes
AUC 为 0.75 实际上意味着假设我们采用属于不同类别的两个数据点,那么模型有 75% 的机会能够正确地分离它们或对它们进行排序,即正点比负类具有更高的预测概率。 (假设较高的预测概率意味着该点理想地属于正类)
这是一个让事情更清楚的小例子。Index Class Probability P1 1 0.95 P2 1 0.90 P3 0 0.85 P4 0 0.81 P5 1 0.78 P6 0 0.70
这里我们有 6 个点,其中 P1、P2、P5 属于第 1 类,P3、P4、P6 属于第 0 类,我们是概率列中相应的预测概率,正如我们所说,如果我们取两个点属于不同的类,那么模型排名正确排序的概率是多少
我们将取所有可能的对,使得一个点属于第 1 类,另一个属于第 0 类,我们将总共有 9 个这样的对,下面是所有这 9 个可能的对Pair isCorrect (P1,P3) Yes (P1,P4) Yes (P1,P6) Yes (P2,P3) Yes (P2,P4) Yes (P2,P6) Yes (P3,P5) No (P4,P5) No (P5,P6) Yes
这里的 isCorrect 列告诉所提到的对是否正确,根据预测概率排序,即第 1 类点的概率高于第 0 类点的概率,在这 9 个可能的对中有 7 个中,第 1 类的排名高于第 0 类,或者我们可以说,如果您选择属于不同类别的一对点,模型将有 77% 的机会能够正确区分它们。现在,我想你可能对这个 AUC 数字有一点直觉,为了消除任何进一步的疑问,让我们使用 scikit learn 的 AUC-ROC 实现来验证它
Python实现代码:
python3
import numpy as np
from sklearn .metrics import roc_auc_score
y_true = [1, 1, 0, 0, 1, 0]
y_pred = [0.95, 0.90, 0.85, 0.81, 0.78, 0.70]
auc = np.round(roc_auc_score(y_true, y_pred), 3)
print("Auc for our sample data is {}". format(auc))python3
import pandas as pd
y_pred_1 = [0.99, 0.98, 0.97, 0.96, 0.91, 0.90, 0.89, 0.88]
y_pred_2 = [0.99, 0.95, 0.90, 0.85, 0.20, 0.15, 0.10, 0.05]
y_act = [1, 1, 1, 1, 0, 0, 0, 0]
test_df = pd.DataFrame(zip(y_act, y_pred_1, y_pred_2),
columns=['Class', 'Model_1', 'Model_2'])python3
import matplotlib.pyplot as plt
cols = ['Model_1', 'Model_2']
fig, axs = plt.subplots(1, 2, figsize=(15, 5))
for index, col in enumerate(cols):
sns.kdeplot(d2[d2['Status'] == 1][col],
label="Class 1", shade=True, ax=axs[index])
sns.kdeplot(d2[d2['Status'] == 0][col],
label="Class 0", shade=True, ax=axs[index])
axs[index].set_xlabel(col)
plt.show()何时使用:
话虽如此,ROC-AUC 在某些地方可能并不理想。
- ROC-AUC 在数据集严重不平衡的情况下不能很好地工作,为了给出一些直觉,让我们回顾一下这里的几何解释。基本上,ROC 是 TPR 和 FPR 之间的图(假设少数类是正类),现在让我们再仔细看看 FPR 公式
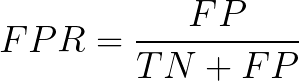
FPR 的分母具有真负值作为一个因素,因为负类占多数,FPR 的分母由真负值主导,这使得 FPR 对少数类预测的任何变化都不那么敏感。为了克服这个问题,使用 Precision-Recall Curves 代替 ROC,然后计算 AUC,尝试自己回答这个 Precision-Recall 曲线如何处理这个问题(提示:Recall 和 TPR 在技术上是相同的,只是 FPR 用 Precision 代替,只需比较两者的分母,并尝试评估此处如何解决不平衡问题)
- ROC-AUC 试图衡量分类的等级排序是否正确,它没有考虑实际预测的概率,让我试着用一个小代码片段来说明这一点
蟒蛇3
import pandas as pd
y_pred_1 = [0.99, 0.98, 0.97, 0.96, 0.91, 0.90, 0.89, 0.88]
y_pred_2 = [0.99, 0.95, 0.90, 0.85, 0.20, 0.15, 0.10, 0.05]
y_act = [1, 1, 1, 1, 0, 0, 0, 0]
test_df = pd.DataFrame(zip(y_act, y_pred_1, y_pred_2),
columns=['Class', 'Model_1', 'Model_2'])

两个样本模型的类别概率
如上所述,我们有两个模型 Model_1 和 Model_2,它们在分离两个类方面都做得很好,但是如果我让你从中选择一个,那会是哪一个,坚持你的答案,让我先绘制这些模型概率.
蟒蛇3
import matplotlib.pyplot as plt
cols = ['Model_1', 'Model_2']
fig, axs = plt.subplots(1, 2, figsize=(15, 5))
for index, col in enumerate(cols):
sns.kdeplot(d2[d2['Status'] == 1][col],
label="Class 1", shade=True, ax=axs[index])
sns.kdeplot(d2[d2['Status'] == 0][col],
label="Class 0", shade=True, ax=axs[index])
axs[index].set_xlabel(col)
plt.show()
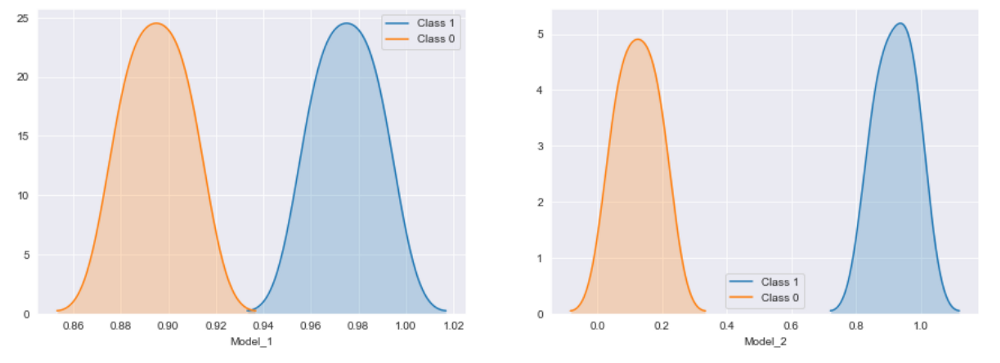
样本模型的类概率分布
如果之前有任何怀疑,我想现在你的选择就很清楚了,Model_2 是明显的赢家。但是两者的 AUC-ROC 值是相同的,这是它只是衡量模型是否能够正确排序类的缺点,它不会查看模型将两个类分开的程度,因此如果您有要求如果你想使用实际预测的概率,那么 roc 可能不是正确的选择,对于那些好奇的人来说,log loss 就是解决这个问题的一个指标
因此,理想情况下,当数据集没有严重不平衡并且您的用例不需要您使用实际预测概率时,应该使用 AUC。
多级 AUC:
对于多类设置,我们可以简单地使用一对多的方法,每个类都有一个 ROC 曲线。假设您有四个类 A、B、C、D,那么所有四个类都会有 ROC 曲线和相应的 AUC 值,即一旦 A 是一个类,B、C 和 D 组合将是其他类,类似地 B是一个类,A、C 和 D 组合为其他类,依此类推。