使用 WebScraping 和 Flask 为 GeeksforGeeks 用户数据设置 API
先决条件: Python中的WebScraping,Flask简介
在这篇文章中,我们将讨论如何使用网络抓取获取有关 GeeksforGeeks 用户的信息,并使用 Python 的微框架Flask将信息作为 API 提供。
第 1 步:访问身份验证配置文件
要抓取一个网站,第一步是访问该网站。 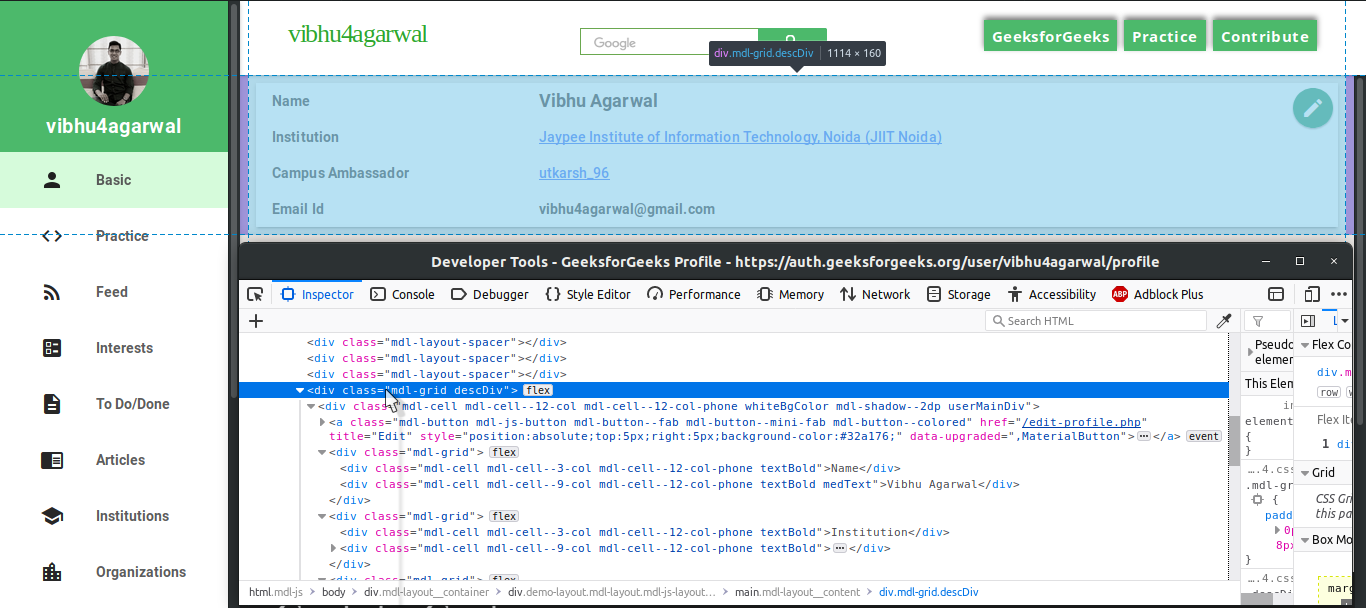 步骤#2:检查页面源
步骤#2:检查页面源
在上图中,您可以发现包含用户数据的descDiv div。在下图中,找到四个mdl-grid div 以获取四条信息。 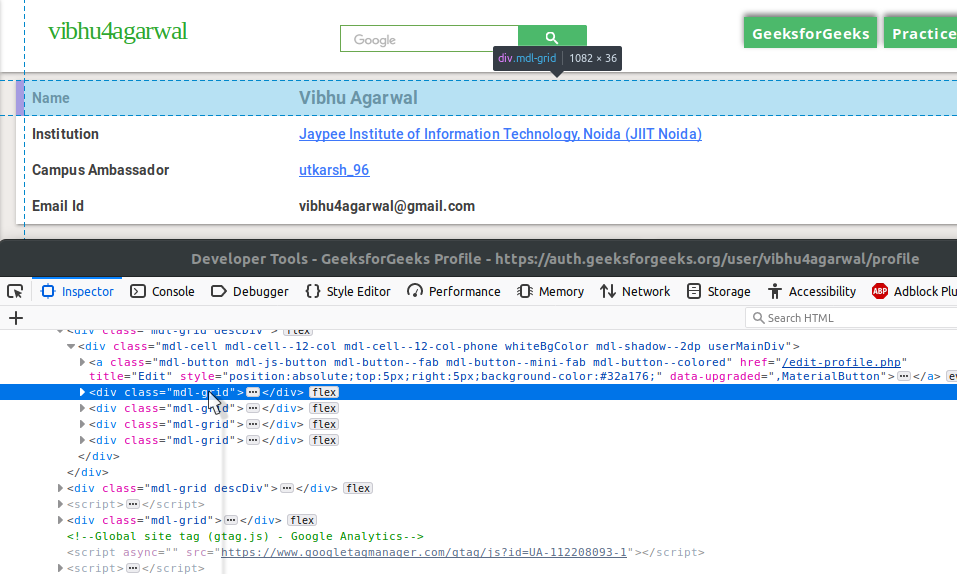
深入研究,找出属性及其对应值的两个块。那是您的用户个人资料数据。 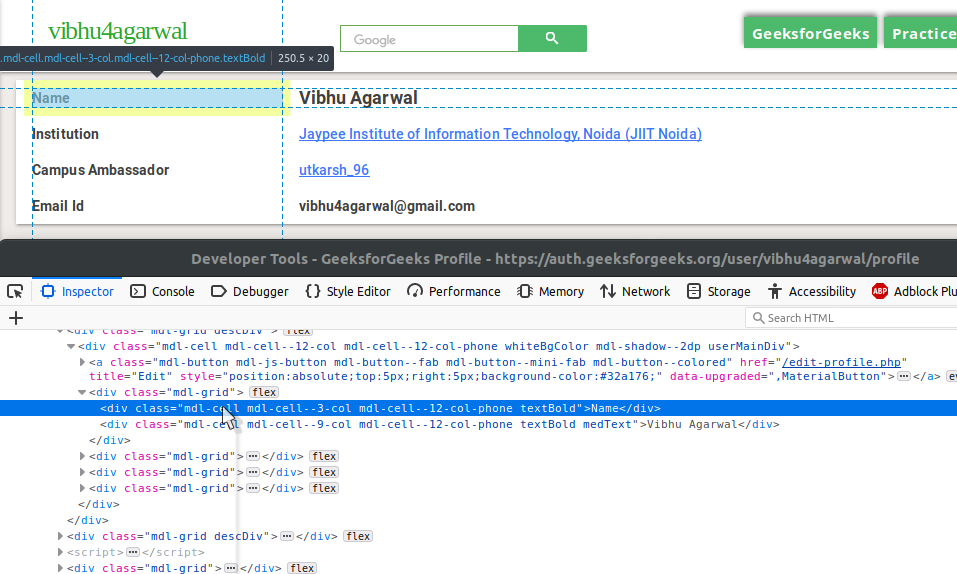
在以下函数中找到所有这些,该函数以字典的形式返回所有数据。
def get_profile_detail(user_handle):
url = "https://auth.geeksforgeeks.org/user/{}/profile".format(user_handle)
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html5lib')
description_div = soup.find('div', {'class': 'descDiv'})
if not description_div:
return None
user_details_div = description_div.find('div', {'class': 'mdl-cell'})
specific_details = user_details_div.find_all('div', {'class': 'mdl-grid'})
user_profile = {}
for detail_div in specific_details:
block = detail_div.find_all('div', {'class': 'mdl-cell'})
attribute = block[0].text.strip()
value = block[1].text.strip()
user_profile[attribute] = value
return {'user profile': user_profile}
第 3 步:文章和改进列表
这一次,尝试自己发现各种标签。 
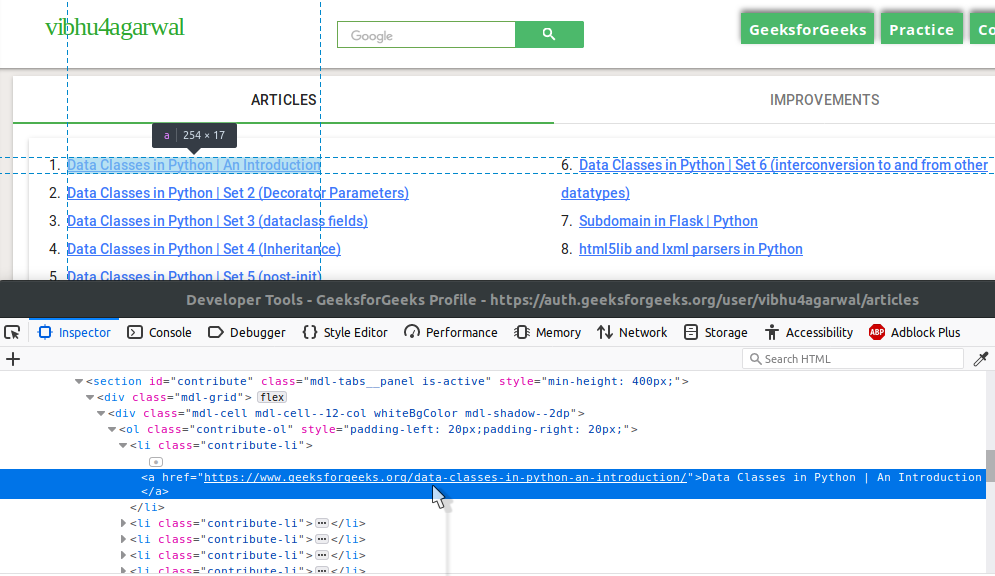
如果你能发现 HTML 的各种元素,你也可以很容易地编写代码来抓取它。
如果你不能,这里是你的帮助代码。
def get_articles_and_improvements(user_handle):
articles_and_improvements = {}
url = "https://auth.geeksforgeeks.org/user/{}/articles".format(user_handle)
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html5lib')
contribute_section = soup.find('section', {'id': 'contribute'})
improvement_section = soup.find('section', {'id': 'improvement'})
contribution_list = contribute_section.find('ol')
number_of_articles = 0
articles = []
if contribution_list:
article_links = contribution_list.find_all('a')
number_of_articles = len(article_links)
for article in article_links:
article_obj = {'title': article.text,
'link': article['href']}
articles.append(article_obj)
articles_and_improvements['number_of_articles'] = number_of_articles
articles_and_improvements['articles'] = articles
improvement_list = improvement_section.find('ol')
number_of_improvements = 0
improvements = []
if improvement_list:
number_of_improvements = len(improvement_list)
improvement_links = improvement_list.find_all('a')
for improvement in improvement_links:
improvement_obj = {'title': improvement.text,
'link': improvement['href']}
improvements.append(improvement_obj)
articles_and_improvements['number_of_improvements'] = number_of_improvements
articles_and_improvements['improvements'] = improvements
return articles_and_improvements
步骤#4:设置烧瓶
网页抓取的代码就完成了。现在是时候设置我们的 Flask 服务器了。这是 Flask 应用程序的设置,以及整个脚本所需的所有必要库。
from bs4 import BeautifulSoup
import requests
from flask import Flask, jsonify, make_response
app = Flask(__name__)
app.config['JSON_SORT_KEYS'] = False
第 5 步:设置 API
现在我们已经有了合适的函数,我们唯一的任务就是结合它们的结果,将字典转换为 JSON,然后在服务器上提供它。
这是端点的代码,它根据接收到的用户句柄为 API 提供服务。请记住,我们需要处理不当的用户句柄,我们的端点可以随时接收。
@app.route('//')
def home(user_handle):
response = get_profile_detail(user_handle)
if response:
response.update(get_articles_and_improvements(user_handle))
api_response = make_response(jsonify(response), 200)
else:
response = {'message': 'No such user with the specified handle'}
api_response = make_response(jsonify(response), 404)
api_response.headers['Content-Type'] = 'application/json'
return api_response
结合所有代码,您就拥有了一个提供动态 API 的功能齐全的服务器。 