Python|使用 Seaborn 的泰坦尼克号数据 EDA
什么是 EDA?
探索性数据分析 (EDA) 是一种用于分析和汇总数据集的方法。大多数 EDA 技术都涉及到图形的使用。
泰坦尼克号数据集 –
它是用于理解机器学习基础的最流行的数据集之一。它包含了 RMS Titanic 上所有乘客的信息,但不幸的是,这艘船遇难了。该数据集可用于预测给定乘客是否幸存。
csv 文件可以从 Kaggle 下载。
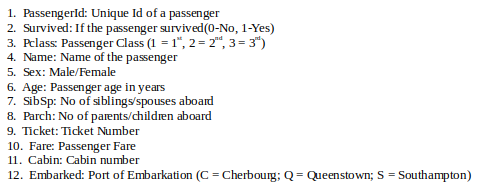
代码:使用 Pandas 加载数据
Python3
#importing pandas library
import pandas as pd
#loading data
titanic = pd.read_csv('...\input\train.csv')Python3
# View first five rows of the dataset
titanic.head()Python3
titanic.isnull().sum()Python3
import seaborn as sns
import matplotlib.pyplot as plt
# Countplot
sns.catplot(x ="Sex", hue ="Survived",
kind ="count", data = titanic)Python3
# Group the dataset by Pclass and Survived and then unstack them
group = titanic.groupby(['Pclass', 'Survived'])
pclass_survived = group.size().unstack()
# Heatmap - Color encoded 2D representation of data.
sns.heatmap(pclass_survived, annot = True, fmt ="d")Python3
# Violinplot Displays distribution of data
# across all levels of a category.
sns.violinplot(x ="Sex", y ="Age", hue ="Survived",
data = titanic, split = True)Python3
# Adding a column Family_Size
titanic['Family_Size'] = 0
titanic['Family_Size'] = titanic['Parch']+titanic['SibSp']
# Adding a column Alone
titanic['Alone'] = 0
titanic.loc[titanic.Family_Size == 0, 'Alone'] = 1
# Factorplot for Family_Size
sns.factorplot(x ='Family_Size', y ='Survived', data = titanic)
# Factorplot for Alone
sns.factorplot(x ='Alone', y ='Survived', data = titanic)Python3
# Divide Fare into 4 bins
titanic['Fare_Range'] = pd.qcut(titanic['Fare'], 4)
# Barplot - Shows approximate values based
# on the height of bars.
sns.barplot(x ='Fare_Range', y ='Survived',
data = titanic)Python3
# Countplot
sns.catplot(x ='Embarked', hue ='Survived',
kind ='count', col ='Pclass', data = titanic)海博恩:
它是一个用于统计可视化数据的Python库。 Seaborn 基于 Matplotlib 构建,提供了更好的界面和易用性。可以使用以下命令安装它,
pip3 安装 seaborn
代号:打印数据头
Python3
# View first five rows of the dataset
titanic.head()
输出 :

代码:检查 NULL 值
Python3
titanic.isnull().sum()
输出 :

具有空值的列是:Age、Cabin、Embarked。稍后需要用适当的值填充它们。
特征: Titanic 数据集大致有以下几类特征:
- 分类/名义:可以分为多个类别但没有顺序或优先级的变量。
例如。登船(C = 瑟堡;Q = 皇后镇;S = 南安普顿) - 二元:分类特征的子类型,其中变量只有两个类别。
例如:性别(男/女) - Ordinal :它们类似于分类特征,但它们有一个顺序(即可以排序)。
例如。 P类 (1, 2, 3) - 连续:它们可以占用列中最小值和最大值之间的任何值。
例如。年龄、票价 - Count :它们代表变量的计数。
例如。 SibSp, 帕奇 - 无用:它们对 ML 模型的最终结果没有贡献。在这里, PassengerId、Name、Cabin和Ticket可能属于这一类。
代码:图形分析
Python3
import seaborn as sns
import matplotlib.pyplot as plt
# Countplot
sns.catplot(x ="Sex", hue ="Survived",
kind ="count", data = titanic)
输出 :

仅通过观察图表,可以近似得出男性的存活率在20%左右,女性的存活率在75% 左右。因此,乘客是男性还是女性在决定一个人是否能够生存方面起着重要作用。
代码:Pclass(序数特征)vs Survived
Python3
# Group the dataset by Pclass and Survived and then unstack them
group = titanic.groupby(['Pclass', 'Survived'])
pclass_survived = group.size().unstack()
# Heatmap - Color encoded 2D representation of data.
sns.heatmap(pclass_survived, annot = True, fmt ="d")
输出:

它有助于确定高等级乘客的存活率是否高于低等级乘客,反之亦然。与2 级和 3 级相比, 1 级乘客的生存机会更高。这意味着Pclass对乘客的生存率有很大贡献。
代码:年龄(连续特征)与幸存者
Python3
# Violinplot Displays distribution of data
# across all levels of a category.
sns.violinplot(x ="Sex", y ="Age", hue ="Survived",
data = titanic, split = True)
输出 :
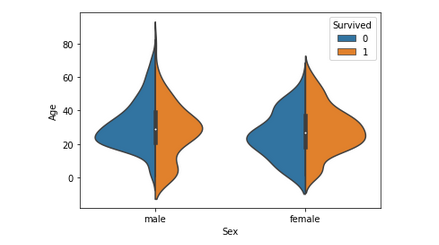
这张图表总结了获救的男性、女性和儿童的年龄范围。成活率是——
- 对孩子很好。
- 对 20-50 岁的女性来说较高。
- 男性随着年龄的增长而减少。
由于年龄列很重要,因此需要使用姓名列(根据称呼确定年龄 - 先生、夫人等)或使用回归量来填充缺失值。
在这一步之后,可以创建另一列——Age_Range (基于年龄列),并可以再次分析数据。
代码:Family_Size(计数特征)和 Family Size 的因子图。
Python3
# Adding a column Family_Size
titanic['Family_Size'] = 0
titanic['Family_Size'] = titanic['Parch']+titanic['SibSp']
# Adding a column Alone
titanic['Alone'] = 0
titanic.loc[titanic.Family_Size == 0, 'Alone'] = 1
# Factorplot for Family_Size
sns.factorplot(x ='Family_Size', y ='Survived', data = titanic)
# Factorplot for Alone
sns.factorplot(x ='Alone', y ='Survived', data = titanic)


Family_Size表示乘客家庭中的人数。它是通过对相应乘客的SibSp和Parch列求和来计算的。此外,还添加了另一列Alone以检查单独乘客与有家人的乘客的生存机会。
重要观察——
- 如果乘客独自一人,则存活率较低。
- 如果家庭人数大于 5,则生存机会会大大降低。
代码:票价条形图(连续特征)
Python3
# Divide Fare into 4 bins
titanic['Fare_Range'] = pd.qcut(titanic['Fare'], 4)
# Barplot - Shows approximate values based
# on the height of bars.
sns.barplot(x ='Fare_Range', y ='Survived',
data = titanic)
输出 :

票价表示乘客支付的票价。由于此列中的值是连续的,因此需要将它们放入单独的 bin 中(如Age功能所做的那样)以获得清晰的概念。可以得出结论,如果乘客支付更高的票价,则存活率更高。
代码:已启动特征的分类计数图
Python3
# Countplot
sns.catplot(x ='Embarked', hue ='Survived',
kind ='count', col ='Pclass', data = titanic)

一些值得注意的观察结果是:
- 大多数乘客从S登机。因此,缺失值可以用S填充。
- 大多数 3 级乘客从Q登机。
- 与 3 级相比,1 级和 2 级乘客的S看起来很幸运。
结论 :
- 可以删除的列是:
- PassengerId, Name, Ticket, Cabin:它们是字符串,不能分类,对结果贡献不大。
- 年龄、票价:而是保留相应的范围列。
- 与本文所述相比,可以使用更多的图形技术和更多的列相关性来分析巨量数据。
- EDA 完成后,生成的数据集可用于预测。