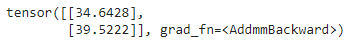PyTorch 入门
深度学习是机器学习的一个分支,其中编写了模仿人脑功能的算法。深度学习中最常用的库是 Tensorflow 和 PyTorch。由于有各种可用的深度学习框架,人们可能想知道何时使用 PyTorch。以下是人们可能更喜欢将 Pytorch 用于特定任务的原因。
Pytorch 是一个开源深度学习框架,提供Python和 C++ 接口。 Pytorch 位于 torch 模块内。在 PyTorch 中,需要处理的数据以张量的形式输入。
安装 PyTorch
如果您的系统中安装了 Anaconda Python包管理器,则通过在终端中运行以下命令来安装 PyTorch:
conda install pytorch torchvision cpuonly -c pytorch
如果您想在不将 PyTorch 显式安装到本地机器的情况下使用它,您可以使用 Google Colab。
PyTorch 张量
Pytorch 用于处理张量。张量是多维数组,如 n 维 NumPy 数组。但是,张量也可用于 GPU,而 NumPy 数组则不然。 PyTorch 加速了张量的科学计算,因为它具有各种内置功能。
向量是一维张量,矩阵是二维张量。在 C、C++ 和Java使用的张量和多维数组之间的一个显着区别是张量在所有维度上应该具有相同大小的列。此外,张量只能包含数字数据类型。
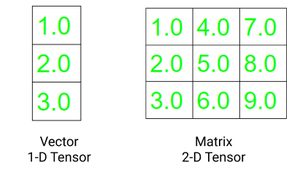
张量的两个基本属性是:
- 形状:指数组或矩阵的维数
- Rank:指的是张量中存在的维数
代码:
Python3
# importing torch
import torch
# creating a tensors
t1=torch.tensor([1, 2, 3, 4])
t2=torch.tensor([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
# printing the tensors:
print("Tensor t1: \n", t1)
print("\nTensor t2: \n", t2)
# rank of tensors
print("\nRank of t1: ", len(t1.shape))
print("Rank of t2: ", len(t2.shape))
# shape of tensors
print("\nRank of t1: ", t1.shape)
print("Rank of t2: ", t2.shape)Python3
# importing torch module
import torch
import numpy as np
# list of values to be stored as tensor
data1 = [1, 2, 3, 4, 5, 6]
data2 = np.array([1.5, 3.4, 6.8,
9.3, 7.0, 2.8])
# creating tensors and printing
t1 = torch.tensor(data1)
t2 = torch.Tensor(data1)
t3 = torch.as_tensor(data2)
t4 = torch.from_numpy(data2)
print("Tensor: ",t1, "Data type: ", t1.dtype,"\n")
print("Tensor: ",t2, "Data type: ", t2.dtype,"\n")
print("Tensor: ",t3, "Data type: ", t3.dtype,"\n")
print("Tensor: ",t4, "Data type: ", t4.dtype,"\n")Python3
# import torch module
import torch
# defining tensor
t = torch.tensor([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
# reshaping the tensor
print("Reshaping")
print(t.reshape(6, 2))
# resizing the tensor
print("\nResizing")
print(t.resize(2, 6))
# transposing the tensor
print("\nTransposing")
print(t.transpose(1, 0))Python3
# import torch module
import torch
# defining two tensors
t1 = torch.tensor([1, 2, 3, 4])
t2 = torch.tensor([5, 6, 7, 8])
# adding two tensors
print("tensor2 + tensor1")
print(torch.add(t2, t1))
# subtracting two tensor
print("\ntensor2 - tensor1")
print(torch.sub(t2, t1))
# multiplying two tensors
print("\ntensor2 * tensor1")
print(torch.mul(t2, t1))
# diving two tensors
print("\ntensor2 / tensor1")
print(torch.div(t2, t1))Python3
# importing torch
import torch
# creating a tensor
t1=torch.tensor(1.0, requires_grad = True)
t2=torch.tensor(2.0, requires_grad = True)
# creating a variable and gradient
z=100 * t1 * t2
z.backward()
# printing gradient
print("dz/dt1 : ", t1.grad.data)
print("dz/dt2 : ", t2.grad.data)Python3
class Model (nn.Module) :
def __init__(self):
super(Model, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_predPython3
# importing torch
import torch
# training input(X) and output(y)
X = torch.Tensor([[1], [2], [3],
[4], [5], [6]])
y = torch.Tensor([[5], [10], [15],
[20], [25], [30]])
class Model(torch.nn.Module):
# defining layer
def __init__(self):
super(Model, self).__init__()
self.linear = torch.nn.Linear(1, 1)
# implementing forward pass
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = torch.nn.Linear(1 , 1)
# defining loss function and optimizer
loss_fn = torch.nn.L1Loss()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.01 )
for epoch in range(1000):
# predicting y using initial weigths
y_pred = model(X.requires_grad_())
# loss calculation
loss = loss_fn(y_pred, y)
# calculating gradients
loss.backward()
# updating weights
optimizer.step()
optimizer.zero_grad()
# testing on new data
X = torch.Tensor([[7], [8]])
predicted = model(X)
print(predicted)输出:

在 PyTorch 中创建张量
在 PyTorch 中有多种创建张量的方法。张量可以包含单一数据类型的元素。我们可以使用Python列表或 NumPy 数组创建张量。 Torch 有 10 种适用于 GPU 和 CPU 的张量变体。以下是定义张量的不同方法。
torch.Tensor() : It copies the data and creates its tensor. It is an alias for torch.FloatTensor.
torch.tensor() : It also copies the data to create a tensor; however, it infers the data type automatically.
torch.as_tensor() : The data is shared and not copied in this case while creating the data and accepts any type of array for tensor creation.
torch.from_numpy() : It is similar to tensor.as_tensor() however it accepts only numpy array.
代码:
蟒蛇3
# importing torch module
import torch
import numpy as np
# list of values to be stored as tensor
data1 = [1, 2, 3, 4, 5, 6]
data2 = np.array([1.5, 3.4, 6.8,
9.3, 7.0, 2.8])
# creating tensors and printing
t1 = torch.tensor(data1)
t2 = torch.Tensor(data1)
t3 = torch.as_tensor(data2)
t4 = torch.from_numpy(data2)
print("Tensor: ",t1, "Data type: ", t1.dtype,"\n")
print("Tensor: ",t2, "Data type: ", t2.dtype,"\n")
print("Tensor: ",t3, "Data type: ", t3.dtype,"\n")
print("Tensor: ",t4, "Data type: ", t4.dtype,"\n")
输出:

在 Pytorch 中重构张量
我们可以在 PyTorch 中根据需要修改张量的形状和大小。我们还可以创建一个 nd 张量的转置。以下是根据需要更改张量结构的三种常用方法:
.reshape(a, b) : returns a new tensor with size a,b
.resize(a, b) : returns the same tensor with the size a,b
.transpose(a, b) : returns a tensor transposed in a and b dimension

一个 2*3 矩阵已被重塑并转置为 3*2。在这两种情况下,我们都可以可视化张量中元素排列的变化。
代码:
蟒蛇3
# import torch module
import torch
# defining tensor
t = torch.tensor([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
# reshaping the tensor
print("Reshaping")
print(t.reshape(6, 2))
# resizing the tensor
print("\nResizing")
print(t.resize(2, 6))
# transposing the tensor
print("\nTransposing")
print(t.transpose(1, 0))

PyTorch 中张量的数学运算
我们可以使用 Pytorch 对张量执行各种数学运算。执行数学运算的代码与使用 NumPy 数组的情况相同。下面是在张量中执行四个基本操作的代码。
蟒蛇3
# import torch module
import torch
# defining two tensors
t1 = torch.tensor([1, 2, 3, 4])
t2 = torch.tensor([5, 6, 7, 8])
# adding two tensors
print("tensor2 + tensor1")
print(torch.add(t2, t1))
# subtracting two tensor
print("\ntensor2 - tensor1")
print(torch.sub(t2, t1))
# multiplying two tensors
print("\ntensor2 * tensor1")
print(torch.mul(t2, t1))
# diving two tensors
print("\ntensor2 / tensor1")
print(torch.div(t2, t1))
输出:

要使用 Pytorch 进一步深入了解矩阵乘法,请参阅本文。
Pytorch 模块
PyTorch 库模块对于创建和训练神经网络至关重要。三个主要的库模块是 Autograd、Optim 和 nn。
# 1. Autograd 模块: autograd 提供了轻松计算梯度的功能,而无需为所有层明确手动实现前向和后向传递。
为了训练任何神经网络,我们执行反向传播来计算梯度。通过调用 .backward()函数,我们可以计算从根到叶的每个梯度。
代码:
蟒蛇3
# importing torch
import torch
# creating a tensor
t1=torch.tensor(1.0, requires_grad = True)
t2=torch.tensor(2.0, requires_grad = True)
# creating a variable and gradient
z=100 * t1 * t2
z.backward()
# printing gradient
print("dz/dt1 : ", t1.grad.data)
print("dz/dt2 : ", t2.grad.data)
输出:

# 2. Optim 模块: PyTorch Optium 模块,有助于实现各种优化算法。该软件包包含最常用的算法,如 Adam、SGD 和 RMS-Prop。要使用 torch.optim 我们首先需要构造一个 Optimizer 对象,它将保留参数并相应地更新它。首先,我们通过提供我们想要使用的优化器算法来定义优化器。我们在反向传播之前将梯度设置为零。然后为了更新参数,调用 optimizer.step()。
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) #defining optimizer
optimizer.zero_grad() #setting gradients to zero
optimizer.step() #parameter updation
# 3. nn 模块:这个包有助于构建神经网络。它用于构建层。
为了创建具有单层的模型,我们可以使用 nn.Sequential() 简单地定义它。
model = nn.Sequential( nn.Linear(in, out), nn.Sigmoid(), nn.Linear(_in, _out), nn.Sigmoid() )
对于非单序列模型的实现,我们通过子类化nn.Module类来定义模型。
蟒蛇3
class Model (nn.Module) :
def __init__(self):
super(Model, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
PyTorch 数据集和数据加载器
torch.utils.data.Dataset 类包含所有自定义数据集。我们需要实现两个方法 __len__() 和 __get_item__() 来创建我们自己的数据集类。
PyTorch Dataloader 有一个惊人的功能,即与自动批处理并行加载数据集。因此,它减少了顺序加载数据集的时间,从而提高了速度。
Syntax: DataLoader(dataset, shuffle=True, sampler=None, batch_sampler=None, batch_size=32)
PyTorch DataLoader 支持两种类型的数据集:
- 地图样式数据集:数据项被映射到索引。在这些数据集中,__get_item__() 方法用于检索每个项目的索引。
- 可迭代风格的数据集:在这些数据集中实现了 __iter__() 协议。数据样本按顺序检索。
请参阅在 PyTorch 中使用 DataLoader 以了解更多信息。
使用 PyTorch 构建神经网络
我们将在逐步实现中看到这一点:
- 数据集准备:由于 PyTorch 中的所有内容都以张量的形式表示,因此我们应该首先以张量的形式表示。
- 构建模型:为了首先构建一个中性网络,我们首先定义输入层、隐藏层和输出层的数量。我们还需要定义初始权重。权重矩阵的值是使用 torch.randn() 随机选择的。 Torch.randn() 返回一个由标准正态分布中的随机数组成的张量。
- 前向传播:数据被馈送到神经网络,并在权重和输入之间执行矩阵乘法。这可以使用手电筒轻松完成。
- 损失计算: PyTorch.nn 函数有多个损失函数。损失函数用于衡量预测值与目标值之间的误差。
- 反向传播:用于优化权重。改变权重以使损失最小化。
现在让我们从头开始构建一个神经网络:
蟒蛇3
# importing torch
import torch
# training input(X) and output(y)
X = torch.Tensor([[1], [2], [3],
[4], [5], [6]])
y = torch.Tensor([[5], [10], [15],
[20], [25], [30]])
class Model(torch.nn.Module):
# defining layer
def __init__(self):
super(Model, self).__init__()
self.linear = torch.nn.Linear(1, 1)
# implementing forward pass
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = torch.nn.Linear(1 , 1)
# defining loss function and optimizer
loss_fn = torch.nn.L1Loss()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.01 )
for epoch in range(1000):
# predicting y using initial weigths
y_pred = model(X.requires_grad_())
# loss calculation
loss = loss_fn(y_pred, y)
# calculating gradients
loss.backward()
# updating weights
optimizer.step()
optimizer.zero_grad()
# testing on new data
X = torch.Tensor([[7], [8]])
predicted = model(X)
print(predicted)
输出: