MongoDB 简介
术语:
MongoDB数据库可以称为所有集合的容器。
- 集合是一堆 MongoDB 文档。它类似于 RDBMS 中的表。
- 文档由字段组成。它类似于 RDBMS 中的元组,但在此处具有动态模式。同一集合的文档不需要具有相同的字段集
入门
安装 MongoDB 后,您可以在C:\ProgramFiles\MongoDB\ (默认位置)中看到所有已安装的文件。在C:\Program Files\MongoDB\Server\3.2\bin目录中,有一堆可执行文件,关于它们的简短描述是:
mongo: The Command Line Interface to interact with the db.
mongod: This is the database. Sets up the srver.
mongodump: It dumps out the Binary of the Database(BSON)
mongoexport: Exports the document to Json, CSV format
mongoimport: To import some data into the DB.
mongorestore: to restore anything that you’ve exported.
mongostat: Statistics of databases现在,您可以开始运行 MongoDB 服务器了。启动命令提示符并转到安装 MongoDB 可执行文件的位置( C:\Program Files\MongoDB\Server\3.2\bin\但此路径将来可能会更改)。只需输入“mongod” ,它就会弹出一个错误,指出路径\data\db不存在:
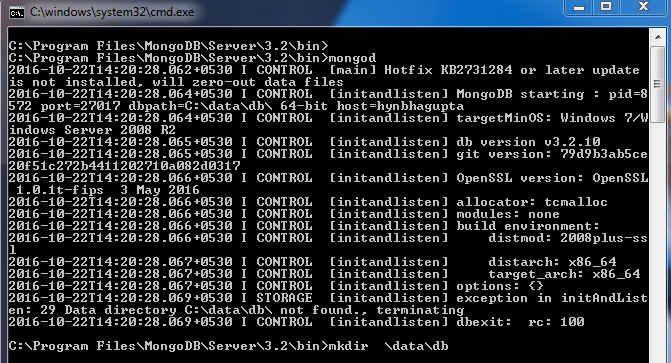
这意味着未找到C:\data\db的默认路径。所以你可以自己创建一个目录C:\data\db或者使用 mkdir 命令。您还可以使用“mongod”命令–dbpath
创建此目录后, “mongod”命令,它将在端口 27017 上启动服务器。
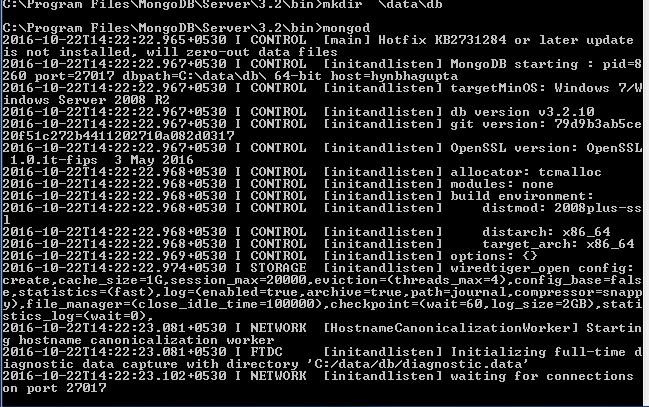
现在,我们需要启动我们的客户端。因此,打开另一个终端并将目录更改为 MongoDB 路径。只需输入“mongo” ,您的客户端就会启动,尝试连接到服务器。
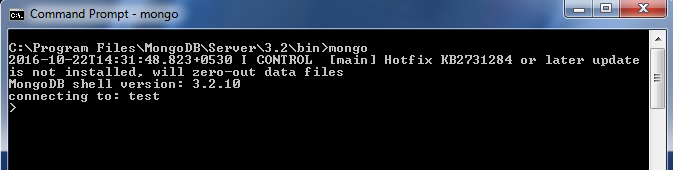
这将是用于交互和管理数据库的 CLI。这个 shell 有点像 JS 控制台。您可以尝试使用不同的 JS 命令来检查。由于我们的客户端已启动,我们现在可以开始处理数据库。我们可以看到正在使用的数据库被命名为“test” 。您可以使用“see dbs”查看数据库,并通过键入“use “local”等其他数据库。
请注意,没有现有的集合。这可以通过键入命令“show collections” 。
让我们从向数据库中添加一些数据开始。我们可以通过方法db.createCollection(name, { size : ..., capped : ..., max : ... } )
但是我们已经创建了一个随机生成的 json 文件(员工数据),我们将通过键入将其导入到我们的数据库中
mongoimport --jsonArray --db test --collection employee_data <
C:\mongoJson\employee_data.json这将导入由数据库“test” “employee_data”的集合中给出的路径引用的 Employee 数据 json 文档。
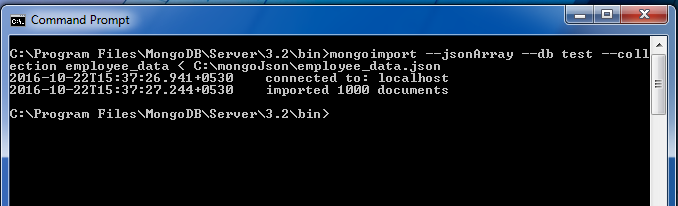
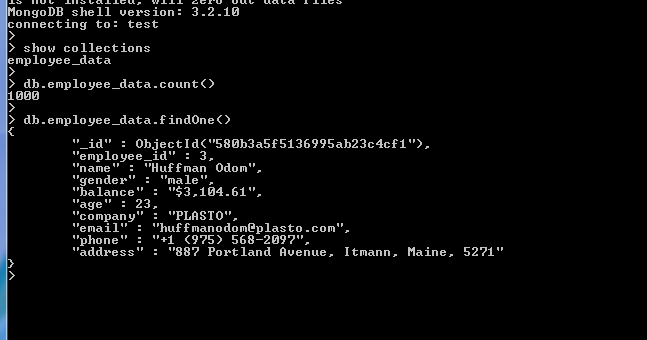
现在要确保导入集合,您可以在 shell 中“show collections”您可以使用count() 、 find() 、 findOne()对文档进行一些非常基本的查询。
您可以看到,在每个文档中,都有一个名为“_id”的字段,该字段在导入的数据中没有提供。原因是 MongoDB 提供了一个默认的“_id” (如果没有明确提供),它是一个 12 字节的十六进制数,可确保每个文档的唯一性。您甚至可以更改此“_id”字段,但不建议这样做。
索引:如果您的查询返回多个文档,您也可以使用索引。例如, db.employee_data.find()返回集合中的所有文档,但如果您只想要第 7 个文档,只需执行db.employee_data.find()[6] ,它将返回特定文档。 [注意:这里的索引从 0 开始]。
预测:假设对于一个查询,您只需要一些特定的详细信息,而不是文档中的整个详细信息集。您可以为此使用投影。在您的查询对象之后,只需将所需字段设为 1,其他字段将自动假定为 0。但请记住, “_id”字段总是被隐式假定为 1,如果您不想看到看起来很丑的“_id”字段,那么您需要在投影中通过“_id : 0”
查询:
1. 找到公司“GEEKS FOR GEEKS”的员工人数
> db.employee_data.find( { company= “GEEKS FOR GEEKS” } ).count()2.显示所有名为“Sandeep Jain”的员工的详细信息
> db.employee_data.find( { name: “Sandeep Jain” }在这里,所有与给定名称匹配的文档都会显示出来。
3. 显示名为“Harshit Gupta”的员工的年龄、性别和电子邮件,但不显示“_id”。 (假设只有一名名为 Harshit Gupta 的员工)。投影的使用
> db.employee_data.find( { name: “Harshit Gupta” }, { _id:0, age:1, gender:1, email:1 } )我们还可以将查询的输出存储到变量中,然后也可以使用它们进行有趣的查询。
4. 打印所有女性员工的姓名。
> var femaleEmp = db.employee_data.find( { gender: “female” } )
for ( var i = 0 ; i < femaleEmp.count() ; i++){
print ( femaleEmp[i].name)
}
> db.employee_data.find( { gender: "female" }, { _id:0, name:1 } )请注意,第一个解决方案只打印出名称,而第二个解决方案以对象格式打印。
Harshit Gupta 的文章:
总部位于加尔各答的 Harshit Gupta 是一位活跃的博主,对撰写有关算法的文章有着浓厚的兴趣,技术博客、故事和个人生活经历。除了对写作充满热情之外,他还喜欢编码和跳舞。目前在 AMD 工作,他是 GeeksforGeeks 的活跃博客撰稿人。您可以通过 harritguptablog.wordpress.com 与他联系。