- 线性回归(Python实现)(1)
- Python线性回归(1)
- python中的线性回归(1)
- Python线性回归
- python 线性回归 - Python (1)
- python代码示例中的线性回归
- R-线性回归
- R线性回归(1)
- 线性回归 (1)
- R线性回归
- R-线性回归(1)
- python 线性回归 - Python 代码示例
- 岭回归实现python(1)
- 岭回归实现python代码示例
- 线性回归 - Javascript 代码示例
- Python中的单变量线性回归
- Python中的单变量线性回归(1)
- 使用Python从零开始实现线性回归
- 使用Python从零开始实现线性回归(1)
- 线性回归 - 无论代码示例
- 回归算法-线性回归
- 回归算法-线性回归(1)
- TensorFlow中的线性回归(1)
- TensorFlow-线性回归(1)
- TensorFlow-线性回归
- TensorFlow中的线性回归
- 在Python中解决线性回归
- 实现线性外推的程序
- 实现线性外推的程序(1)
📅 最后修改于: 2020-04-28 04:48:13 🧑 作者: Mango
本文讨论了线性回归的基础知识及其在Python编程语言中的实现。
线性回归是一种统计方法,用于对因变量与给定的一组自变量之间的关系进行建模。
注意:在本文中,为简单起见,我们将因变量称为响应,将自变量称为函数。
为了提供对线性回归的基本了解,我们从线性回归的最基本版本开始,即简单线性回归。
简单线性回归
简单线性回归是一种使用单个特征预测响应的方法。
假定两个变量线性相关。因此,我们尝试找到一个线性函数,该线性函数根据特征或自变量(x)尽可能准确地预测响应值(y)。
让我们考虑一个数据集,其中每个特征x的响应y的值分别为:


为了通用,我们定义:
x作为特征向量,即x = [x_1,x_2,…。,x_n],
y作为响应向量,即y = [y_1,y_2,…。,y_n]
对于n个观察值(在上面的示例中,n = 10)。
以上数据集的散点图如下所示:
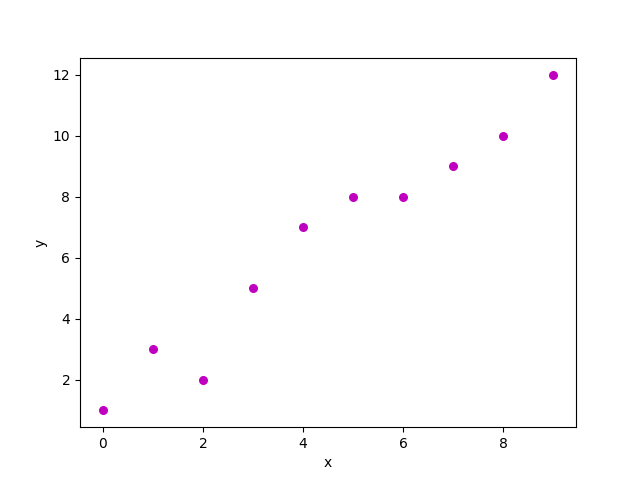

现在,任务是找到最适合连接上述散点图的线,以便我们可以预测任何新特征值的响应。(即数据集中不存在x的值)
这条线称为回归线。
回归线的等式表示为:

这里,
- h(x_i)代表第i次观察的预测响应值。
- b_0和b_1是回归系数,分别表示y截距和回归线的斜率。
要创建我们的模型,我们必须“学习”或估计回归系数b_0和b_1的值。一旦我们估计了这些系数,就可以使用该模型来预测响应!
在本文中,我们将使用最小二乘法。
现在考虑:

在此,e_i是第i次观察中的残留误差。
因此,我们的目标是使总残留误差最小。
我们将平方误差或成本函数J定义为:

我们的任务是找到j(b_0,b_1)最小的b_0和b_1的值!
在不涉及数学细节的情况下,我们在此处显示结果:


其中SS_xy是y和x的交叉偏差之和:

SS_xx是x的平方偏差的总和:

注意:可在此处找到用于在简单线性回归中找到最小二乘估计的完整推导。
下面给出的是上述技术在我们的小型数据集上的Python实现:
import numpy as np
import matplotlib.pyplot as plt
def estimate_coef(x, y):
# 观察点数
n = np.size(x)
# x和y向量的均值
m_x, m_y = np.mean(x), np.mean(y)
# 计算关于x的交叉偏差和偏差
SS_xy = np.sum(y*x) - n*m_y*m_x
SS_xx = np.sum(x*x) - n*m_x*m_x
# 计算回归系数
b_1 = SS_xy / SS_xx
b_0 = m_y - b_1*m_x
return(b_0, b_1)
def plot_regression_line(x, y, b):
# 将实际点绘制为散点图
plt.scatter(x, y, color = "m",
marker = "o", s = 30)
# 预测响应向量
y_pred = b[0] + b[1]*x
# 绘制回归线
plt.plot(x, y_pred, color = "g")
# 贴标签
plt.xlabel('x')
plt.ylabel('y')
# 显示图的功能
plt.show()
def main():
# 观察
x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
y = np.array([1, 3, 2, 5, 7, 8, 8, 9, 10, 12])
# 估计系数
b = estimate_coef(x, y)
print("Estimated coefficients:\nb_0 = {} \
\nb_1 = {}".format(b[0], b[1]))
# 绘制回归线
plot_regression_line(x, y, b)
if __name__ == "__main__":
main()上面这段代码的输出是:
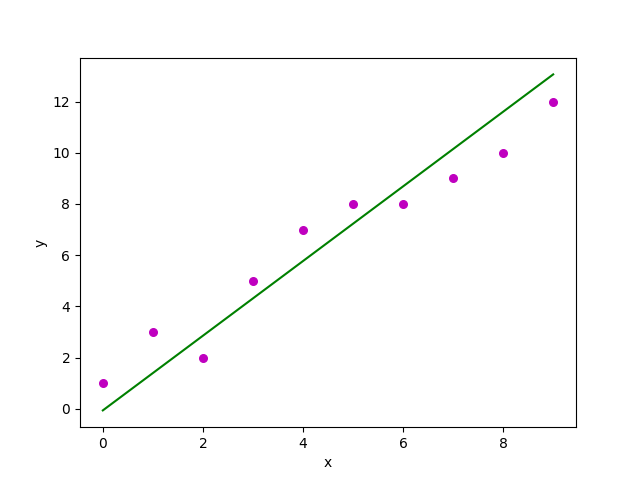
Estimated coefficients:
b_0 = -0.0586206896552
b_1 = 1.45747126437得到的图形如下所示:

多元线性回归
多元线性回归尝试通过将线性方程式拟合到观测数据来对两个或多个特征与响应之间的关系进行建模。
显然,它不过是简单线性回归的扩展。
考虑一个具有p个特征(或自变量)和一个响应(或因变量)的数据集。
此外,数据集包含n行/观察值。
我们定义:
X(特征矩阵)=大小为n X p的矩阵,其中x_ {ij}表示第i个观测的第j个特征的值。
所以,

和
y(响应向量)=大小为n的向量,其中y_ {i}表示第i次观察的响应值。

的回归直线为p作为特征被表示为:

其中h(X_I)的预测响应值对第i个观察和B_0,B_1,…,b_p是回归系数。
另外,我们可以写:

其中e_i代表第i次观察中的残留误差。
通过将特征矩阵X表示为:我们可以进一步推广线性模型:

现在,线性模型可以用矩阵表示为:

其中,


现在,我们使用最小二乘法确定b的估计值,即b’ 。
如已经说明的那样,最小二乘法倾向于确定总残差最小的b’。
我们在这里直接给出结果:

其中’代表矩阵的转置,而-1代表矩阵逆。
知道最小二乘估计值b’,现在可以将多元线性回归模型估计为:

其中y’是估计的响应向量。
注意:可以在此处找到在多元线性回归中获得最小二乘估计的完整推导。
下面给出的是使用Scikit-learn在波士顿房屋价格数据集上的多元线性回归技术的实现。
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model, metrics
# 加载波士顿数据集
boston = datasets.load_boston(return_X_y=False)
# 定义特征矩阵(X)和响应向量(y)
X = boston.data
y = boston.target
# 将X和y分为训练和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4,
random_state=1)
# 创建线性回归对象
reg = linear_model.LinearRegression()
# 使用训练集训练模型
reg.fit(X_train, y_train)
# 回归系数
print('系数: \n', reg.coef_)
# 方差得分:1表示完美的预测
print('Variance score: {}'.format(reg.score(X_test, y_test)))
# 残差图绘制,设置图样式
plt.style.use('fivethirtyeight')
## 绘制训练数据中的残留误差
plt.scatter(reg.predict(X_train), reg.predict(X_train) - y_train,
color = "green", s = 10, label = 'Train data')
## 绘制测试数据中的残留误差
plt.scatter(reg.predict(X_test), reg.predict(X_test) - y_test,
color = "blue", s = 10, label = 'Test data')
## 零残留误差绘制线
plt.hlines(y = 0, xmin = 0, xmax = 50, linewidth = 2)
## 画图
plt.legend(loc = 'upper right')
## 画title
plt.title("Residual errors")
## 显示图的功能
plt.show()上面程序的输出如下所示:
系数:
[ -8.80740828e-02 6.72507352e-02 5.10280463e-02 2.18879172e+00
-1.72283734e+01 3.62985243e+00 2.13933641e-03 -1.36531300e+00
2.88788067e-01 -1.22618657e-02 -8.36014969e-01 9.53058061e-03
-5.05036163e-01]
Variance score: 0.720898784611和残差图如下所示:
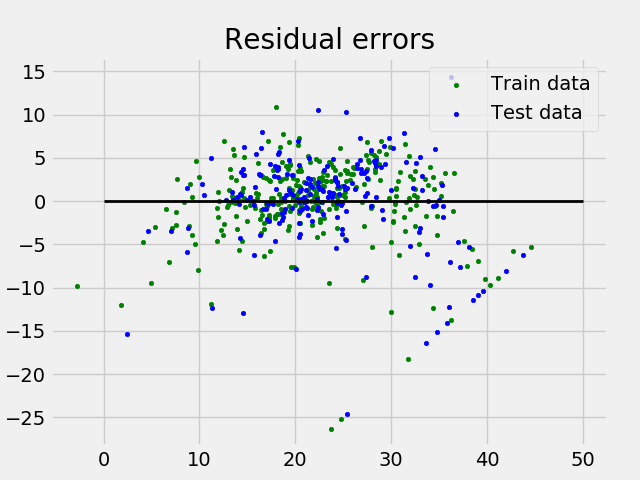

在以上示例中,我们使用“ 解释方差得分”确定准确性得分。
我们定义:
explainary_variance_score = 1 – Var {y – y’} / Var {y}
其中y’是估计的目标输出,y是对应的(正确)目标输出,Var是方差,即标准偏差的平方。
可能的最高分是1.0,数值越低越好。
假设条件
下面给出的是线性回归模型针对应用了该数据集的基本假设:
- 线性关系:响应和特征变量之间的关系应为线性。线性假设可以使用散点图进行测试。如下图所示,第一个数字表示线性相关的变量,而第二个和第三个数字中的变量很可能是非线性的。因此,第一个数字将使用线性回归给出更好的预测。


- 很少或没有多重共线性:假设数据中很少或没有多重共线性。当特征(或自变量)彼此不独立时,会发生多重共线性。
- 很少或没有自相关:另一个假设是数据中很少或没有自相关。当残余误差彼此不独立时,就会发生自相关。您可以在此处参考以获取对该主题的更多了解。
- 同质性:同质性描述了一种情况,其中误差项(即,自变量与因变量之间的关系中的“噪声”或随机扰动)在自变量的所有值上均相同。如下图所示,图1具有同质性,而图2具有异质性。


到达本文结尾时,我们在下面讨论线性回归的一些应用。
应用范围:
1.趋势线:趋势线表示一些定量数据随时间推移的变化(例如GDP,石油价格等)。这些趋势通常遵循线性关系。因此,线性回归可以应用于预测未来价值。但是,在其他潜在变化可能影响数据的情况下,此方法缺乏科学有效性。
2.经济学:线性回归是经济学中的主要经验工具。例如,它用于预测消费支出,固定投资支出,库存投资,一国出口的购买,进口支出,持有流动资产的需求,劳动力需求和劳动力供应。
3.金融:资本价格资产模型使用线性回归分析和量化投资的系统风险。
4.生物学:线性回归用于对生物系统中参数之间的因果关系进行建模。