- R线性回归(1)
- R-线性回归
- R-线性回归(1)
- 线性回归 (1)
- R线性回归
- python中的线性回归(1)
- Python线性回归
- Python线性回归(1)
- python代码示例中的线性回归
- 线性回归 - Javascript 代码示例
- 线性回归 - 无论代码示例
- ML-线性回归与逻辑回归
- ML-线性回归与逻辑回归(1)
- 回归python(1)
- 毫升 |线性回归与逻辑回归(1)
- 毫升 |线性回归与逻辑回归
- python 线性回归 - Python (1)
- TensorFlow-线性回归
- TensorFlow-线性回归(1)
- TensorFlow中的线性回归
- TensorFlow中的线性回归(1)
- Python中的单变量线性回归
- Python中的单变量线性回归(1)
- python 线性回归 - Python 代码示例
- 线性回归(Python实现)
- 线性回归(Python实现)
- 线性回归(Python实现)(1)
- 回归python代码示例
- 统计-线性回归
📅 最后修改于: 2020-12-10 05:39:02 🧑 作者: Mango
线性回归简介
线性回归可以定义为统计模型,用于分析因变量与给定的一组自变量之间的线性关系。变量之间的线性关系意味着,当一个或多个自变量的值更改(增加或减少)时,因变量的值也将相应更改(增加或减少)。
数学上的关系可以借助以下方程式来表示-
Y = mX + b
在这里,Y是我们试图预测的因变量
X是我们用来进行预测的因变量。
m是回归线的斜率,代表X对Y的影响
b是一个常数,称为Y截距。如果X = 0,则Y等于b。
此外,线性关系本质上可以是正或负,如下所述-
正线性关系
如果自变量和因变量都增加,则线性关系称为正。下图可以帮助理解-
负线性关系
如果自增和因变量减小,则线性关系将称为正。下图可以帮助理解-
线性回归的类型
线性回归具有以下两种类型-
- 简单线性回归
- 多元线性回归
简单线性回归(SLR)
它是线性回归的最基本版本,可使用单个功能预测响应。 SLR中的假设是两个变量线性相关。
Python实现
我们可以通过两种方式在Python中实现SLR,一种是提供自己的数据集,另一种是使用scikit-learn Python库中的数据集。
示例1-在下面的Python实现示例中,我们使用自己的数据集。
首先,我们将从导入必要的包开始,如下所示:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
接下来,定义一个函数,该函数将计算SLR的重要值-
def coef_estimation(x, y):
以下脚本行将给出观察值n-
n = np.size(x)
x和y向量的均值可以计算如下-
m_x, m_y = np.mean(x), np.mean(y)
我们可以找到关于x的交叉偏差和偏差,如下所示:
SS_xy = np.sum(y*x) - n*m_y*m_x
SS_xx = np.sum(x*x) - n*m_x*m_x
接下来,回归系数即b可以如下计算:
b_1 = SS_xy / SS_xx
b_0 = m_y - b_1*m_x
return(b_0, b_1)
接下来,我们需要定义一个函数,该函数将绘制回归线以及预测响应向量-
def plot_regression_line(x, y, b):
以下脚本行将实际点绘制为散点图-
plt.scatter(x, y, color = "m", marker = "o", s = 30)
以下脚本行将预测响应向量-
y_pred = b[0] + b[1]*x
以下脚本行将绘制回归线并在其上放置标签-
plt.plot(x, y_pred, color = "g")
plt.xlabel('x')
plt.ylabel('y')
plt.show()
最后,我们需要定义main()函数以提供数据集并调用上面定义的函数-
def main():
x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
y = np.array([100, 300, 350, 500, 750, 800, 850, 900, 1050, 1250])
b = coef_estimation(x, y)
print("Estimated coefficients:\nb_0 = {} \nb_1 = {}".format(b[0], b[1]))
plot_regression_line(x, y, b)
if __name__ == "__main__":
main()
输出
Estimated coefficients:
b_0 = 154.5454545454545
b_1 = 117.87878787878788
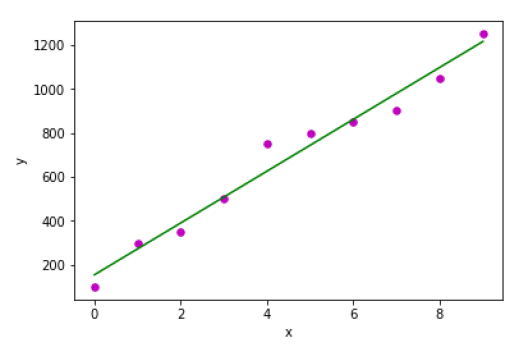
示例2-在以下Python实现示例中,我们使用scikit-learn的糖尿病数据集。
首先,我们将从导入必要的包开始,如下所示:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
接下来,我们将加载糖尿病数据集并创建其对象-
diabetes = datasets.load_diabetes()
在实现SLR时,我们将仅使用一种功能,如下所示-
X = diabetes.data[:, np.newaxis, 2]
接下来,我们需要将数据分为以下训练集和测试集:
X_train = X[:-30]
X_test = X[-30:]
接下来,我们需要将目标分为训练集和测试集,如下所示:
y_train = diabetes.target[:-30]
y_test = diabetes.target[-30:]
现在,要训练模型,我们需要创建线性回归对象,如下所示:
regr = linear_model.LinearRegression()
接下来,使用以下训练集训练模型:
regr.fit(X_train, y_train)
接下来,使用测试集进行预测,如下所示:
y_pred = regr.predict(X_test)
接下来,我们将打印一些系数,例如MSE,方差得分等,如下所示-
print('Coefficients: \n', regr.coef_)
print("Mean squared error: %.2f" % mean_squared_error(y_test, y_pred))
print('Variance score: %.2f' % r2_score(y_test, y_pred))
现在,绘制输出,如下所示:
plt.scatter(X_test, y_test, color='blue')
plt.plot(X_test, y_pred, color='red', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
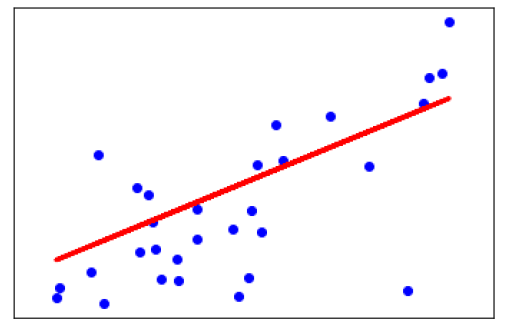
输出
Coefficients:
[941.43097333]
Mean squared error: 3035.06
Variance score: 0.41
多元线性回归(MLR)
简单线性回归的扩展是使用两个或多个功能预测响应的方法。数学上,我们可以解释如下-
考虑具有n个观测值,p个特征(即自变量)和y作为一个响应(即因变量)的数据集,p个特征的回归线可以如下计算:
$$ h(x_ {i})= b_ {0} + b_ {1} x_ {i1} + b_ {2} x_ {i2} + … + b_ {p} x_ {ip} $$
在此,h(x i )是预测响应值,b 0 ,b 1 ,b 2 …,b p是回归系数。
多个线性回归模型始终将数据中的误差称为残留误差,该误差会按以下方式更改计算:
$$ h(x_ {i})= b_ {0} + b_ {1} x_ {i1} + b_ {2} x_ {i2} + … + b_ {p} x_ {ip} + e_ {i} $$
我们还可以将上面的等式写成如下-
$$ y_ {i} = h(x_ {i})+ e_ {i} \:or \:e_ {i} = y_ {i}-h(x_ {i})$$
Python实现
在此示例中,我们将使用来自scikit learning的Boston住房数据集-
首先,我们将从导入必要的包开始,如下所示:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model, metrics
接下来,按如下方式加载数据集:
boston = datasets.load_boston(return_X_y=False)
以下脚本行将定义特征矩阵X和响应向量Y-
X = boston.data
y = boston.target
接下来,将数据集分为训练集和测试集,如下所示:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.7, random_state=1)
例
现在,创建线性回归对象并按如下所示训练模型-
reg = linear_model.LinearRegression()
reg.fit(X_train, y_train)
print('Coefficients: \n', reg.coef_)
print('Variance score: {}'.format(reg.score(X_test, y_test)))
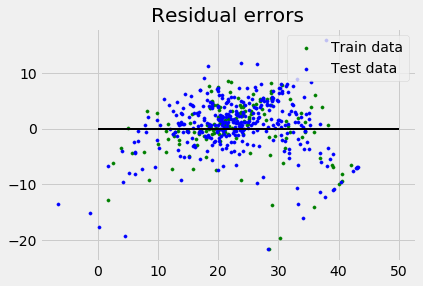
plt.style.use('fivethirtyeight')
plt.scatter(reg.predict(X_train), reg.predict(X_train) - y_train,
color = "green", s = 10, label = 'Train data')
plt.scatter(reg.predict(X_test), reg.predict(X_test) - y_test,
color = "blue", s = 10, label = 'Test data')
plt.hlines(y = 0, xmin = 0, xmax = 50, linewidth = 2)
plt.legend(loc = 'upper right')
plt.title("Residual errors")
plt.show()
输出
Coefficients:
[
-1.16358797e-01 6.44549228e-02 1.65416147e-01 1.45101654e+00
-1.77862563e+01 2.80392779e+00 4.61905315e-02 -1.13518865e+00
3.31725870e-01 -1.01196059e-02 -9.94812678e-01 9.18522056e-03
-7.92395217e-01
]
Variance score: 0.709454060230326
假设条件
以下是关于由线性回归模型建立的数据集的一些假设-
多重共线性-线性回归模型假设数据中很少或没有多重共线性。基本上,当自变量或要素具有相关性时,就会发生多重共线性。
自相关-另一个假设是线性回归模型所假设的是,数据中几乎没有自相关。基本上,当残差之间存在依赖性时,就会发生自相关。
变量之间的关系-线性回归模型假定响应变量和特征变量之间的关系必须是线性的。