📌 相关文章
- 测试数据 (1)
- 测试数据(1)
- 测试数据
- 数据挖掘——聚类分析(1)
- 数据挖掘-聚类分析
- 数据挖掘——聚类分析
- 数据挖掘-聚类分析(1)
- 测试数据 - 任何代码示例
- Biopython-聚类分析
- Biopython-聚类分析(1)
- Python|使用 Sklearn 创建测试数据集
- Python|使用 Sklearn 创建测试数据集(1)
- 测试数据管理(1)
- 测试数据管理
- 什么是测试数据 - TypeScript (1)
- 如何使用 R 编程进行层次聚类分析?
- 如何使用 R 编程进行层次聚类分析?(1)
- 什么是测试数据 - TypeScript 代码示例
- K means聚类Python–简介
- K means聚类Python–简介(1)
- 预测测试数据(1)
- 预测测试数据
- 毫升 | K-means++ 算法(1)
- 毫升 | K-means++ 算法
- 如何生成测试数据 - TypeScript 代码示例
- 你如何生成测试数据 - TypeScript 代码示例
- R 编程中的 K-Means 聚类
- R 编程中的 K-Means 聚类(1)
- 在 api 中生成测试数据 - 任何代码示例
📜 在Python中使用K-Means聚类分析测试数据
📅 最后修改于: 2020-04-22 11:47:46 🧑 作者: Mango
本文演示了使用open-cv库在样本随机数据上进行K均值聚类的示例。
先决条件: Numpy
让我们首先使用matplot-lib工具可视化具有多项函数。
# 导入所需的工具
import numpy as np
from matplotlib import pyplot as plt
# 创建两个测试数据
X = np.random.randint(10,35,(25,2))
Y = np.random.randint(55,70,(25,2))
Z = np.vstack((X,Y))
Z = Z.reshape((50,2))
# convert to np.float32
Z = np.float32(Z)
plt.xlabel('Test Data')
plt.ylabel('Z samples')
plt.hist(Z,256,[0,256])
plt.show()这里的“ Z”是一个大小为100的数组,值的范围从0到255。现在,将“ z”reshape为列向量。如果存在多个功能,它将更加有用。然后将数据更改为np.float32类型。
输出:
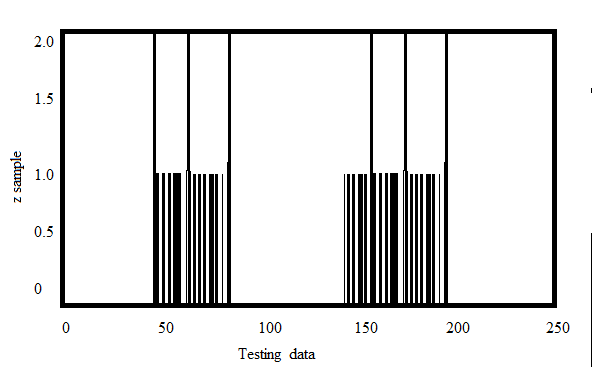

现在,将k-Means聚类算法应用于上述测试数据中的示例,并查看其行为。
涉及的步骤:
1)首先,我们需要设置测试数据。
2)定义标准并应用kmeans()。
3)现在分离数据。
4)最后绘制数据。
import numpy as np
import cv2
from matplotlib import pyplot as plt
X = np.random.randint(10,45,(25,2))
Y = np.random.randint(55,70,(25,2))
Z = np.vstack((X,Y))
# 转换为np.float32
Z = np.float32(Z)
# 定义条件并应用kmeans()
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret,label,center = cv2.kmeans(Z,2,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS)
# 现在分离数据
A = Z[label.ravel()==0]
B = Z[label.ravel()==1]
# 绘制数据
plt.scatter(A[:,0],A[:,1])
plt.scatter(B[:,0],B[:,1],c = 'r')
plt.scatter(center[:,0],center[:,1],s = 80,c = 'y', marker = 's')
plt.xlabel('Test Data'),plt.ylabel('Z samples')
plt.show()输出:
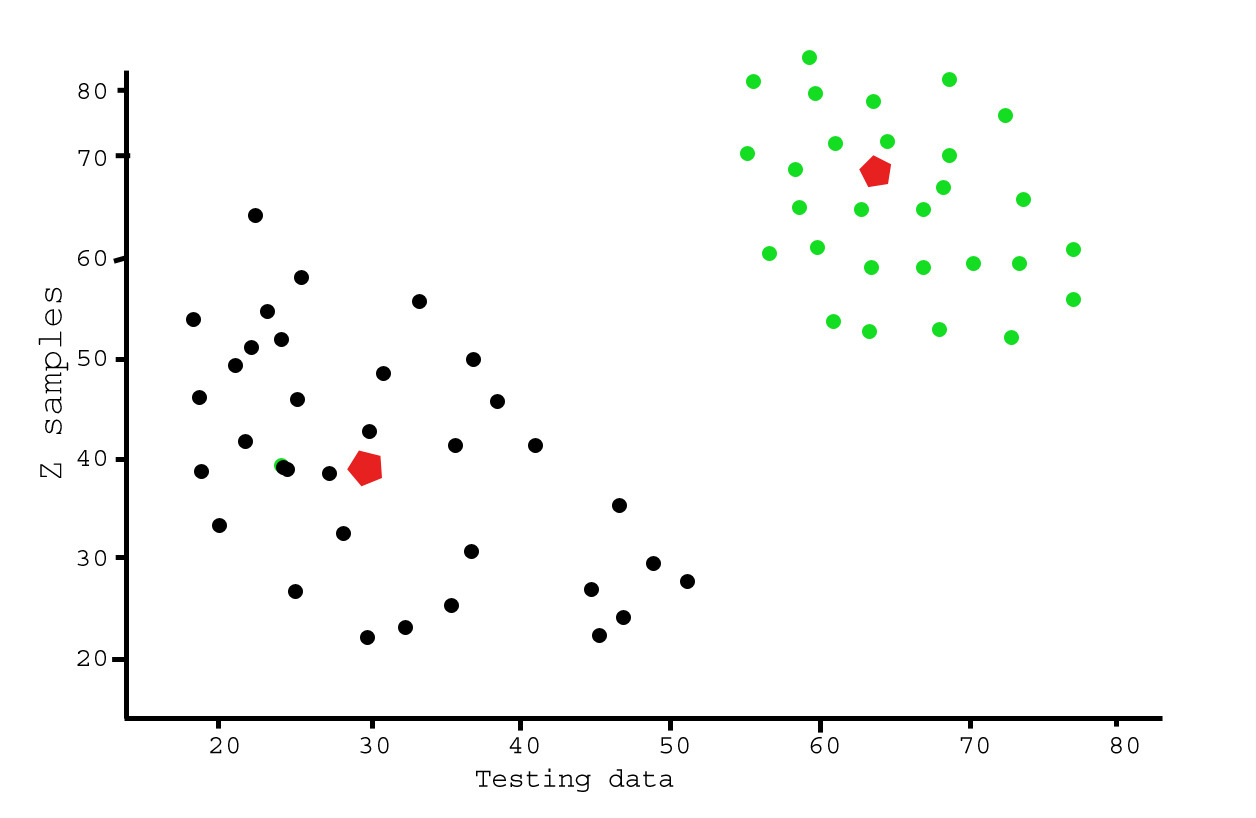

此示例旨在说明k均值将在哪里产生直观可能的聚类。
应用:
1)识别癌性数据。
2)对学生学习成绩的预测。
3)药物活性预测。