- 软件设计基础(1)
- 软件设计基础
- 圈复杂度(1)
- 圈复杂度
- 圈复杂度
- 圈复杂度
- 软件工程|软件设计(1)
- 软件工程|软件设计
- 软件设计策略
- 软件设计原理(1)
- 软件设计原理
- 时间复杂度和空间复杂度
- 时间复杂度和空间复杂度(1)
- 软件工程 |软件设计过程(1)
- 软件工程 |软件设计过程
- 软件工程|软件设计原理
- 软件工程|软件设计原理(1)
- 软件设计流程介绍|设置 2
- 软件设计和软件架构的区别
- 软件设计和软件架构的区别(1)
- O(1)复杂度的前n个奇数之和
- O(1)复杂度的前n个奇数之和(1)
- 如何在软件设计中创建线框?(1)
- 如何在软件设计中创建线框?
- SQL查询复杂度
- SQL查询复杂度(1)
- 软件设计和软件体系结构之间的区别
- 设置时间复杂度python(1)
- python 排序复杂度 - Python (1)
📅 最后修改于: 2021-01-07 06:27:14 🧑 作者: Mango
术语“复杂性”表示事件或事物的状态,它们具有多个相互关联的链接和高度复杂的结构。在软件编程中,随着软件设计的实现,元件的数量及其相互联系逐渐变得庞大,这一次变得难以理解。
如果不使用复杂性指标和度量,则很难评估软件设计的复杂性。让我们看看三个重要的软件复杂性度量。
霍尔斯特德的复杂性衡量
1977年,莫里斯·霍华德·霍尔斯特德(Maurice Howard Halstead)先生引入了衡量软件复杂性的指标。 Halstead的度量取决于程序及其度量的实际实现,这些度量及其度量以静态方式直接从源代码的运算符和操作数计算而来。它允许评估C / C++ / Java源代码的测试时间,词汇,大小,难度,错误以及工作量。
根据Halstead所说,“计算机程序是一种算法的实现,被认为是可以归类为运算符或操作数的令牌的集合”。 Halstead度量标准将程序视为运算符及其相关操作数的序列。
他定义了各种指标来检查模块的复杂性。
| Parameter | Meaning |
|---|---|
| n1 | Number of unique operators |
| n2 | Number of unique operands |
| N1 | Number of total occurrence of operators |
| N2 | Number of total occurrence of operands |
当我们选择源文件以在Metric Viewer中查看其复杂性详细信息时,Metric报告中将显示以下结果:
| Metric | Meaning | Mathematical Representation |
|---|---|---|
| n | Vocabulary | n1 + n2 |
| N | Size | N1 + N2 |
| V | Volume | Length * Log2 Vocabulary |
| D | Difficulty | (n1/2) * (N1/n2) |
| E | Efforts | Difficulty * Volume |
| B | Errors | Volume / 3000 |
| T | Testing time | Time = Efforts / S, where S=18 seconds. |
圈复杂度测度
每个程序都包含要执行以执行某些任务的语句以及其他决定需要执行哪些语句的决策语句。这些决策结构改变了程序的流程。
如果我们比较两个相同大小的程序,则随着程序的控制频繁跳转,具有更多决策声明的程序将更加复杂。
1976年,McCabe提出了“循环复杂性度量”以量化给定软件的复杂性。它是一种基于图的模型,它基于程序的决策结构,例如if-else,do-while,repeat-until,switch-case和goto语句。
制作流量控制图的过程:
- 将程序分成较小的块,由决策结构界定。
- 创建代表这些节点中的每个节点的节点。
- 如下连接节点:
-
如果控制权可以从块i转移到块j
画圆弧
-
从出口节点到入口节点
画一条弧。
为了计算程序模块的圈复杂度,我们使用以下公式-
V(G) = e – n + 2
Where
e is total number of edges
n is total number of nodes
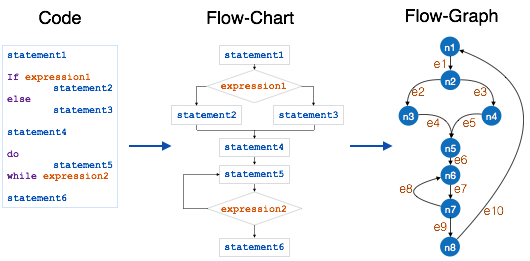
上述模块的圈复杂度为
e = 10
n = 8
Cyclomatic Complexity = 10 - 8 + 2
= 4
根据P. Jorgensen的说法,模块的环复杂度不应超过10。
功能点
它广泛用于衡量软件的大小。功能点专注于系统提供的功能。系统的特征和功能用于衡量软件的复杂性。
功能点依靠五个参数,分别是外部输入,外部输出,逻辑内部文件,外部接口文件和外部查询。为了考虑软件的复杂性,将每个参数进一步分类为简单,平均或复杂。
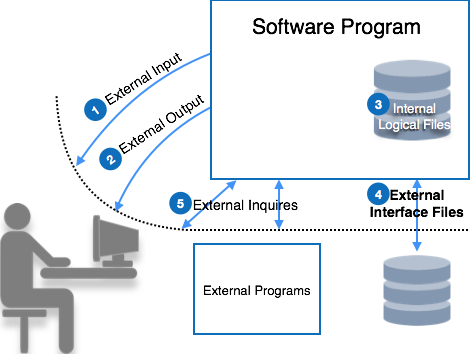
让我们看一下函数点的参数:
外部输入
从外部到系统的每个唯一输入都被视为外部输入。测量输入的唯一性,因为没有两个输入应具有相同的格式。这些输入可以是数据或控制参数。
-
简单-如果输入计数低并且影响较少的内部文件
-
复杂-如果输入计数很高并且会影响更多内部文件
-
平均-在简单和复杂之间。
外部输出
系统提供的所有输出类型都计入此类别。如果输出的输出格式和/或处理是唯一的,则认为输出是唯一的。
-
简单-如果输出数量少
-
复杂-如果输出计数很高
-
平均-在简单和复杂之间。
逻辑内部文件
每一个软件系统维护,以保持其功能的信息和正常函数的内部文件。这些文件保存系统的逻辑数据。该逻辑数据可以包含功能数据和控制数据。
-
简单-如果记录类型数量少
-
复杂-如果记录类型数量很多
-
平均-在简单和复杂之间。
外部接口文件
软件系统可能需要与某些外部软件共享其文件,或者可能需要将文件传递进行处理或作为某些函数的参数。所有这些文件都计为外部接口文件。
-
简单-如果共享文件中的记录类型数量很少
-
复杂-如果共享文件中的记录类型数量很多
-
平均-在简单和复杂之间。
外部查询
查询是输入和输出的组合,其中用户发送一些数据以作为输入进行查询,并且系统以已处理的查询输出响应用户。查询的复杂性不只是外部输入和外部输出。如果查询的输入和输出在格式和数据方面都是唯一的,则称查询为唯一。
-
简单-如果查询需要低处理量并产生少量输出数据
-
复杂-如果查询需要高处理量并产生大量输出数据
-
平均-在简单和复杂之间。
系统中的每个参数均根据其类别和复杂性给予权重。下表列出了每个参数的权重:
| Parameter | Simple | Average | Complex |
|---|---|---|---|
| Inputs | 3 | 4 | 6 |
| Outputs | 4 | 5 | 7 |
| Enquiry | 3 | 4 | 6 |
| Files | 7 | 10 | 15 |
| Interfaces | 5 | 7 | 10 |
上表产生原始功能点。这些函数点根据环境复杂性进行调整。系统使用14种不同的特征进行描述:
- 数据通讯
- 分布式处理
- 绩效目标
- 操作配置负荷
- 交易率
- 在线数据录入
- 最终用户效率
- 在线更新
- 复杂的处理逻辑
- 重用性
- 安装简便
- 操作简便
- 多个地点
- 渴望改变
然后将这些特征因子从0到5进行评级,如下所述:
- 没有影响
- 偶然的
- 中等
- 平均
- 重大
- 必要
然后将所有等级汇总为N。N的值范围为0到70(14种特征x 5种等级)。使用以下公式来计算复杂度调整因子(CAF):
CAF = 0.65 + 0.01N
然后,
Delivered Function Points (FP)= CAF x Raw FP
然后可以将此FP用于各种指标,例如:
费用= $ / FP
质量=错误/ FP
生产率= FP /人月