查找 R DataFrame 中的唯一行
在 R 数据框中,唯一行意味着该行中的任何元素都不会以相同的组合在整个数据框中复制。简单来说,如果我们有一个名为 df 的数据框,有四列五行,我们可以假设一行中的任何值都不会在其他行中复制。
如果我们的数据集合中有许多冗余行,我们可能需要查找某些类型的行。我们可以使用 dplyr 包的 group_by_all函数来实现这一点。它将对所有冗余行进行分组并返回唯一行及其计数。
示例 1:
R
library("dplyr")
df = data.frame(x = as.integer(c(1, 1, 2, 2, 3, 4, 4)),
y = as.integer(c(1, 1, 2, 2, 3, 4, 4)))
print("dataset is ")
print(df)
ans = df%>%group_by_all%>%count
print("unique rows with count are")
print(ans)R
library("dplyr")
df = data.frame(x = as.integer( c(10,10,20,20,30,40,40) ),
y = c("rahul", "rahul", "mohan","mohan", "rohit", "rohan", "rohan"))
print("dataset is ")
print(df)
ans = df%>%group_by_all%>%count
print("unique rows with count are")
print(ans)输出:

示例 2:
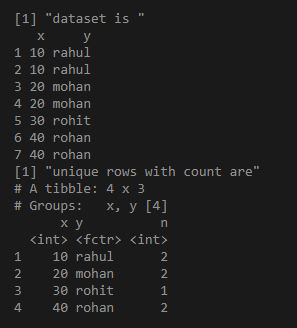
电阻
library("dplyr")
df = data.frame(x = as.integer( c(10,10,20,20,30,40,40) ),
y = c("rahul", "rahul", "mohan","mohan", "rohit", "rohan", "rohan"))
print("dataset is ")
print(df)
ans = df%>%group_by_all%>%count
print("unique rows with count are")
print(ans)
输出: