自动驾驶汽车卡尔曼滤波器概述
卡尔曼滤波器是一种最优估计算法。当我们由于精度或物理限制等不同的限制而处于怀疑状态时,它可以帮助我们预测/估计物体的位置,我们将在稍后讨论。
卡尔曼滤波器的应用:
卡尔曼滤波器用于以下情况 -
- 只能间接测量的感兴趣变量。
- 可以从各种传感器获得测量值,但可能会受到噪声的影响,即传感器融合。
让我们一一深入挖掘每种用途。
- 间接测量:
测量只能间接测量的感兴趣的变量(考虑中的变量)。这种类型的变量称为状态估计变量。让我们通过一个例子来理解它。
例子:
假设您想知道您的狗 Jacky 有多开心。因此,您感兴趣的变量 y 是 Jacky 的幸福。现在衡量 Jacky 幸福的唯一方法是间接衡量,因为幸福不是可以直接衡量的物理状态。你可以选择看杰基挥动他的尾巴并预测他是否快乐。你也可能有一个完全不同的方法来给你一个想法或估计杰基有多开心。这个独特的想法就是卡尔曼滤波器。这就是我说卡尔曼滤波器是一种最优估计算法时的意思。 - 传感器融合:
现在你对这个过滤器到底是什么有了直觉。卡尔曼滤波器结合测量和预测来找到汽车位置的最佳估计。
例子:
假设你有一辆遥控汽车,它以 1 m/s 的速度运行。假设 1 秒后您需要预测汽车的确切位置,您的预测是什么?
好吧,如果您知道一些基本的时间、距离和速度公式,您将能够正确地说出当前位置提前 1 米。但是这个模型有多准确?
理想情况下总会有一些变化,而这种偏差是导致错误的原因。现在为了最小化状态预测中的误差,采用传感器进行测量。传感器测量也有一些误差。所以现在我们有两个概率分布(传感器和预测,因为它们并不总是一个数字,而是概率分布函数(pdf)),它们应该告诉汽车的位置。一旦我们将这两条高斯曲线结合起来,我们就可以得到一个方差要小得多的全新高斯曲线。
例子:
假设您有一个朋友(传感器 2)擅长数学但在物理方面不太好,而您(传感器 1)擅长物理但数学不太好。现在在考试的那天,当你的目标取得好成绩时,你和你的朋友聚在一起,以便在两个科目上都表现出色。你们都合作以最小化错误并最大化结果(输出)。
例子:
这就像当你需要了解一个事件时,你向不同的人询问这件事,在听完他们所有的故事后,你自己编造一个,你似乎比任何一个单独的故事都准确得多。看到它总是与我们的日常生活有关,我们总是可以与我们已经经历过的事情联系起来。
代码:一维卡尔曼滤波器的Python实现
def update(mean1, var1, mean2, var2):
new_mean = float(var2 * mean1 + var1 * mean2) / (var1 + var2)
new_var = 1./(1./var1 + 1./var2)
return [new_mean, new_var]
def predict(mean1, var1, mean2, var2):
new_mean = mean1 + mean2
new_var = var1 + var2
return [new_mean, new_var]
measurements = [5., 6., 7., 9., 10.]
motion = [1., 1., 2., 1., 1.]
measurement_sig = 4.
motion_sig = 2.
mu = 0.
sig = 10000.
# print out ONLY the final values of the mean
although for a better understanding you may choose to
# and the variance in a list [mu, sig].
for measurement, motion in zip(measurements, motion):
mu, sig = update(measurement, measurement_sig, mu, sig)
mu, sig = predict(motion, motion_sig, mu, sig)
print([mu, sig])
解释:
正如我们所讨论的,整个过程有两个主要步骤,首先是更新步骤,然后是预测步骤。这两个步骤一遍又一遍地循环以估计机器人的确切位置。
预测步骤:
可以使用公式计算新位置 p'
其中 p 是前一个位置,v 是速度,dt 是时间步长。
新速度 v' 将与之前的速度相同,作为其常数(假设)。这在等式中可以给出为
现在把这个完整的东西写在一个矩阵中。
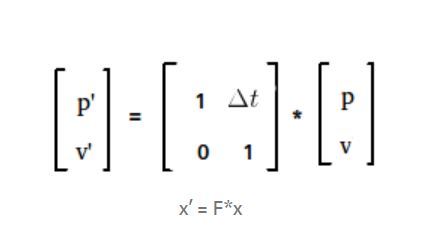
预测步骤
更新步骤:
您刚刚实现的过滤器是在Python中,也是在一维中。大多数情况下,我们处理的维度不止一个,而且语言也会发生变化。所以让我们在 C++ 中实现一个卡尔曼滤波器。
要求:
特征库
您将需要 Eigen 库,尤其是 Dense 类,以便使用该过程中所需的线性代数。下载库并将其粘贴到包含代码文件的文件夹中,以防您不知道库在 C++ 中是如何工作的。还请阅读官方文档以更好地了解如何使用其功能。我不得不承认他们在文档中解释的方式非常棒,而且比您要求的任何教程都要好。
现在使用我们发现的这个新武器(库)在 C++ 中实现相同的预测和更新函数,以处理过程中的代数部分。
预测步骤:
P' = F * P * F.transpose() + Q
这里Bu 变为零,因为它用于包含与摩擦或任何其他难以计算的力相关的变化。 v 是过程噪声,它决定了整个系统中可能存在的随机噪声。
void KalmanFilter::Predict()
{
x = F * x;
MatrixXd Ft = F.transpose();
P = F * P * Ft + Q;
}
这样,我们就能够计算出 X 的预测值和协方差矩阵 P。
更新步骤:
其中w表示传感器测量噪声。
所以对于激光雷达来说,测量函数是这样的:
它也可以用矩阵形式表示:

矩阵形式的表示
在这一步中,我们使用最新的测量值来更新我们的估计和我们的不确定性。
H是将状态映射到测量值的测量函数,并通过将测量值 (z)与我们的预测 (H*x)进行比较来帮助计算误差 (y )。
误差被映射到矩阵 S,该矩阵是通过使用字符测量噪声的测量函数(H) + 矩阵R将系统不确定性 (P)投影到测量空间中获得的。
然后将其映射到称为 K 的变量中。K是卡尔曼增益,并根据先前的数据及其不确定性决定是否需要给予所采取的测量更多的权重或预测。
然后最后我们使用卡尔曼增益使用这个方程更新我们的估计(x)和我们的不确定性(P) 。
x = x + (K * y)
P = (I – K * H) * P
这里I是一个单位矩阵。
void KalmanFilter::Update(const VectorXd& z)
{
VectorXd z_pred = H * x;
VectorXd y = z - z_pred;
MatrixXd Ht = H.transpose();
MatrixXd S = H * P * Ht + R;
MatrixXd Si = S.inverse();
MatrixXd PHt = P * Ht;
MatrixXd K = PHt * Si;
// new estimate
x = x + (K * y);
long x_size = x_.size();
MatrixXd I = MatrixXd::Identity(x_size, x_size);
P = (I - K * H) * P;
}
代码:
// create a 4D state vector, we don't know yet the values of the x state
x = VectorXd(4);
// state covariance matrix P
P = MatrixXd(4, 4);
P << 1, 0, 0, 0,
0, 1, 0, 0,
0, 0, 1000, 0,
0, 0, 0, 1000;
// measurement covariance
R = MatrixXd(2, 2);
R << 0.0225, 0,
0, 0.0225;
// measurement matrix
H = MatrixXd(2, 4);
H << 1, 0, 0, 0,
0, 1, 0, 0;
// the initial transition matrix F
F = MatrixXd(4, 4);
F << 1, 0, 1, 0,
0, 1, 0, 1,
0, 0, 1, 0,
0, 0, 0, 1;
// set the acceleration noise components
noise_ax = 5;
noise_ay = 5;
我一开始没有初始化矩阵的原因是这不是我们编写卡尔曼滤波器时的主要部分。首先,我们应该知道这两个主要函数是如何工作的。然后是初始化和其他东西。
一些缺点: