OpenCV 和 Keras |自动驾驶汽车交通标志分类
介绍
在本文中,我们将学习如何对我们在日常生活中偶尔遇到的一些常见交通标志进行分类。在制造自动驾驶汽车时,有必要确保它能够高度准确地识别交通标志,除非结果可能是灾难性的。在旅途中,您可能会遇到许多交通标志,如限速信号、左转或右转信号、停车信号等。对所有这些进行精确分类可能是一项艰巨的任务,而这正是本文将帮助您的地方。

您可以从此链接获取数据集——数据。它包含 4 个文件——
- signnames.csv - 它包含所有标签及其描述符。
- train.p - 它包含所有训练图像像素强度以及标签。
- valid.p - 它包含所有验证图像像素强度以及标签。
- test.p - 它包含所有测试图像像素强度以及标签。
上述扩展名为 .p 的文件称为 pickle 文件,用于将对象序列化为字符流。这些可以通过使用Python中的 pickle 库加载它们来反序列化和重用。
让我们以简单易懂的步骤使用 Keras 实现卷积神经网络 (CNN) 。 CNN 由神经网络中的一系列卷积和池化层组成,它们与输入映射以提取特征。卷积层将有许多过滤器,主要用于检测低级特征,例如面部边缘。池化层进行降维以减少计算量。此外,它还通过忽略侧面像素来提取主要特征。要阅读有关 CNN 的更多信息,请访问此链接。
导入库
我们将需要以下库。确保在实现以下代码之前安装NumPy 、 Pandas 、 Keras 、 Matplotlib和OpenCV 。
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.optimizers import Adam
from keras.utils.np_utils import to_categorical
from keras.preprocessing.image import ImageDataGenerator
import pickle
import pandas as pd
import random
import cv2
np.random.seed(0)
在这里,我们使用 numpy 进行数值计算,使用 pandas 导入和管理数据集,使用 Keras 使用更少的代码快速构建卷积神经网络,使用 cv2 进行一些预处理步骤,这些步骤对于 CNN 从图像中有效提取特征是必要的.加载数据集
是时候加载数据了。我们将使用 pandas 加载 signnames.csv,并使用 pickle 加载训练、验证和测试 pickle 文件。提取数据后,使用字典标签“特征”和“标签”对其进行拆分。
# Read data
data = pd.read_csv("german-traffic-signs / signnames.csv")
with open('german-traffic-signs / train.p', 'rb') as f:
train_data = pickle.load(f)
with open('german-traffic-signs / valid.p', 'rb') as f:
val_data = pickle.load(f)
with open('german-traffic-signs / test.p', 'rb') as f:
test_data = pickle.load(f)
# Extracting the labels from the dictionaries
X_train, y_train = train_data['features'], train_data['labels']
X_val, y_val = val_data['features'], val_data['labels']
X_test, y_test = test_data['features'], test_data['labels']
# Printing the shapes
print(X_train.shape)
print(X_val.shape)
print(X_test.shape)
输出:
(34799, 32, 32, 3)
(4410, 32, 32, 3)
(12630, 32, 32, 3)
使用 OpenCV 预处理数据
在输入模型之前对图像进行预处理可以提供非常准确的结果,因为它有助于提取图像的复杂特征。 OpenCV 有一些内置函数,如cvtColor()和equalizeHist()用于此任务。请按照以下步骤执行此任务 -
- 首先,使用cvtColor()函数将图像转换为灰度图像以减少计算量。
- equalizeHist()函数通过将像素与附近的像素进行归一化来均衡像素的强度,从而增加图像的对比度。
- 最后,我们通过将像素值除以 255 来标准化 0 和 1 之间的像素值。
def preprocessing(img):
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.equalizeHist(img)
img = img / 255
return img
X_train = np.array(list(map(preprocessing, X_train)))
X_val = np.array(list(map(preprocessing, X_val)))
X_test = np.array(list(map(preprocessing, X_test)))
X_train = X_train.reshape(34799, 32, 32, 1)
X_val = X_val.reshape(4410, 32, 32, 1)
X_test = X_test.reshape(12630, 32, 32, 1)
在对数组进行整形后,是时候将它们输入模型进行训练了。但是为了提高我们的 CNN 模型的准确性,我们将涉及使用 ImageDataGenerator 生成增强图像的另一步骤。
这样做是为了减少过度拟合训练数据,因为获得更多不同的数据将产生更好的模型。值 0.1 被解释为 10%,而 10 是旋转度数。我们还像往常一样将标签转换为分类值。
datagen = ImageDataGenerator(width_shift_range = 0.1,
height_shift_range = 0.1,
zoom_range = 0.2,
shear_range = 0.1,
rotation_range = 10)
datagen.fit(X_train)
y_train = to_categorical(y_train, 43)
y_val = to_categorical(y_val, 43)
y_test = to_categorical(y_test, 43)
构建模型
由于数据集中有 43 类图像,我们将 num_classes 设置为 43。该模型包含两个 Conv2D 层和一个 MaxPooling2D 层。为了有效提取特征,这样做了两次,然后是密集层。添加了 0.5 的 dropout 层以避免过度拟合数据。
num_classes = 43
def cnn_model():
model = Sequential()
model.add(Conv2D(60, (5, 5),
input_shape =(32, 32, 1),
activation ='relu'))
model.add(Conv2D(60, (5, 5), activation ='relu'))
model.add(MaxPooling2D(pool_size =(2, 2)))
model.add(Conv2D(30, (3, 3), activation ='relu'))
model.add(Conv2D(30, (3, 3), activation ='relu'))
model.add(MaxPooling2D(pool_size =(2, 2)))
model.add(Flatten())
model.add(Dense(500, activation ='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation ='softmax'))
# Compile model
model.compile(Adam(lr = 0.001),
loss ='categorical_crossentropy',
metrics =['accuracy'])
return model
model = cnn_model()
history = model.fit_generator(datagen.flow(X_train, y_train,
batch_size = 50), steps_per_epoch = 2000,
epochs = 10, validation_data =(X_val, y_val),
shuffle = 1)
Output:
Epoch 1/10
2000/2000 [==============================] - 129s 65ms/step - loss: 0.9130 - acc: 0.7322 - val_loss: 0.0984 - val_acc: 0.9669
Epoch 2/10
2000/2000 [==============================] - 119s 60ms/step - loss: 0.2084 - acc: 0.9352 - val_loss: 0.0609 - val_acc: 0.9803
Epoch 3/10
2000/2000 [==============================] - 116s 58ms/step - loss: 0.1399 - acc: 0.9562 - val_loss: 0.0409 - val_acc: 0.9878
Epoch 4/10
2000/2000 [==============================] - 115s 58ms/step - loss: 0.1066 - acc: 0.9672 - val_loss: 0.0262 - val_acc: 0.9925
Epoch 5/10
2000/2000 [==============================] - 116s 58ms/step - loss: 0.0890 - acc: 0.9726 - val_loss: 0.0268 - val_acc: 0.9925
Epoch 6/10
2000/2000 [==============================] - 115s 58ms/step - loss: 0.0777 - acc: 0.9756 - val_loss: 0.0237 - val_acc: 0.9927
Epoch 7/10
2000/2000 [==============================] - 132s 66ms/step - loss: 0.0700 - acc: 0.9779 - val_loss: 0.0327 - val_acc: 0.9900
Epoch 8/10
2000/2000 [==============================] - 122s 61ms/step - loss: 0.0618 - acc: 0.9812 - val_loss: 0.0267 - val_acc: 0.9914
Epoch 9/10
2000/2000 [==============================] - 115s 57ms/step - loss: 0.0565 - acc: 0.9830 - val_loss: 0.0146 - val_acc: 0.9957
Epoch 10/10
2000/2000 [==============================] - 120s 60ms/step - loss: 0.0577 - acc: 0.9828 - val_loss: 0.0222 - val_acc: 0.9939
在成功编译模型并拟合训练和验证数据后,让我们使用 Matplotlib 对其进行评估。评估和测试
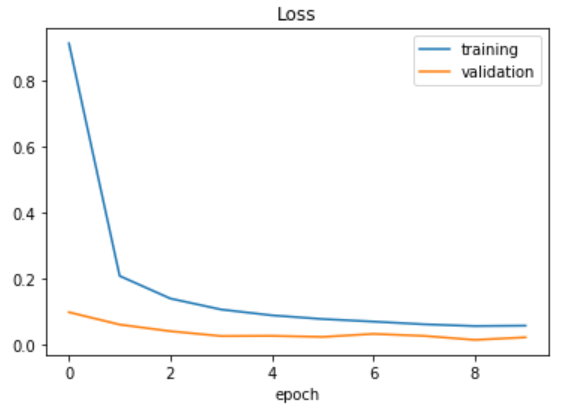
绘制损失函数。
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.legend(['training', 'validation'])
plt.title('Loss')
plt.xlabel('epoch')
输出:
绘制精度函数。
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.legend(['training', 'validation'])
plt.title('Accuracy')
plt.xlabel('epoch')
输出:
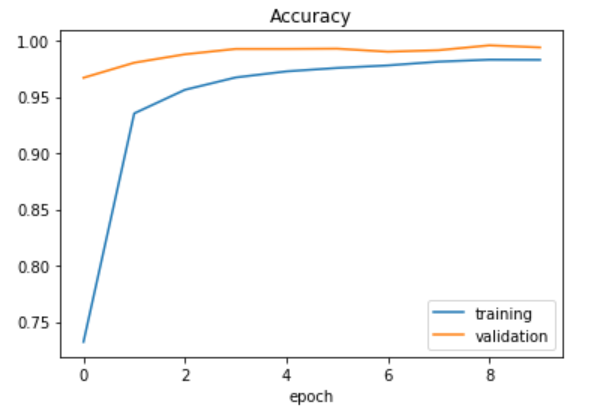
如您所见,我们已经很好地拟合了数据,将训练和验证损失都保持在最低限度。是时候评估我们的模型在测试数据上的表现了。
score = model.evaluate(X_test, y_test, verbose = 0)
print('Test Loss: ', score[0])
print('Test Accuracy: ', score[1])
输出:
Test Loss: 0.16352852963907774
Test Accuracy: 0.9701504354899777
让我们通过将一张测试图像输入模型来检查它。该模型给出了 0 级(限速 20)的预测,这是正确的。
plt.imshow(X_test[990].reshape(32, 32))
print("Predicted sign: "+ str(
model.predict_classes(X_test[990].reshape(1, 32, 32, 1))))
输出:预测符号:[0] 