Python BeautifulSoup - 查找所有类
先决条件:-请求,BeautifulSoup
任务是编写一个程序来查找给定网站 URL 的所有类。在 Beautiful Soup 中,没有找到所有类的内置方法。
需要的模块:
- bs4 : Beautiful Soup(bs4) 是一个Python库,用于从 HTML 和 XML 文件中提取数据。这个模块没有内置于Python中。要安装此类型,请在终端中输入以下命令。
pip install bs4
- requests : Requests 允许您非常轻松地发送 HTTP/1.1 请求。这个模块也没有内置于Python中。要安装此类型,请在终端中输入以下命令。
pip install requests
方法#1:在给定的 HTML 文档中查找类。
方法:
- 创建一个 HTML 文档。
- 导入模块。
- 将内容解析为 BeautifulSoup。
- 按类名迭代数据。
代码:
Python3
# html code
html_doc = """Welcome to geeksforgeeks
Geeks
geeksforgeeks a computer science portal for geeks
"""
# import module
from bs4 import BeautifulSoup
# parse html content
soup = BeautifulSoup( html_doc , 'html.parser')
# Finding by class name
soup.find( class_ = "body" )
Python3
# Import Module
from bs4 import BeautifulSoup
import requests
# Website URL
URL = 'https://www.geeksforgeeks.org/'
# class list set
class_list = set()
# Page content from Website URL
page = requests.get( URL )
# parse html content
soup = BeautifulSoup( page.content , 'html.parser')
# get all tags
tags = {tag.name for tag in soup.find_all()}
# iterate all tags
for tag in tags:
# find all element of tag
for i in soup.find_all( tag ):
# if tag has attribute of class
if i.has_attr( "class" ):
if len( i['class'] ) != 0:
class_list.add(" ".join( i['class']))
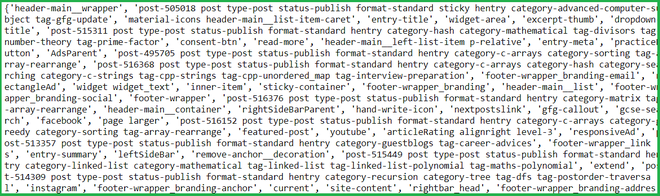
print( class_list )输出:
geeksforgeeks a computer science portal for geeks
方法#2:下面是在一个 URL 中查找所有类的程序。
方法:
- 导入模块
- 制作请求实例并传入 URL
- 将请求传递给 Beautifulsoup()函数
- 然后我们将迭代所有标签并获取类名
代码:
蟒蛇3
# Import Module
from bs4 import BeautifulSoup
import requests
# Website URL
URL = 'https://www.geeksforgeeks.org/'
# class list set
class_list = set()
# Page content from Website URL
page = requests.get( URL )
# parse html content
soup = BeautifulSoup( page.content , 'html.parser')
# get all tags
tags = {tag.name for tag in soup.find_all()}
# iterate all tags
for tag in tags:
# find all element of tag
for i in soup.find_all( tag ):
# if tag has attribute of class
if i.has_attr( "class" ):
if len( i['class'] ) != 0:
class_list.add(" ".join( i['class']))
print( class_list )
输出: