节点 |使用 Cheerio 进行网络爬取
通过向特定 URL 发送 HTTP 请求,然后提取该网页的 HTML 以获取有用信息,这称为爬网或网络抓取。
在 Nodejs 中用于爬取的模块:
- request:用于向 URL 发送 HTTP 请求
- Cheerio:用于解析 DOM 并提取网页的 HTML
- fs:用于读取或写入数据到文件中
这些模块的安装:
在 Nodejs 中安装模块的最简单方法是使用 NPM。
它可以通过两种方式完成:
- 全局安装:如果我们全局安装任何模块,那么我们可以在系统的任何地方使用它。
可以通过以下命令完成:npm i -g package_name - 本地安装:如果我们在本地安装任何模块,那么我们只能在该特定项目目录中使用它。
可以通过以下命令完成:npm i package_name
对于此任务,我们将使用本地安装:
使用 Cheerio 进行网络爬取的步骤:
- 第一步:为这个项目创建一个文件夹
- 步骤 2:打开项目目录中的终端,然后键入以下命令:
npm init它将创建一个名为
package.json其中包含有关模块、作者、github 存储库及其版本的所有信息。
要了解有关package.json的更多信息,请访问此链接:
package.json 的解释要使用 NPM 在本地安装模块,只需执行以下操作:
npm install request npm install cheerio npm install fs这也可以使用 NPM 在单行中完成:
npm install request cheerio fs成功安装模块后,我们的 package.json 将具有如下结构:

在此屏幕截图中,我们可以看到所有依赖项都已在依赖项对象中列出,这意味着我们已成功将所有依赖项安装在当前项目目录中。
- 第 3 步:现在我们将为爬虫编写代码
编码步骤:
- 首先,我们将导入所有需要的模块
- 然后,我们将向 URL 发送一个 HTTP 请求,然后所需网站的服务器将响应一个网页,这将通过请求模块完成
- 现在,我们有了网页的 HTML,我们的任务是从中提取有用的信息,所以我们将遍历 DOM 树并找出选择器
- 提取信息后,我们将其保存到文件中,此任务将在fs模块的帮助下完成
- 爬虫代码:
- 创建一个名为server.js的文件并添加以下行:
const request = require('request'); const cheerio = require('cheerio'); const mongoose = require('fs');这些代码行的解释:
在这三行中,我们将抓取和数据保存所需的所有这三个模块导入文件中。 - 我们将点击我们想要抓取数据的 URL:
在这里,我们将从电子商务网站 Flipkart 抓取智能手机列表。在 Flipkart 中显示智能手机列表的 URL 如下:
const URL = "https://www.flipkart.com/search?q=mobiles";在这个 URL 网页上看起来像这样:

现在我们将在
request模块:
request(URL, function (err, res, body) { if(err) { console.log(err, "error occured while hitting URL"); } else { console.log(body); } });让我们理解这些代码:
这里我们使用request模块向flipkart的智能手机URL发送HTTP请求,request模块内的函数分别接受三个参数error、response、body。
在这里,如果出现错误,那么我们记录它,否则我们记录正文。为了测试它,我们何时运行我们的脚本
node server.js我们可以在控制台中看到页面的整个 HTML。
它是此 URL 的网页的完整 HTML。现在我们的任务是提取有用的信息,因此我们将访问 DOM 树并通过检查元素找出选择器。
为此,请右键单击网页并转到类似的检查元素:
现在我们将访问 DOM:
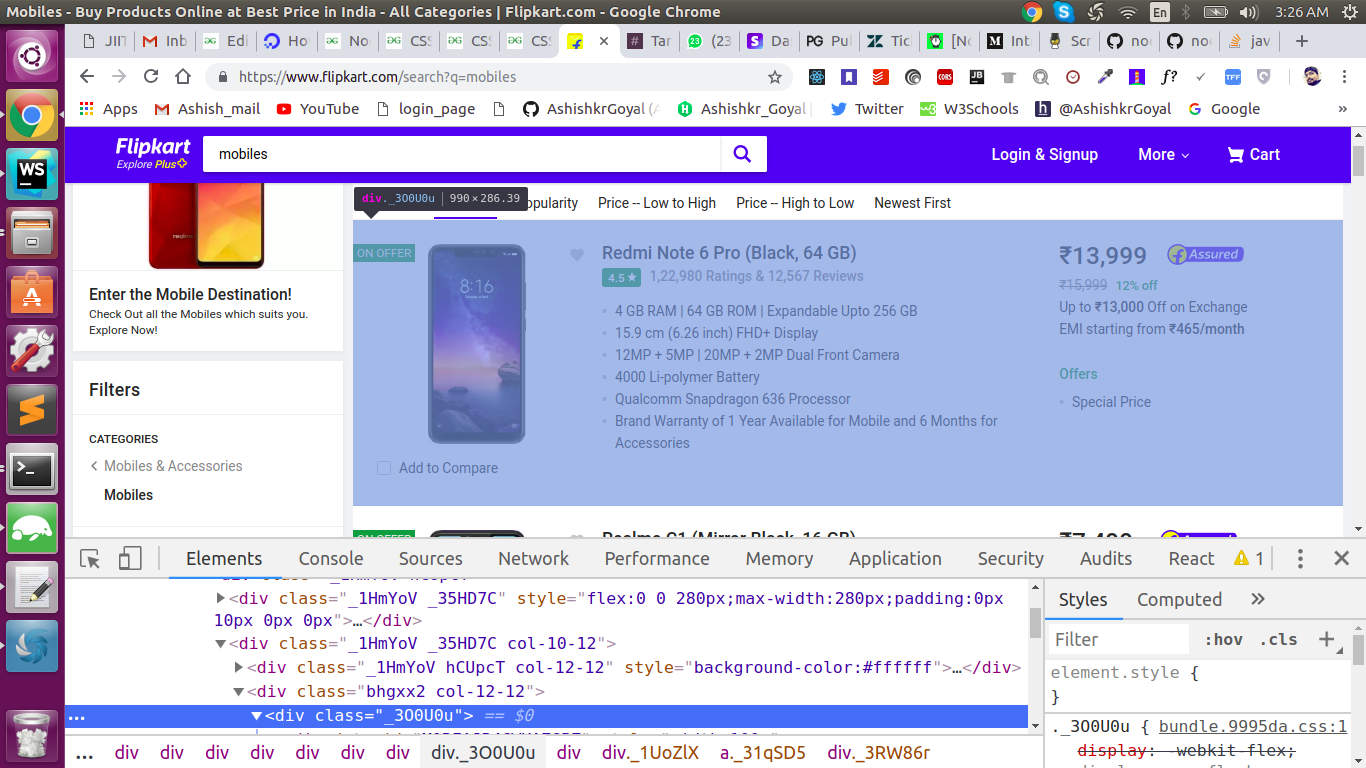
现在我们将根据检查更改我们的请求以点击 URL:
request(URL, function (err, res, body) { if(err) { console.log(err); } else { let $ = cheerio.load(body); //loading of complete HTML body $('div._1HmYoV > div.col-10-12>div.bhgxx2>div._3O0U0u').each(function(index){ const link = $(this).find('div._1UoZlX>a').attr('href'); const name = $(this).find('div._1-2Iqu>div.col-7-12>div._3wU53n').text(); console.log(link); //link for smartphone console.log(name); //name of smartphone }); } }); - 将数据保存到文件中
为此,我们将创建一个数组和一个对象let arr = []; //creating an array let object = { link : link, name : name, } //creating an object fs.writeFile('data.txt', arr, function (err) { if(err) { console.log(err); } else{ console.log("success"); } });在每次迭代中,我们会将对象转换为字符串后将其推送到数组中;
最后我们将整个数组写入文件。通过这种方法我们的完整数据将成功保存在文件中!现在我们的整个代码都会喜欢它:
// Write Javascript code here const request = require('request'); const cheerio = require('cheerio'); const fs = require('fs'); const URL = "https://www.flipkart.com/search?q=mobiles"; request(URL, function (err, res, body) { if(err) { console.log(err); } else { const arr = []; let $ = cheerio.load(body); $('div._1HmYoV > div.col-10-12>div.bhgxx2>div._3O0U0u').each(function(index){ const data = $(this).find('div._1UoZlX>a').attr('href'); const name = $(this).find('div._1-2Iqu>div.col-7-12>div._3wU53n').text(); const obj = { data : data, name : name }; console.log(obj); arr.push(JSON.stringify(obj)); }); console.log(arr.toString()); fs.writeFile('data.txt', arr, function (err) { if(err) { console.log(err); } else{ console.log("success"); } }); } });
现在运行代码:
node server.js运行代码时,您可以在终端上看到这样的输出:
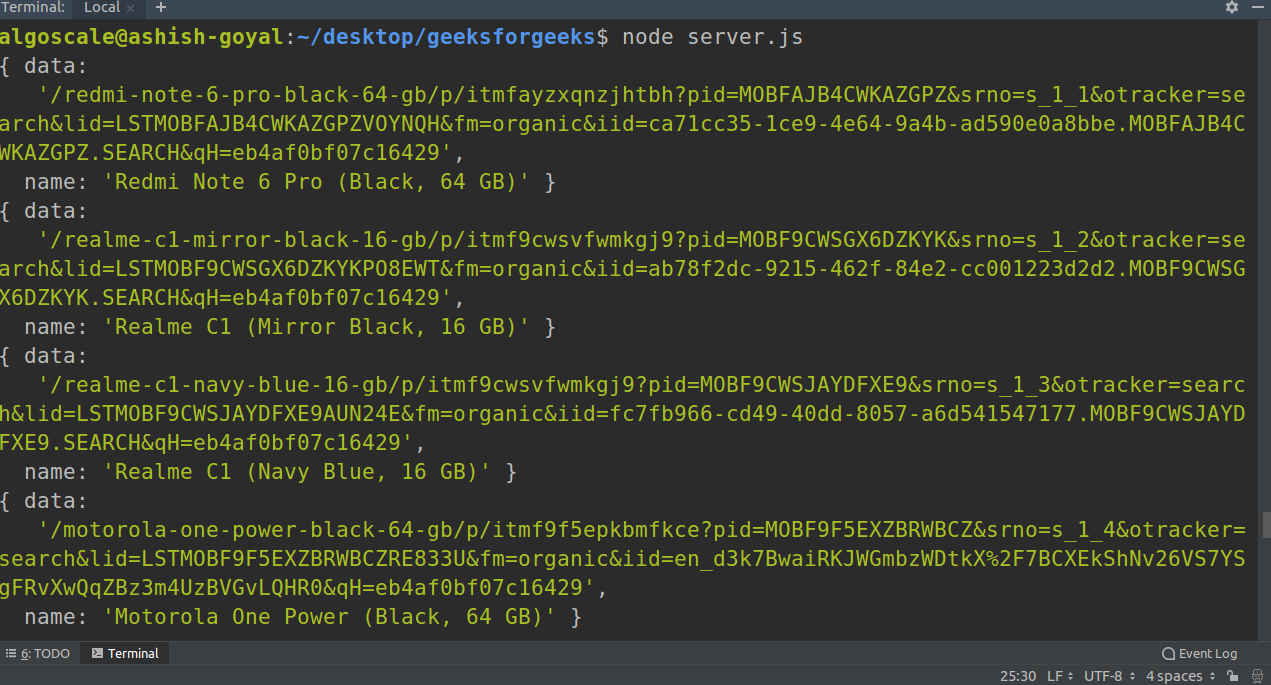
成功运行代码后,还有一个名为 data.txt 的文件,其中包含所有提取的数据!我们可以在我们的项目目录中找到这个文件。
因此,这是一个简单的示例,说明如何使用 Cheerio 模块在 nodejs 中创建网络爬虫。从这里,您可以尝试废弃您选择的任何其他网站。如有任何疑问,请在评论部分下方发布。