Pandas GroupBy – Unstack
Pandas Unstack是一个在堆叠数据框中旋转索引列级别的函数。堆叠的数据框通常是 pandas 中聚合的 groupby函数的结果。 Stack() 将列设置为新的层次结构级别,而 Unstack() 旋转索引列。有不同的方法可以解开 pandas 数据帧,这些方法将在下面的方法中讨论。
方法 1:使用 unstack() 对 pandas 数据帧进行多层次的常规解栈
数据帧上的 Groupby 聚合通常返回一个堆叠的数据帧对象,根据聚合模型的不同,它具有多级。
Python3
# import the python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({"cars": ["bmw", "bmw", "benz", "benz"],
"sale_q1 in Cr": [20, 22, 24, 26],
'sale_q2 in Cr': [11, 13, 15, 17]},
columns=["cars", "sale_q1 in Cr",
'sale_q2 in Cr'])
print(data)
# stack the data using stack() function
stacked_data = data.stack()
print(stacked_data)
# unstack the dataframe by first level
stack_level_1 = stacked_data.unstack(level=0)
print(stack_level_1)
# unstack the dataframe by second level
stack_level_2 = stacked_data.unstack(level=1)
print(stack_level_2)Python3
# import the python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({"cars": ["bmw", "bmw", "benz", "benz"],
"sale_q1 in Cr": [20, 22, 24, 26],
'sale_q2 in Cr': [11, 13, 15, 17]},
columns=["cars", "sale_q1 in Cr",
'sale_q2 in Cr'])
print(data)
# aggregate the car sales data by sum min
# and max sales of two quarters as shown
grouped_data = data.groupby('cars').agg(
{"sale_q1 in Cr": [sum, max],
"sale_q2 in Cr": [sum, min]})
print(grouped_data)
# general way of unstacking the grouped dataframe
gen_unstack = grouped_data.unstack()
print(gen_unstack)
# stacking the grouped dataframe at
# different levels and unstacking
# unstacking the stacked dataframe at level = 0
unstack_level1 = grouped_data.stack(level=0).unstack()
print(unstack_level1)
# unstacking the stacked dataframe at level =1
unstack_level2 = grouped_data.stack(level=1).unstack()
print(unstack_level2)Python3
# import the python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({"cars": ["bmw", "bmw", "benz", "benz"],
"sale_q1 in Cr": [20, 22, 24, 26],
'sale_q2 in Cr': [11, 13, 15, 17]},
columns=["cars", "sale_q1 in Cr",
'sale_q2 in Cr'])
print(data)
# aggregate the car sales data by sum min and
# max sales of two quarters as shown
grouped_data = data.groupby('cars').agg(
{"sale_q1 in Cr": [sum, max], "sale_q2 in Cr": [sum, min]})
print(grouped_data)
# stacking the grouped dataframe at
# different levels and unstacking
# unstacking the stacked dataframe at level = 0
unstack_level1 = grouped_data.stack(level=0).unstack()
print(unstack_level1)
# unstacking the stacked dataframe at level =1
unstack_level2 = grouped_data.stack(level=1).unstack()
print(unstack_level2)输出:
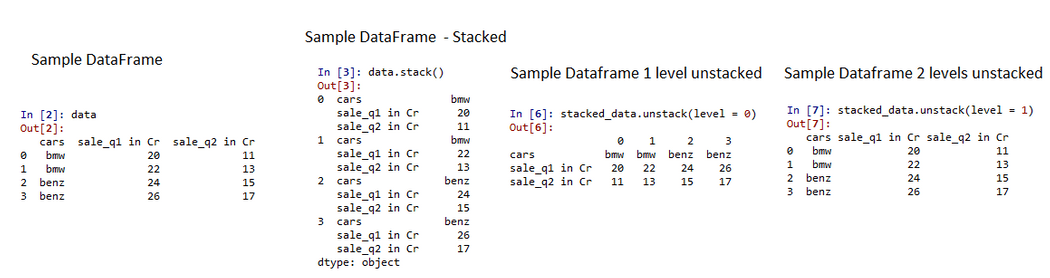
代码说明:
- 创建一个示例数据框,显示两个季度的汽车销量。
- 现在,使用 stack()函数堆叠数据帧,这会将列堆叠到行值。
- 由于我们在拆垛时有两列,因此将其视为两个不同的级别。
- 现在,分别使用级别 0 和级别 1 的 unstack函数将数据帧堆叠在两个不同的级别。
- 堆叠第一层或第二层取决于用例。
方法 2:使用简单的 unstack() 对 pandas 数据帧进行 GroupBy 解栈
每当我们在 pandas 数据帧上使用 groupby函数时,每列有多个聚合函数,输出通常是一个多索引列,其中第一个索引指定列名,第二个列索引指定聚合函数名。
Python3
# import the python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({"cars": ["bmw", "bmw", "benz", "benz"],
"sale_q1 in Cr": [20, 22, 24, 26],
'sale_q2 in Cr': [11, 13, 15, 17]},
columns=["cars", "sale_q1 in Cr",
'sale_q2 in Cr'])
print(data)
# aggregate the car sales data by sum min
# and max sales of two quarters as shown
grouped_data = data.groupby('cars').agg(
{"sale_q1 in Cr": [sum, max],
"sale_q2 in Cr": [sum, min]})
print(grouped_data)
# general way of unstacking the grouped dataframe
gen_unstack = grouped_data.unstack()
print(gen_unstack)
# stacking the grouped dataframe at
# different levels and unstacking
# unstacking the stacked dataframe at level = 0
unstack_level1 = grouped_data.stack(level=0).unstack()
print(unstack_level1)
# unstacking the stacked dataframe at level =1
unstack_level2 = grouped_data.stack(level=1).unstack()
print(unstack_level2)
输出:

代码说明:
- 创建一个示例数据框,显示两个季度的汽车销量。
- 使用 GroupBy函数将汽车销售数据按两个季度的总和最小和最大销售额分组,如图所示
- 由于我们在取消堆叠时有两列,因此它将被视为两个索引处的两个不同级别。第一个索引将具有列名,第二个索引将具有聚合函数的名称。
- 现在,对分组的数据帧执行一个简单的 unstack 操作。这个简单的 unstack 会将列转换为行,反之亦然,如输出所示
方法 3:GroupBy 在两个不同级别使用多个 unstack() 对 pandas 数据帧进行分组。
通常,为了更深入地了解 GroupBy函数产生的见解,它通常堆叠在分组数据帧的不同级别。这个分组的数据帧可以通过使用 unstack()函数在不同级别上拆开来进一步研究。下面给出实际的实现。
Python3
# import the python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({"cars": ["bmw", "bmw", "benz", "benz"],
"sale_q1 in Cr": [20, 22, 24, 26],
'sale_q2 in Cr': [11, 13, 15, 17]},
columns=["cars", "sale_q1 in Cr",
'sale_q2 in Cr'])
print(data)
# aggregate the car sales data by sum min and
# max sales of two quarters as shown
grouped_data = data.groupby('cars').agg(
{"sale_q1 in Cr": [sum, max], "sale_q2 in Cr": [sum, min]})
print(grouped_data)
# stacking the grouped dataframe at
# different levels and unstacking
# unstacking the stacked dataframe at level = 0
unstack_level1 = grouped_data.stack(level=0).unstack()
print(unstack_level1)
# unstacking the stacked dataframe at level =1
unstack_level2 = grouped_data.stack(level=1).unstack()
print(unstack_level2)
输出:

代码说明:
- 创建一个示例数据框,显示两个季度的汽车销量。
- 使用 GroupBy函数将汽车销售数据按两个季度的总和最小和最大销售额分组,如图所示
- 由于我们在取消堆叠时有两列,因此它将被视为两个索引处的两个不同级别。第一个索引将具有列名,第二个索引将具有聚合函数的名称。
- 现在,在分组数据帧的第 0 级使用 stack() 并 unstack() 分组数据帧。
- 然后,在分组数据帧的级别 1 使用 stack() 并 unstack() 分组数据帧。
- 在第一级或第二级取消堆叠数据帧取决于用例。