- 数据挖掘中的文本挖掘(1)
- 数据挖掘中的文本挖掘
- 数据挖掘和文本挖掘的区别
- 数据挖掘和文本挖掘的区别(1)
- 数据挖掘和文本挖掘的区别(1)
- 数据挖掘和文本挖掘的区别
- 数据挖掘和网络挖掘的区别(1)
- 数据挖掘和网络挖掘的区别
- 数据挖掘和网络挖掘的区别
- 文本数据挖掘(1)
- 文本数据挖掘
- 挖掘 (1)
- 数据挖掘与大数据
- 数据挖掘与大数据(1)
- 数据挖掘-挖掘万维网
- 数据挖掘-挖掘万维网(1)
- 挖掘集体异常值数据挖掘
- 挖掘集体异常值数据挖掘(1)
- 大数据与数据挖掘的区别
- 大数据与数据挖掘的区别(1)
- 大数据与数据挖掘的区别
- 大数据与数据挖掘的区别(1)
- 挖掘 - 任何代码示例
- Linux挖掘(1)
- Linux挖掘
- 数据挖掘中的数据转换
- 网络挖掘
- 网络挖掘 (1)
- 数据挖掘 | 2套
📅 最后修改于: 2021-01-11 06:32:36 🧑 作者: Mango
文本数据库包含大量文档。他们从新闻,书籍,数字图书馆,电子邮件,网页等多种来源收集这些信息。由于信息量的增加,文本数据库正在迅速发展。在许多文本数据库中,数据都是半结构化的。
例如,文档可能包含一些结构化字段,例如标题,作者,publishing_date等。但是除了结构数据外,文档还包含非结构化文本组件,例如摘要和内容。不知道文档中可能包含什么内容,很难制定有效的查询来分析和从数据中提取有用的信息。用户需要使用工具来比较文档并对其重要性和相关性进行排名。因此,文本挖掘已成为流行并且成为数据挖掘中必不可少的主题。
信息检索
信息检索涉及从大量基于文本的文档中检索信息。某些数据库系统通常不存在于信息检索系统中,因为它们都处理不同种类的数据。信息检索系统的例子包括:
- 在线图书馆目录系统
- 在线文件管理系统
- 网络搜索系统等
注–信息检索系统中的主要问题是根据用户的查询在文档集中定位相关文档。这种用户查询由一些描述信息需求的关键字组成。
在此类搜索问题中,用户会主动从集合中提取相关信息。当用户有临时信息需求(即短期需求)时,这是适当的。但是,如果用户有长期的信息需求,则检索系统还可以主动将任何新到达的信息项推送给用户。
这种对信息的访问称为信息过滤。相应的系统称为过滤系统或推荐系统。
文本检索的基本措施
当系统根据用户输入检索许多文档时,我们需要检查系统的准确性。让与查询相关的文档集表示为{Relevant},将检索到的文档集表示为{Retrieved}。相关和检索的文档集可以表示为{相关}∩{检索}。这可以以维恩图的形式显示如下-
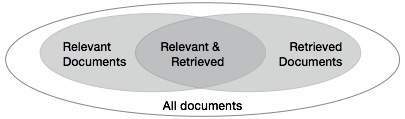
评估文本检索质量的三项基本措施-
- 精确
- 召回
- F分数
精确
精度是实际上与查询相关的已检索文档的百分比。精度可以定义为-
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|
召回
召回率是与查询相关且实际上已检索到的文档的百分比。召回定义为-
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|
F分数
F分数是常用的折衷方案。信息检索系统通常需要权衡取舍,反之亦然。 F分数定义为召回率或精度的谐波平均值,如下所示:
F-score = recall x precision / (recall + precision) / 2