计算机化或数字化信息的快速增长催生了大量的信息和数据。可用信息的很大一部分存储在文本数据库中,该数据库由来自各种来源的大量文档组成。由于电子形式的可用信息量不断增加,文本数据库正在迅速增长。目前超过80%的信息是非结构化或半组织化数据的形式。传统的信息检索技术对于日益海量的文本数据已经变得不够用了。因此,文本挖掘已成为数据挖掘中越来越流行和必不可少的部分。从大量数据中发现适当的模式并分析文本文档是现实世界应用领域的一个主要问题。
“Extraction of interesting information or patterns from data in large databases is known as data mining.”
文本挖掘是从大量文本数据库中提取有用信息和重要模式的过程。存在各种策略和设备来挖掘文本并为预测和决策过程找到重要数据。选择正确和准确的文本挖掘程序也有助于提高速度和时间复杂度。本文简要讨论和分析文本挖掘及其在各个领域的应用。
“Text Mining is the procedure of synthesizing information, by analyzing relations, patterns, and rules among textual data.”
正如我们上面所讨论的,信息的大小正在以指数速度扩大。今天,所有机构、公司、不同的组织和商业企业都以电子方式存储他们的信息。互联网上提供的大量数据集合,存储在数字图书馆、数据库存储库和其他文本数据(如网站、博客、社交媒体网络和电子邮件)中。确定适当的模式和趋势以从大量数据中提取知识是一项艰巨的任务。文本挖掘是数据挖掘的一部分,用于从文本数据库存储库中提取有价值的文本信息。文本挖掘是一个基于数据恢复、数据挖掘、人工智能、统计学、机器学习和计算语言学的多学科领域。
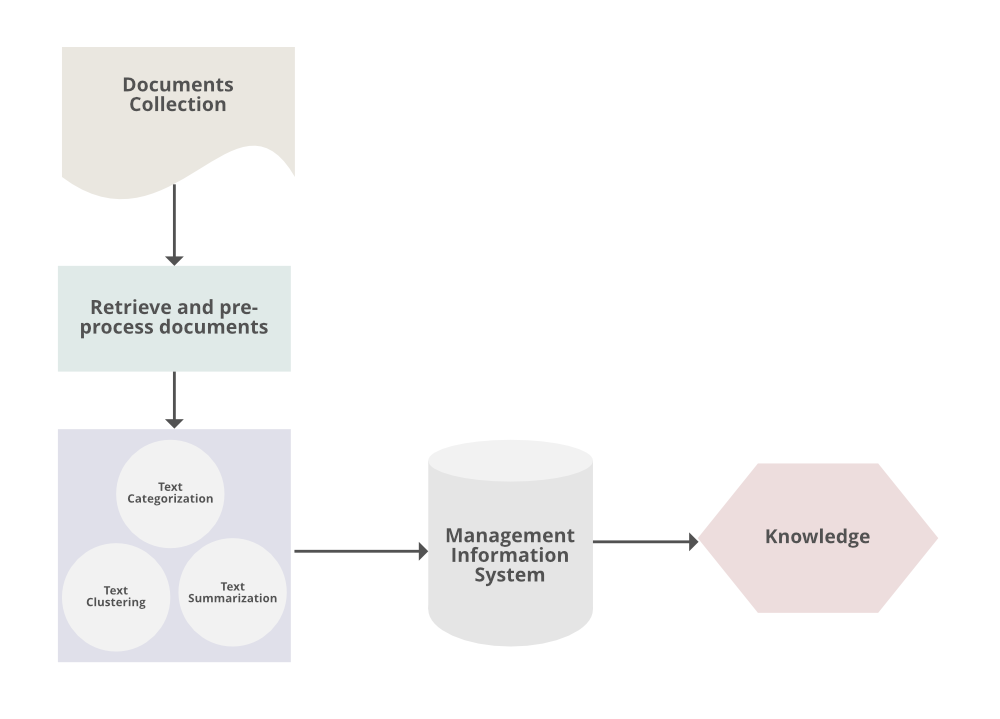
文本挖掘的常规流程如下:
- 从各种文档组织中可访问的各种来源收集非结构化信息,例如纯文本、网页、PDF 记录等。
- 执行预处理和数据清理任务以区分和消除数据的不一致。数据清洗过程确保捕获真正的文本,并执行它以消除停用词词干(识别某个词的词根并索引数据的过程)。
- 应用处理和控制任务来审查和进一步清理数据集。
- 模式分析在管理信息系统中实现。
- 利用上述步骤处理的信息提取重要和适用的数据,以进行强大而方便的决策过程和趋势分析。

分析文本挖掘的过程:
- 文本摘要:自动提取其部分内容反映其全部内容。
- 文本分类:在用户预定义的类别中为文本分配一个类别。
- 文本聚类:根据实质性相关性将文本分割成几个聚类。
文本挖掘技术:
- 信息抽取:从文档中抽取有意义的词的过程。
- 信息检索:是根据给定的一组词或文本文档提取相关和关联模式的过程。
- 自然语言处理:它涉及非结构化文本信息的自动处理和分析。
- 聚类:根据文本的相似特征对文本进行分组的无监督学习过程。
- 文本摘要:自动提取其部分内容反映它的全部内容。
文本挖掘技术概述
|
Text Mining Process Phase |
Algorithm |
Selected Question |
Motive |
Techniques |
|
|---|---|---|---|---|---|
| 1. Text Preprocessing phase | Tokenization | How can transform a text into words or text format? | Transferring strings into a single textual token. | White space separation. | |
| Compound word identification | How can I identify words that have a joint meaning? | Identifying words with a joint meaning that gets lost word | n-grms | ||
| Normalization and noise reduction | How can I cope with too many variables in my Document‐Term‐Matrix? | Reducing the dimensionality of Document‐Term‐Matrix | Stemming, Lemmatization, Deletion of stop words. infrequent term. | ||
| Linguistic analysis | How can I identify words with a special meaning or grammatical function? | Tagging of words | Named‐entity recognition, Part‐of‐speech tagging | ||
| 2.Content Analysis | Dictionary‐based | How can I identify how latent sociological or psychological traits and states are reflected in natural language? | Measuring contextual, psychological, linguistic, or semantic concepts and constructs |
pre‐defined dictionaries Customized dictionaries |
|
| Algorithmic techniques | How can I assign texts to predefined classes? | Classifying of textual entities into predefined categories | Supervised learning techniques such as binary or multi‐class classifiers | ||
| How can I group together similar documents? | Clustering of textual entities into formerly undefined and unknown | Unsupervised learning techniques such as LDA, k‐means or non‐negative |
文本挖掘的应用领域
1. 数字图书馆
正在使用各种文本挖掘策略和工具从存储在文本数据库存储库中的期刊和会议录中获取模式和趋势。这些信息资源有助于研究领域的领域。图书馆是数字形式的文本数据的良好资源。它提供了一种获取有用数据的新技术,使得在线访问数百万条记录成为可能。支持多种语言和多语言界面的绿色国际数字图书馆提供了一种灵活的方法来提取处理各种格式的报告,例如 Microsoft Word、PDF、postscript、HTML、脚本语言和电子邮件。它还支持提取视听和图像格式以及文本文档。文本挖掘过程执行不同的活动,如文档收集、确定、增强、删除数据和处理物质,以及生成摘要。有不同类型的数字图书馆文本挖掘工具,即:用于文本挖掘的 GATE、Net Owl 和 Aylien。
2. 学术研究领域
在教育领域,使用不同的文本挖掘工具和策略来检查特定区域/研究领域的教学模式。研究领域文本挖掘利用的主要目的是帮助在一个平台上发现和整理各个领域的研究论文和相关资料。为此,我们使用 k-Means 聚类,不同的策略有助于区分重要数据的属性。此外,可以访问学生在各个科目的表现,以及各种素质如何影响通过此挖掘评估的科目的选择。
3. 生命科学
生命科学和医疗保健行业正在产生大量关于患者记录、疾病、药物、症状和疾病治疗等的文本和数学数据。过滤数据和相关文本以根据生物学做出决策是一个主要问题。数据存储库。临床记录包含不可预测的、冗长的可变数据。文本挖掘有助于管理此类数据。文本挖掘在生物标志物披露、制药行业、临床贸易分析检查、临床研究、专利竞争情报中的应用。
4. 社交媒体
文本挖掘可用于剖析基于网络的媒体应用程序,以监控和调查在线内容,如来自互联网新闻、网络期刊、电子邮件、博客等的纯文本。文本挖掘设备有助于区分和调查帖子、喜欢和网络媒体网络上的追随者。这种分析显示了个人对各种帖子、新闻及其传播方式的反应。它显示了属于特定年龄组的人的行为以及对同一帖子的喜欢和浏览量的变化。
5. 商业智能
文本挖掘在商业智能中扮演着重要的角色,它帮助不同的组织和企业分析他们的客户和竞争对手以做出更好的决策。它提供了对业务的准确理解,并提供了有关如何提高消费者满意度和获得竞争优势的数据。文本挖掘设备,如 IBM 文本分析。
GATE 有助于做出有关组织的决策,该组织会发出有关良好和不良绩效的警报,这是一种有助于采取必要行动的市场转换。这种挖掘可用于电信部门、商业、客户链管理系统。
文本挖掘中的问题
在文本挖掘过程中发生了许多问题:
1.决策的效率和效果。
2.不确定性问题可能出现在文本挖掘的中间阶段。在预处理阶段,特征化不同的规则和指南来规范化文本,从而使文本挖掘过程高效。在对文档应用模式分析之前,需要将非结构化数据转换为中等结构。
3.有时可能会因改动而改变原始信息或含义。
4.文本挖掘的另一个问题是许多算法和技术支持多语言文本。它可能会造成文本含义的歧义。这个问题会导致假阳性结果。
5.在文档文本中使用同义词、多义词和反义词给在类似设置中使用两者的文本挖掘工具带来问题。很难对此类文本/单词进行分类。