📌 相关文章
- 编译器设计中的解析器类型(1)
- 编译器设计中的解析器类型(1)
- 编译器设计中的解析器类型
- 编译器设计中的解析器类型
- 编译器设计中的预测解析器
- 编译器设计中的预测解析器(1)
- 编译器设计-自上而下的解析器
- 编译器设计-自上而下的解析器(1)
- Python中的编译器设计 LL(1) 解析器
- Python中的编译器设计 LL(1) 解析器(1)
- 自下而上的方法 (1)
- 自下而上或 Shift Reduce 解析器 | 2套
- 自下而上或 Shift Reduce 解析器 | 2套(1)
- 使用Python的编译器设计 SLR(1) 解析器
- 自下而上的测试(1)
- 自下而上的测试
- 编译器设计中的增量编译器
- 编译器设计中的增量编译器(1)
- 编译器设计中的增量编译器(1)
- 编译器设计中的增量编译器
- 自下而上的方法 - 无论代码示例
- 编译器设计教程
- 编译器设计教程(1)
- 编译器设计-正则表达式
- 编译器设计-正则表达式(1)
- 讨论编译器设计
- 编译器设计中的解析树
- 编译器设计中的解析树
- 编译器设计中的解析树
📜 编译器设计-自下而上的解析器
📅 最后修改于: 2021-01-18 05:26:59 🧑 作者: Mango
自下而上的解析从树的叶节点开始,并向上进行直到到达根节点为止。在这里,我们从一个句子开始,然后以相反的方式应用生产规则,以便到达开始符号。下图显示了可用的自底向上解析器。
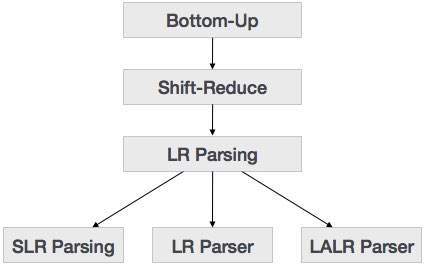
Shift-Reduce解析
Shift-Reduce解析使用两个独特的步骤进行自底向上的解析。这些步骤称为移位步骤和减少步骤。
-
移位步骤:移位步骤是指输入指针前进到下一个输入符号(称为移位符号)。该符号被压入堆栈。移位的符号被视为解析树的单个节点。
-
缩减步骤:当解析器找到完整的语法规则(RHS)并将其替换为(LHS)时,称为缩减步骤。当堆栈顶部包含一个句柄时,会发生这种情况。为了减少这种负担,将在堆栈上执行POP功能,该函数会弹出句柄并将其替换为LHS非终结符。
LR解析器
LR解析器是一种非递归,移位减少,自底向上的解析器。它使用了各种各样的上下文无关语法,这使其成为最有效的语法分析技术。 LR解析器也称为LR(k)解析器,其中L代表输入流的从左到右扫描。 R代表反向最右导数的构造,k代表进行决策的超前符号的数量。
可以使用三种广泛使用的算法来构造LR解析器:
- SLR(1)–简单的LR解析器:
- 适用于最小的语法
- 状态数很少,因此表很小
- 简单快速的施工
- LR(1)– LR解析器:
- 完成整套LR(1)语法
- 生成大表和大量状态
- 施工缓慢
- LALR(1)–前瞻性LR解析器:
- 适用于语法的中间大小
- 状态数与SLR(1)中的相同
LR解析算法
在这里,我们描述了LR解析器的框架算法:
token = next_token()
repeat forever
s = top of stack
if action[s, token] = “shift si” then
PUSH token
PUSH si
token = next_token()
else if action[s, token] = “reduce A::= β“ then
POP 2 * |β| symbols
s = top of stack
PUSH A
PUSH goto[s,A]
else if action[s, token] = “accept” then
return
else
error()
LL与LR
| LL | LR |
|---|---|
| Does a leftmost derivation. | Does a rightmost derivation in reverse. |
| Starts with the root nonterminal on the stack. | Ends with the root nonterminal on the stack. |
| Ends when the stack is empty. | Starts with an empty stack. |
| Uses the stack for designating what is still to be expected. | Uses the stack for designating what is already seen. |
| Builds the parse tree top-down. | Builds the parse tree bottom-up. |
| Continuously pops a nonterminal off the stack, and pushes the corresponding right hand side. | Tries to recognize a right hand side on the stack, pops it, and pushes the corresponding nonterminal. |
| Expands the non-terminals. | Reduces the non-terminals. |
| Reads the terminals when it pops one off the stack. | Reads the terminals while it pushes them on the stack. |
| Pre-order traversal of the parse tree. | Post-order traversal of the parse tree. |