- 编译器设计中的解析器类型
- 编译器设计中的解析器类型
- 编译器设计中的解析器类型(1)
- 编译器设计中的解析器类型(1)
- 自上而下的解析器的工作
- 自上而下的解析器的工作(1)
- 自上而下的解析器的工作
- 自上而下的解析器的工作(1)
- 自上而下解析器的分类(1)
- 自上而下解析器的分类
- 编译器设计中的预测解析器(1)
- 编译器设计中的预测解析器
- 编译器设计-自下而上的解析器(1)
- 编译器设计-自下而上的解析器
- Python中的编译器设计 LL(1) 解析器
- Python中的编译器设计 LL(1) 解析器(1)
- 使用Python的编译器设计 SLR(1) 解析器
- 自上而下的方法 (1)
- 自上而下的方法 (1)
- 编译器设计中的增量编译器
- 编译器设计中的增量编译器
- 编译器设计中的增量编译器(1)
- 编译器设计中的增量编译器(1)
- 编译器设计教程(1)
- 编译器设计教程
- 编译器设计-正则表达式(1)
- 编译器设计-正则表达式
- 自上而下的方法 - 任何代码示例
- 自上而下的方法 - 任何代码示例
📅 最后修改于: 2021-01-18 05:26:36 🧑 作者: Mango
在上一章中我们已经了解到,自顶向下的解析技术将解析输入,并开始从根节点逐渐向下移动到叶节点构建解析树。自上而下的解析类型如下所示:
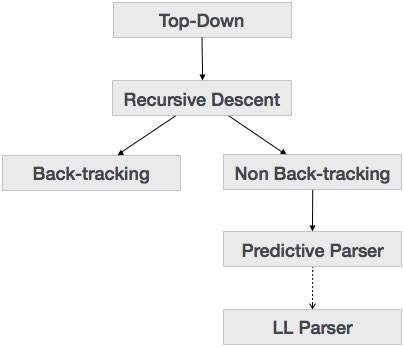
递归下降解析
递归下降是一种自上而下的解析技术,可从顶部构造解析树,并从左向右读取输入。它对每个终端和非终端实体使用过程。此解析技术以递归方式解析输入以生成解析树,该解析树可能需要也可能不需要回溯。但是与之相关的语法(如果不加以考虑的话)不能避免回溯。不需要任何回溯的递归下降解析形式称为预测解析。
这种解析技术被认为是递归的,因为它使用本质上是递归的无上下文语法。
回溯
自上而下的解析器从根节点(起始符号)开始,并根据生产规则匹配输入字符串以替换它们(如果匹配)。要了解这一点,请使用以下CFG示例:
S → rXd | rZd
X → oa | ea
Z → ai
对于输入字符串:read,自上而下的解析器将具有以下行为:
根据生产规则,它将以S开头,并将其收益与输入的最左字母匹配,即“ r”。 S的乘积(S→rXd)与之匹配。因此,自上而下的解析器将前进到下一个输入字母(即“ e”)。解析器尝试扩展非终结符“ X”并从左侧检查其产生(X→oa)。它与下一个输入符号不匹配。因此,自上而下的解析器将回溯以获得X的下一个生成规则(X→ea)。
现在,解析器以有序方式匹配所有输入字母。该字符串被接受。
|
|
|
|
|
预测解析器
预测解析器是递归下降解析器,它具有预测要使用哪个生产替换输入字符串。预测解析器不会遭受回溯。
为了完成其任务,预测分析器使用一个前向指针,该指针指向下一个输入符号。为了使解析器自由回溯,预测解析器对语法施加了一些约束,并且仅接受称为LL(k)语法的一类语法。
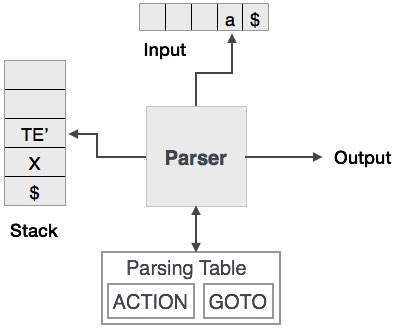
预测解析使用堆栈和解析表来解析输入并生成解析树。堆栈和输入都包含一个结束符号$,以表示堆栈为空并且消耗了输入。解析器引用解析表对输入和堆栈元素组合做出任何决定。
在递归下降解析中,对于单个输入实例,解析器可能有多个生产可供选择,而在预测解析器中,每个步骤最多只能选择一个生产。在某些情况下,可能没有与输入字符串匹配的产品,从而使解析过程失败。
LL解析器
LL解析器接受LL语法。 LL语法是上下文无关语法的子集,但为了获得易于实现的版本而有一些限制,无法获得简化版本。 LL语法可以通过两种算法来实现,即递归下降或表驱动。
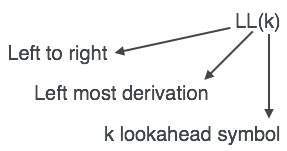
LL解析器表示为LL(k)。 LL(k)中的第一个L从左到右解析输入,LL(k)中的第二个L代表最左边的导数,k本身代表向前看的次数。通常k = 1,因此LL(k)也可以写为LL(1)。
LL解析算法
随着表的大小随k的值呈指数增长,我们可能会坚持使用确定性LL(1)进行解析器解释。其次,如果给定的语法不是LL(1),那么对于任何给定的k,通常不是LL(k)。
下面给出了LL(1)解析的算法:
Input:
string ω
parsing table M for grammar G
Output:
If ω is in L(G) then left-most derivation of ω,
error otherwise.
Initial State : $S on stack (with S being start symbol)
ω$ in the input buffer
SET ip to point the first symbol of ω$.
repeat
let X be the top stack symbol and a the symbol pointed by ip.
if X∈ Vt or $
if X = a
POP X and advance ip.
else
error()
endif
else /* X is non-terminal */
if M[X,a] = X → Y1, Y2,... Yk
POP X
PUSH Yk, Yk-1,... Y1 /* Y1 on top */
Output the production X → Y1, Y2,... Yk
else
error()
endif
endif
until X = $ /* empty stack */
如果A→α| ||,则语法G为LL(1)。 β是G的两个不同产生:
-
对于没有终端,α和β都派生以a开头的字符串。
-
α和β最多可以导出空字符串。
-
如果β→t,则α不会从FOLLOW(A)中的终端开始导出任何字符串。