在此,我们将介绍 Predictive Parser 的概述,并主要关注 Predictive Parser 的作用。并且还将介绍实现预测解析器算法的算法,最后将讨论一个通过实现优先解析算法的示例。让我们一一讨论。

预测解析器:
预测解析器是没有回溯或备份的递归下降解析器。它是一个自顶向下的解析器,不需要回溯。在每一步,要扩展的规则的选择是在下一个终端符号上进行的。
考虑
A -> A1 | A2 | ... | An如果非终结符要进一步扩展为’A’,则仅根据当前输入符号’a’选择规则。
预测解析器算法:
- 为每个语法规则制作一个转换图(DFA/NFA)。
- 通过减少状态数量来优化 DFA,产生最终的转换图。
- 模拟转换图上的字符串解析字符串。
- 如果转换图在输入被消耗后达到接受状态,则对其进行解析。
考虑以下语法——
E->E+T|T
T->T*F|F
F->(E)|id去除左递归后,左分解
E->TT'
T'->+TT'|ε
T->FT''
T''->*FT''|ε
F->(E)|id第1步:
为每个语法规则制作一个转换图(DFA/NFA)。
- E->TT’

- T’->+TT’|ε
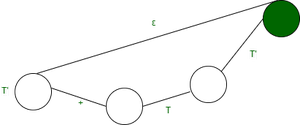
- T->FT”

- T”->*FT”|ε
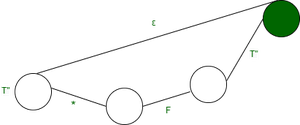
- F->(E)|id

第2步:
通过减少状态数量来优化 DFA,从而产生最终的转换图。
- T’->+TT’|ε

可以通过将其与 E->TT’ 的 DFA 结合来提前优化

因此,我们优化其他结构以产生以下 DFA
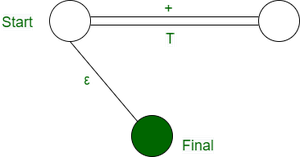
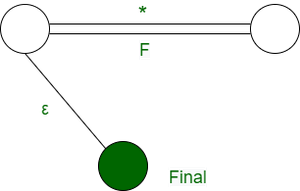
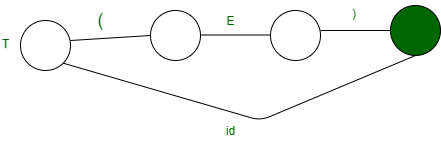
第 3 步:
对输入字符串的模拟。
模拟过程中涉及的步骤是:
- 从起始状态开始。
- 如果终端到达消费它,则移动到下一个状态。
- 如果非终端到达,则转到非终端的 DFA 状态并返回到达最终状态。
- 返回到实际的 DFA 并继续进行解析。
- 如果完全读取输入字符串,则达到最终状态,并且成功解析字符串。