毫升 |自动编码器
神经网络的一个典型用途是监督学习。它涉及包含输出标签的训练数据。神经网络试图学习从给定输入到给定输出标签的映射。但是,如果输出标签被输入向量本身替换怎么办?然后网络将尝试找到从输入到自身的映射。这将是身份函数,它是一个简单的映射。
但是如果不允许网络简单地复制输入,那么网络将被迫只捕获显着特征。这种约束为神经网络开辟了一个不同的应用领域,这是未知的。主要应用是降维和特定数据压缩。
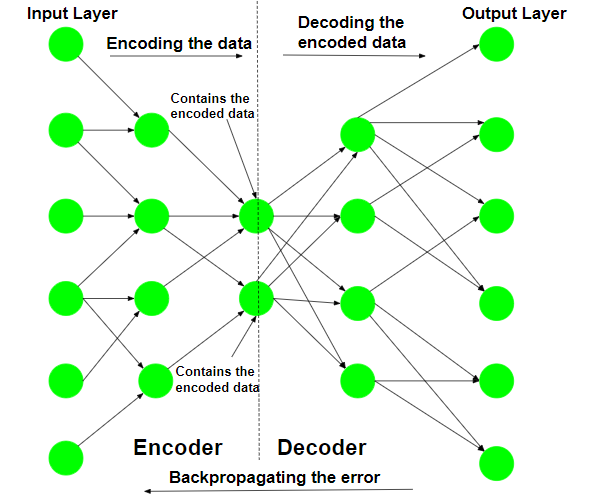
网络首先在给定的输入上进行训练。网络尝试从它拾取的特征中重建给定的输入,并将输入的近似值作为输出。训练步骤涉及误差的计算和误差的反向传播。自动编码器的典型架构类似于瓶颈。
自编码器的结构示意图如下:
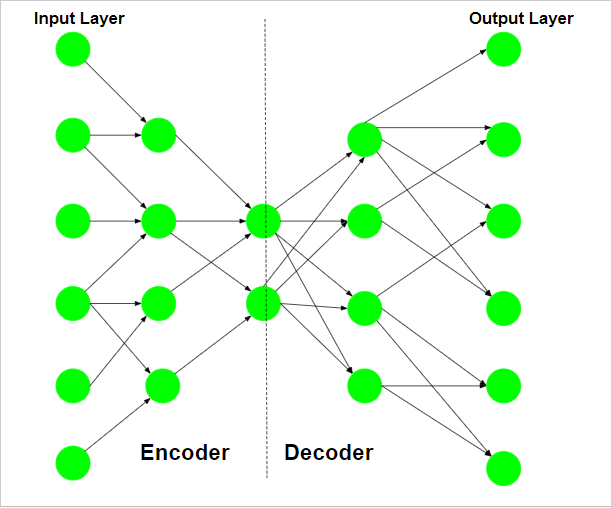
网络的编码器部分用于编码,有时甚至用于数据压缩目的,尽管与 JPEG 等其他通用压缩技术相比,它不是很有效。编码是由网络的编码器部分实现的,每层的隐藏单元数量减少。因此,这部分被迫只选择数据中最重要和最具代表性的特征。网络的后半部分执行解码函数。这部分在每一层中具有越来越多的隐藏单元,因此试图从编码数据中重建原始输入。
因此,自动编码器是一种无监督学习技术。
用于数据压缩的自动编码器的训练:对于数据压缩过程,压缩的最重要方面是压缩数据重建的可靠性。这一要求将自动编码器的结构作为瓶颈。
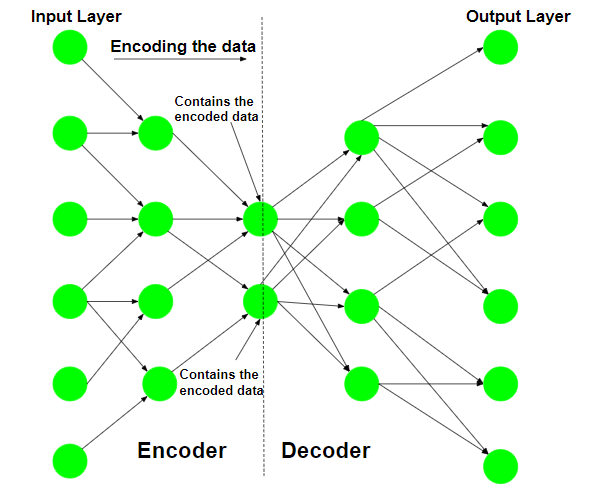
第 1 步:编码输入数据
自动编码器首先尝试使用初始化的权重和偏差对数据进行编码。
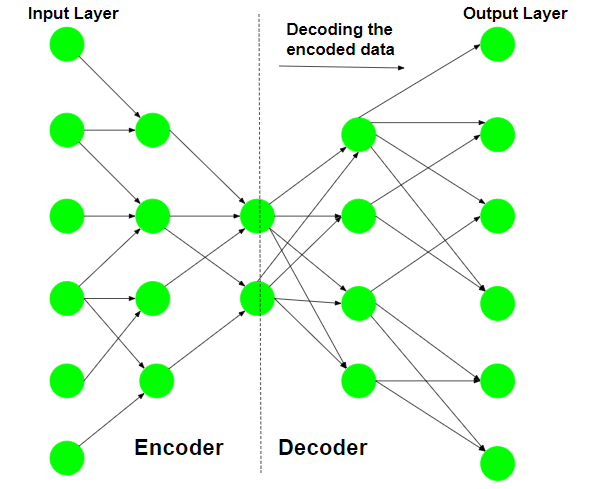
第 2 步:解码输入数据
自动编码器尝试从编码数据中重建原始输入,以测试编码的可靠性。
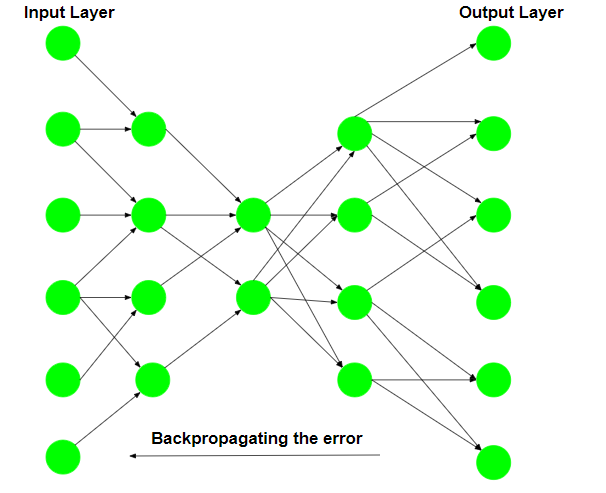
第 3 步:反向传播错误
在重建之后,计算损失函数以确定编码的可靠性。产生的错误被反向传播。
多次重复上述训练过程,直到达到可接受的重建水平。
在训练过程之后,只保留 Auto-encoder 的编码器部分,对训练过程中使用的类似类型的数据进行编码。
约束网络的不同方法是:-
- 保持较小的隐藏层:如果每个隐藏层的大小保持尽可能小,那么网络将被迫只拾取数据的代表性特征,从而对数据进行编码。
- 正则化:在这种方法中,损失项被添加到成本函数中,它鼓励网络以不同于复制输入的方式进行训练。
- 去噪:约束网络的另一种方法是在输入中添加噪声,并教网络如何从数据中去除噪声。
- 调整激活函数:该方法涉及更改各个节点的激活函数,使大多数节点处于休眠状态,从而有效地减小隐藏层的大小。
自动编码器的不同变体是:-
- 去噪自动编码器:这种类型的自动编码器适用于部分损坏的输入,并训练以恢复原始未失真的图像。如上所述,这种方法是限制网络简单复制输入的有效方法。
- 稀疏自动编码器:这种类型的自动编码器通常包含比输入更多的隐藏单元,但一次只允许少数几个处于活动状态。该属性称为网络的稀疏性。网络的稀疏性可以通过手动归零所需的隐藏单元、调整激活函数或在成本函数中添加损失项来控制。
- 变分自动编码器:这种类型的自动编码器对潜在变量的分布做出了强有力的假设,并在训练过程中使用了随机梯度变分贝叶斯估计器。它假设数据是由有向图形模型生成的,并试图学习一个近似值
 到条件属性
到条件属性 在哪里
在哪里 和
和 分别是编码器和解码器的参数。
分别是编码器和解码器的参数。