本文讨论了朴素贝叶斯分类器背后的理论及其实现。
朴素贝叶斯分类器是基于贝叶斯定理的分类算法的集合。它不是一个单一的算法,而是一系列算法,它们全部共享一个共同的原理,即,要分类的每一对特征彼此独立。
首先,让我们考虑一个数据集。
考虑一个虚构的数据集,该数据集描述了打高尔夫球的天气状况。给定天气条件,每个元组将条件分为适合普通高尔夫的条件(“是”)或不适合(“否”)。
这是我们的数据集的表格表示。
| Outlook | Temperature | Humidity | Windy | Play Golf | |
|---|---|---|---|---|---|
| 0 | Rainy | Hot | High | False | No |
| 1 | Rainy | Hot | High | True | No |
| 2 | Overcast | Hot | High | False | Yes |
| 3 | Sunny | Mild | High | False | Yes |
| 4 | Sunny | Cool | Normal | False | Yes |
| 5 | Sunny | Cool | Normal | True | No |
| 6 | Overcast | Cool | Normal | True | Yes |
| 7 | Rainy | Mild | High | False | No |
| 8 | Rainy | Cool | Normal | False | Yes |
| 9 | Sunny | Mild | Normal | False | Yes |
| 10 | Rainy | Mild | Normal | True | Yes |
| 11 | Overcast | Mild | High | True | Yes |
| 12 | Overcast | Hot | Normal | False | Yes |
| 13 | Sunny | Mild | High | True | No |
数据集分为特征矩阵和响应向量两部分。
- 特征矩阵包含数据集的所有向量(行),其中每个向量都包含相关特征的值。在以上数据集中,特征为“ Outlook”,“温度”,“湿度”和“风”。
- 响应向量包含特征矩阵每一行的类变量(预测或输出)的值。在上述数据集中,类变量名称为“ Play golf”。
假设:
朴素贝叶斯的基本假设是,每个功能都具有以下特征:
- 独立的
- 平等的
对结果的贡献。
关于我们的数据集,这个概念可以理解为:
- 我们假设没有一对特征是依赖的。例如,温度为“高温”与湿度无关,或者视线为“多雨”对风没有影响。因此,假定这些特征是独立的。
- 其次,每个功能都具有相同的权重(或重要性)。例如,仅了解温度和湿度并不能正确预测结果。没有任何属性是无关紧要的,并假定对结果有同等的贡献。
注意:朴素贝叶斯(Naive Bayes)所做的假设在现实世界中通常是不正确的。实际上,独立性假设永远是不正确的,但在实践中通常效果很好。
现在,在转向朴素贝叶斯公式之前,了解贝叶斯定理很重要。
贝叶斯定理
给定已经发生的另一事件的概率,贝叶斯定理找到事件发生的概率。贝叶斯定理在数学上由以下等式表示:
![]()
其中A和B是事件,而P(B)是? 0。
- 基本上,鉴于事件B为真,我们试图找到事件A的概率。事件B也被称为证据。
- P(A)是A的先验(先验概率,即在看到证据之前发生事件的概率)。证据是未知实例的属性值(这里是事件B)。
- P(A | B)是B的后验概率,即看到证据后发生事件的概率。
现在,关于我们的数据集,我们可以通过以下方式应用贝叶斯定理:
![]()
其中,y是类变量,X是从属特征向量(大小为n ),其中:
![]()
为了清楚起见,特征向量和相应的类变量的示例可以是:(请参阅数据集的第一行)
X = (Rainy, Hot, High, False)
y = No
因此,基本上,P(y | X)表示在天气条件为“多雨前景”,“温度高”,“高湿度”和“无风”的情况下“不打高尔夫球”的概率。
天真的假设
现在,是时候对贝叶斯定理做出天真的假设了,即特征之间的独立性。因此,现在,我们将证据分为独立的部分。
现在,如果事件A和B中的任何两个是独立的,那么,
P(A,B) = P(A)P(B)
因此,我们得出的结果是:
![]()
可以表示为:
![]()
现在,由于分母对于给定的输入保持不变,因此我们可以删除该术语:
![]()
现在,我们需要创建一个分类器模型。为此,我们找到类别变量y的所有可能值的给定输入集的概率,并以最大概率提取输出。这可以用数学表示为:
![]()
因此,最后,剩下的工作是计算P(y)和P(x i | y)。
请注意,P(y)也称为类别概率,P(x i | y)也称为条件概率。
不同的朴素贝叶斯分类器的主要区别在于它们对P(x i | y)的分布所做的假设。
让我们尝试将上述公式手动应用于天气数据集。为此,我们需要对数据集进行一些预计算。
我们需要为X中的每个x i和y中的y j找到P(x i | y j )。下表列出了所有这些计算:
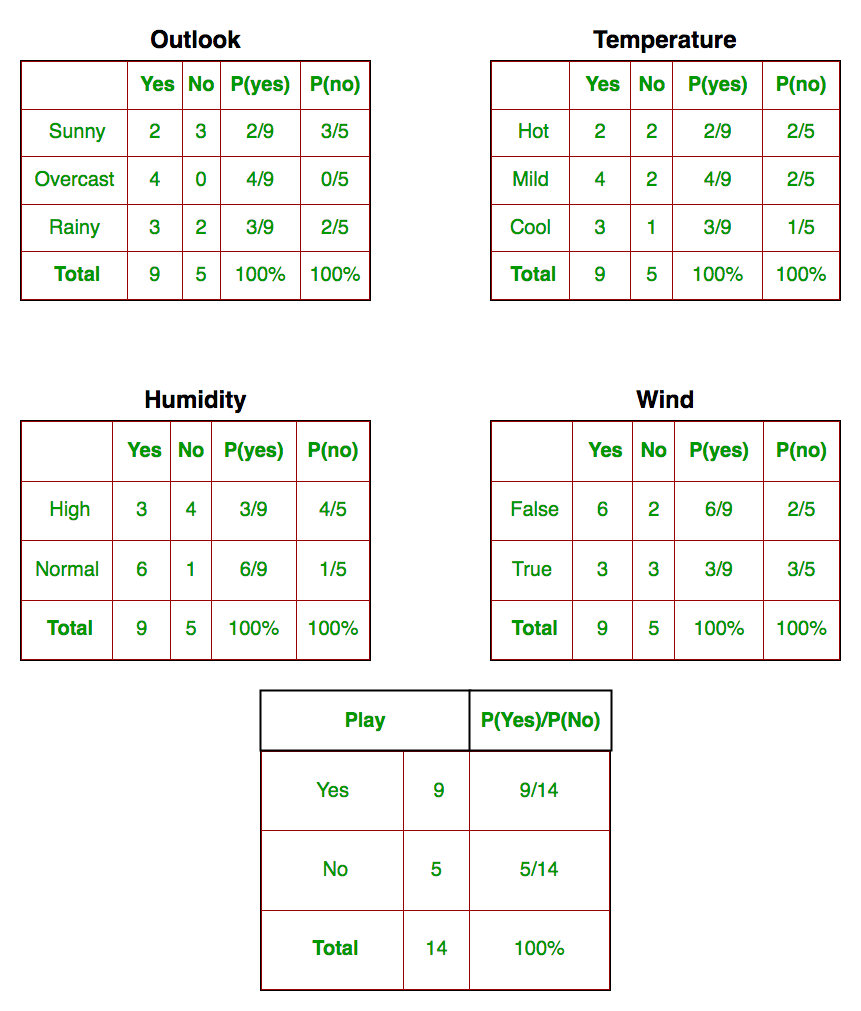
因此,在上图中,我们已在表1-4中为X中的每个x i和y中的y j手动计算了P(x i | y j)。例如,假设温度凉爽,打高尔夫球的概率,即P(温度=凉|打高尔夫球=是)= 3/9。
另外,我们需要找到已在表5中计算出的类别概率(P(y))。例如,P(打高尔夫球=是)= 9/14。
现在,我们完成了预计算,分类器已准备就绪!
让我们在一组新功能上对其进行测试(今天让我们称呼它):
today = (Sunny, Hot, Normal, False)
因此,打高尔夫球的概率由下式给出:
![]()
不打高尔夫的概率由下式给出:
![]()
由于P(today)在两个概率中都是通用的,因此我们可以忽略P(today)并按如下方式找到比例概率:
![]()
和
![]()
现在,因为
![]()
通过使总和等于1(归一化),可以将这些数字转换为概率:
![]()
和
![]()
自从
![]()
因此,将要打高尔夫球的预测是“是”。
我们上面讨论的方法适用于离散数据。在连续数据的情况下,我们需要对每个要素的值的分布进行一些假设。不同的朴素贝叶斯分类器的主要区别在于它们对P(x i | y)的分布所做的假设。
现在,我们在这里讨论这样的分类器之一。
高斯朴素贝叶斯分类器
在高斯朴素贝叶斯中,与每个特征相关的连续值被假定为根据高斯分布进行分布。高斯分布也称为正态分布。绘制时,它给出了一个钟形曲线,该曲线关于特征值的平均值对称,如下所示:
假定特征的似然性是高斯的,因此条件概率由下式给出:

现在,我们看一下使用scikit-learn的高斯朴素贝叶斯分类器的实现。
# load the iris dataset
from sklearn.datasets import load_iris
iris = load_iris()
# store the feature matrix (X) and response vector (y)
X = iris.data
y = iris.target
# splitting X and y into training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)
# training the model on training set
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(X_train, y_train)
# making predictions on the testing set
y_pred = gnb.predict(X_test)
# comparing actual response values (y_test) with predicted response values (y_pred)
from sklearn import metrics
print("Gaussian Naive Bayes model accuracy(in %):", metrics.accuracy_score(y_test, y_pred)*100)
输出:
Gaussian Naive Bayes model accuracy(in %): 95.0其他流行的朴素贝叶斯分类器是:
- 多项式朴素贝叶斯:特征向量表示通过多项式分布生成某些事件的频率。这是通常用于文档分类的事件模型。
- Bernoulli Naive Bayes :在多元Bernoulli事件模型中,特征是描述输入的独立布尔值(二进制变量)。像多项模型一样,该模型在文档分类任务中也很流行,其中使用了二进制术语出现(即单词是否出现在文档中)特征,而不是术语频率(即文档中单词的出现频率)。
当我们到达本文的结尾时,需要考虑以下一些重要点:
- 尽管它们的假设显然过分简化,但朴素的贝叶斯分类器在许多实际情况下(尤其是文档分类和垃圾邮件过滤)都表现良好。他们需要少量的训练数据来估计必要的参数。
- 与更复杂的方法相比,朴素贝叶斯学习者和分类器可以非常快。类条件特征分布的解耦意味着可以将每个分布独立地估计为一维分布。反过来,这有助于减轻因维数的诅咒而产生的问题。
参考:
- https://zh.wikipedia.org/wiki/朴素贝叶斯_分类器
- http://gerardnico.com/wiki/data_mining/naive_bayes
- http://scikit-learn.org/stable/modules/naive_bayes.html