用 WEKA 构建朴素贝叶斯分类器
本文演示了在 Weka 中使用朴素贝叶斯分类器。本实验中使用的“天气标称”数据集以 ARFF 格式提供。本文假设数据已经过适当的预处理。
贝叶斯定理用于构建一组称为朴素贝叶斯分类器的分类算法。它是一系列算法,它们共享一个共同的概念,即被分类的每对特征都相互独立。
应遵循的步骤:
- 最初,我们必须使用选择文件选项在 weka 工具中加载所需的数据集。在这里,我们选择要执行的天气名义数据集。
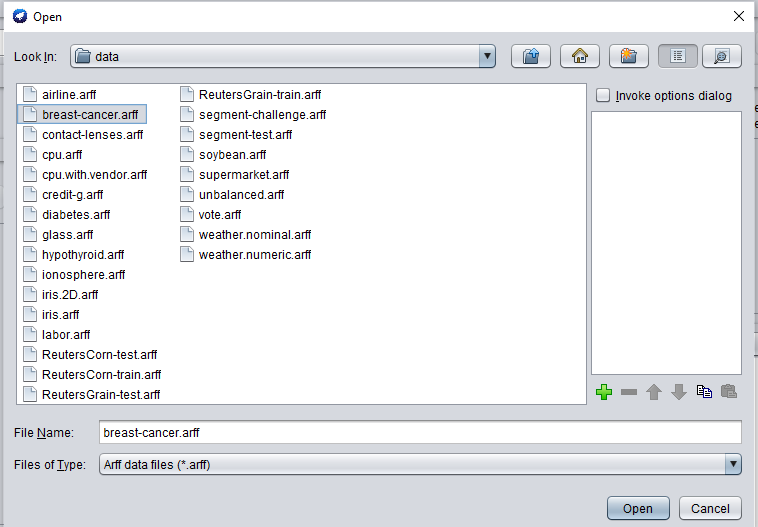
- 现在我们必须转到左上角的分类选项卡,然后单击选择按钮并在其中选择朴素贝叶斯算法。
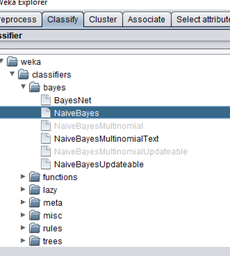
- 现在要更改参数,请单击右侧的选择按钮,我们接受本示例中的默认值。

- 我们从主面板的“测试”选项中选择百分比分割作为我们的测量方法。由于我们没有单独的测试数据集合,我们将使用 66% 的百分比拆分来很好地了解模型的准确性。我们的数据集包含 14 个示例,其中 h9 用于训练,5 个用于测试。
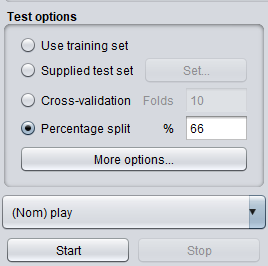
- 要生成模型,我们现在单击“开始”。模型完成后,评估统计量将出现在右侧面板中。

以下是相同的Java代码
Java
import java.io.BufferedReader;
import java.io.FileReader;
import weka.classifiers.bayes.NaiveBayes;
import weka.classifiers.Evaluation;
import weka.core.Instances;
public class WeatherNominal {
public static void main(String args[]) {
try {
// Create naivebayes classifier //
NaiveBayes naivebayes = new NaiveBayes();
// Dataset path //
String weatherNominalDataset = "/home/droid/Tools/weka-3-8-5/data/weather.nominal.arff";
// Create bufferedreader to read the dataset //
BufferedReader bufferedReader = new BufferedReader(new FileReader(weatherNominalDataset));
// Create dataset instances //
Instances datasetInstances = new Instances(bufferedReader);
// Randomize the dataset //
datasetInstances.randomize(new java.util.Random(0));
// Divide dataset into training and test data //
int trainingDataSize = (int) Math.round(datasetInstances.numInstances() * 0.66);
int testDataSize = (int) datasetInstances.numInstances() - trainingDataSize;
// Create training data //
Instances trainingInstances = new Instances(datasetInstances,0,trainingDataSize);
// Create test data //
Instances testInstances = new Instances(datasetInstances,trainingDataSize,testDataSize);
// Set Target class //
trainingInstances.setClassIndex(trainingInstances.numAttributes()-1);
testInstances.setClassIndex(testInstances.numAttributes()-1);
// Close BufferedReader //
bufferedReader.close();
// Build Classifier //
naivebayes.buildClassifier(trainingInstances);
// Evaluation //
Evaluation evaluation = new Evaluation(trainingInstances);
evaluation.evaluateModel(naivebayes,testInstances);
System.out.println(evaluation.toSummaryString("\nResults",false));
}
catch (Exception e) {
System.out.println("Error Occured!!!! \n" + e.getMessage());
}
}
}您可以通过键入以下命令来运行该程序
$ javac -cp /weka-3-8-5/weka.jar WeatherNominal.Java
$ Java -cp .:/weka-3-8-5/weka.jar WeatherNominal
注意:'/weka-3-8-5/weka.jar'是weka jar的路径,可以在weka的安装文件中找到
值得注意的是,该模型的分类准确率约为 60%。这表明我们将能够通过执行一些修改来优化准确性。 (无论是在预处理中还是在现有分类参数的选择中)
此外,为了识别新实例,我们可以使用我们自己的模型。单击主面板“测试选项”中的“提供的测试包”单选按钮,然后单击“设置”按钮。
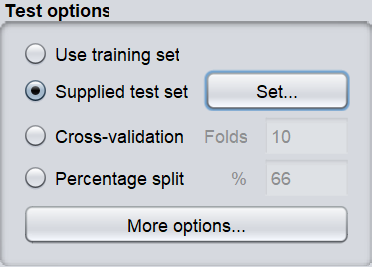
这将打开一个弹出窗口,允许我们打开测试实例文件。它可以通过使用不同的测试集来进一步提高模块的准确性。